Go 小工具 - CLI 版 Token 計數器
| | | 0 | |
陸續寫了不少用 PowerShell 整合 Azure OpenAI API 的小工具,現在想叫 GPT 工具人翻譯文章整理摘要,或是用 Whisper 轉逐字稿都方便許多,但還缺了一項功能 - 計算 Token 數。
掌握 Token 數對長文字分段處理很重要,LLM 的提示與回應長度都有上限,以 GPT-4 為例,輸入的 Prompt 不可超過 128K,輸出最多 16K,沒掌握好有時內容被去尾都不自知。(早期 gpt-4o 輸出只有 4K,我有踩過雷)
計算 Token 數的方法很多,OpenAI 有 tiktoken 程式庫,Python/C#/Java/JS/PHP 版本都有,我玩過 .NET 版 SharpToken,後來還有一些速度更快的實作版本。不過這回我不想用 .NET 做,前陣子剛復習過 Go 入門教學,加上幾天前傳來 TypeScript 用 Go 改寫編譯器速度快十倍的消息,讓我決定打鐵趁熱,就用 Go 寫個計算 Token 數的 CLI 小工具當成實戰練習。
Go 已算一線程式語言,相關資源豐富,計算 Token 開源程式庫有很多套,如:pkoukk/tiktoken-go、shapor/tiktoken-go、tiktoken-go/tokenizer。評估後我選擇 tiktoken-go/tokenizer,理由是它將字典直接轉成了 Go 的 Dictionary 型別,省去下載字典及載入的功夫,雖然程式變大 4MB 左右,但我覺得值得。
以下是我的開發過程記錄,有興趣的同學可以照著玩一遍。
- 建立 tikcount 目錄
mkdir tikcount - 撰寫主程式 main.go (CLI 參數有內建 flag 套件支援,寫起來挺簡潔好讀)
package main import ( "flag" "fmt" "io" "os" "github.com/tiktoken-go/tokenizer" ) func main() { // Define command-line flags for flexibility help := flag.Bool("h", false, "Help") filePath := flag.String("f", "", "Path to the input file (optional)") encoding := flag.String("e", "o200k_base", "Select encoding (default: o200k_base)") verbose := flag.Bool("v", false, "Print detailed token information") flag.Parse() if *help { fmt.Println("Usage: CountToken [-f filepath] [-e encoding] [-v]") fmt.Println(" -h Help") fmt.Println(" -f filepath Path to the input file (optional)") fmt.Println(" -e encoding Select encoding (default: o200k_base)") fmt.Println(" -v Print detailed token information") return } var input string if *filePath != "" { // Read input from the specified file bytes, err := os.ReadFile(*filePath) if err != nil { fmt.Fprintf(os.Stderr, "Error reading from file: %v\n", err) os.Exit(1) } input = string(bytes) } else { // Read all input from stdin bytes, err := io.ReadAll(os.Stdin) if err != nil { fmt.Fprintf(os.Stderr, "Error reading from stdin: %v\n", err) os.Exit(1) } input = string(bytes) } // Get the selected encoding enc, err := tokenizer.Get(tokenizer.Encoding(*encoding)) if err != nil { fmt.Fprintf(os.Stderr, "Error getting encoding: %v\n", err) os.Exit(1) } // Encode the input text and count tokens tokens, _, _ := enc.Encode(input) // Output the token count if *verbose { fmt.Printf("Text length: %d characters\n", len(input)) fmt.Printf("Token count: %d tokens\n", len(tokens)) } else { fmt.Println(len(tokens)) } } - 建立 go.mod 並設定程式庫
`go mod tidy' 調整完的 go.mod 內容如下:go mod init github.com/darkthread/tikcount go mod tidy # 自動掃描 main.go 加入所需程式庫,移除不用的程式庫module github.com/darkthread/tikcount go 1.24.1 require github.com/tiktoken-go/tokenizer v0.6.0 require github.com/dlclark/regexp2 v1.11.5 // indirect - 編譯執行檔
go build -o tikcount.exe main.go
實測使用 Pipeline 串接、使用 cl100k_base 分詞(GPT 3.5/4 適用)、直接讀取檔案都得到正確結果,大成功!
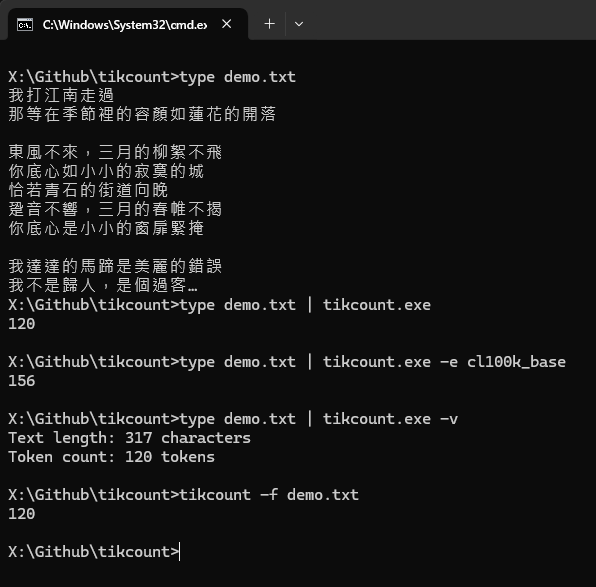
與網頁版 Tokenizer 驗證二者結果相同。
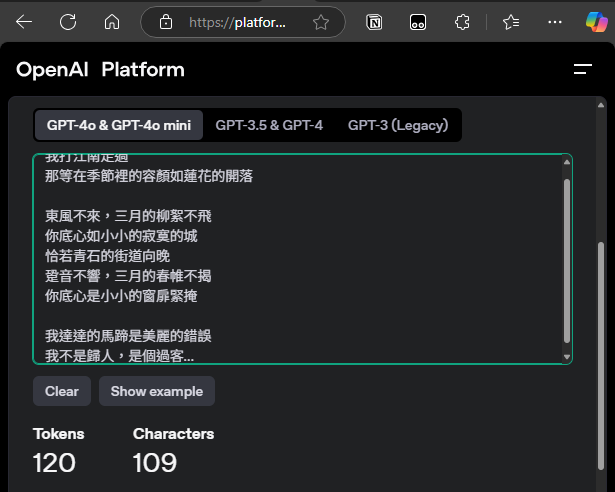
執行檔大小約 14MB,不需 Runtime 或 DLL,一檔搞定,跟 PowerShell 整合也沒有任何問題。
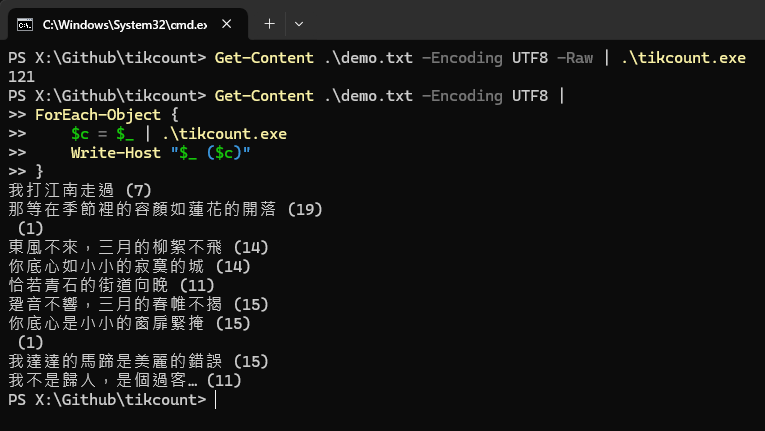
註:以上在 PowerShell 7.X 可直接跑,若是 PowerShell 5.1 記得要先執行 $OutputEncoding = New-Object System.Text.UTF8Encoding $false 設定輸出無 BOM 的 UTF-8 內容結果才會正確。參考:$OutputEncoding to the rescue
就醬,我的小工具開發語言再添生力軍。
Comments
Be the first to post a comment