文字轉 ChatGPT Token 之實驗與觀察
| | | 0 | |
使用 ChatGPT API 時,掌握提問內容 Token 數很重要。
ChatGPT API 處理 Prompt 時不是以字元或字詞為單位,而是會把文字拆解為一個個 Token。Token 不一定從單詞 (Word) 開頭或結尾處分割,並可以包括尾隨空格甚至是子詞 (Sub-Words),OpenAI 有一份文字長度對映 Token 數量的粗估:
- 1 個 Token ~= 英文中的 4 個字元
- 1 個 Token ~= ¾個單詞
- 100 個 Token ~= 75個單詞
或者
- 1-2句 ~= 30 個 Token
- 1 段落 ~= 100 個 Token
- 1,500 單詞 ~= 2048 個 Token
細節可以看 Open AI 這篇文章:What are tokens and how to count them?
開發 ChatGPT 應用程式之所以在意 Token 數,原因有二:第一,不同模型可接受 Prompt + Completion 的 Token 數量上限不同,送出前先試算可在超過上限時做前置處理;第二則是 ChatGPT API 是依據 Prompt 及 Completion (生成結果) 的 Token 數量計費,知道 Token 數有助於估算成本。(下圖為 Azure Open AI 的 Prompt Token 上限及計費標準:

自動完成(Completion) API 在傳回結果會一併帶回三個使用量數據 prompt_tokens、completion_tokens、total_tokens:參考
"usage": {
"type": "object",
"properties": {
"completion_tokens": {
"type": "number",
"format": "int32"
},
"prompt_tokens": {
"type": "number",
"format": "int32"
},
"total_tokens": {
"type": "number",
"format": "int32"
}
},
"required": [
"prompt_tokens",
"total_tokens",
"completion_tokens"
]
}
但這些要執行完才會知道,想事先估算,OpenAI 有提供一個線上介面 - Tokenizer 以及 Python 程式庫 - tiktoken,程式庫也有被移植成 C#、Java、JavaScript、PHP 版本。參考
以 .NET 為例,要分析 gpt-4、gpt-3.5-turbo 的 Token 數(二者都是用 cl100k_base 編碼詞表),可使用 SharpToken 程式庫,用 dotnet add package SharpToken 安裝,建立 Encoding 物件,用 Encode() 將字串轉為 Token 陣列,用 Decode() 還原,沒什麼難度。
using SharpToken;
var encoding = GptEncoding.GetEncodingForModel("gpt-4");
var encoded = encoding.Encode("Hello, world!"); // Output: [9906, 11, 1917, 0]
var decoded = encoding.Decode(encoded); // Output: "Hello, world!"
先來個簡單測試,將英文、中文、日文、匈牙利文轉成 Token,並試著還原回原始字詞,觀察 Token 與字詞的對應內容:
using System.Text;
using SharpToken;
var encoding = GptEncoding.GetEncodingForModel("gpt-4");
Action<string> showTokens = (input) =>
{
var tokens = encoding.Encode(input);
var queue = new List<int>();
tokens.ForEach(t =>
{
queue.Add(t);
var tryDecode = encoding.Decode(queue);
if (tryDecode != "�")
{
Console.Write($"\x1b[33m{tryDecode}(\x1b[36m{string.Join(",", queue.Select(o => o.ToString()).ToArray())}\x1b[0m)");
queue.Clear();
}
});
Console.WriteLine();
Console.WriteLine("Tokens Count: " + tokens.Count);
};
showTokens("To be, or not to be, that is the question.");
showTokens("The class library annotated with UnmanagedCallersOnlyAttribute with a non-null EntryPoint field.");
showTokens("我達達的馬蹄是美麗的錯誤");
showTokens("逃げるは恥だが役に立つ");
showTokens("Szégyen a futás, de hasznos");
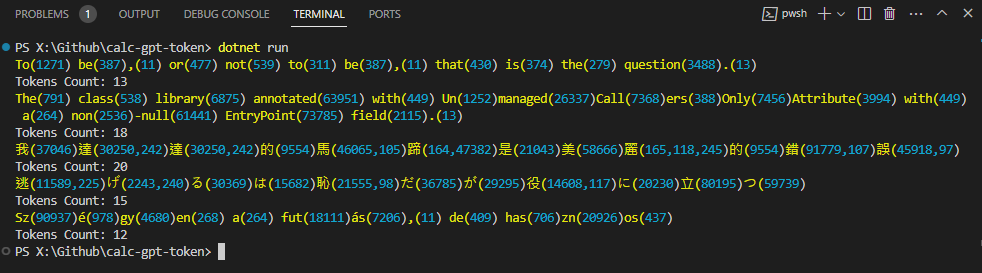
英文幾乎可以做到一個 Word 對映一個 Token,有些常用的片段也會有對映,像是 -null(61441)、ers(388)。中文的話,常用字如我(37046)、的(9554)、是(21043)、美(58666)為單字一個 Token,大部分一個中文字會解成兩到三個 Token。 日文的部分平假名片假名是一對一,漢字比照中文會用到 2 ~ 3 個 Token。匈牙利文則是單字會拆成多節,像是 Szégyen 就分成 Sz、é、gy、en 共四個 Token。
最後來實測一下 SharpToken 估算結果是否與 ChatGPT API 的統計一致。(程式碼修改自ChatGPT 聊天程式練習)
public async Task<string> Generate(IEnumerable<ChatRecord> contextMessags)
{
var chatMessages = new List<ChatMessage>() {
new ChatMessage(ChatRole.System, SystemPrompt)
};
chatMessages.AddRange(contextMessags.Select(m => new ChatMessage(
m.Role == "A" ? ChatRole.Assistant : ChatRole.User,
m.Message
)));
Response<ChatCompletions> response = await client.GetChatCompletionsAsync(
deploymentOrModelName: DeployName,
new ChatCompletionsOptions(chatMessages)
{
Temperature = Temperature,
MaxTokens = MaxTokens,
NucleusSamplingFactor = NucleusSamplingFactor,
FrequencyPenalty = FrequencyPenalty,
PresencePenalty = PresencePenalty
});
ChatCompletions completions = response.Value;
var result = completions.Choices.First().Message.Content;
var encoding = GptEncoding.GetEncodingForModel("gpt-4");
var promptMsg = string.Join(string.Empty, chatMessages.Select(m => $"role={m.Role.ToString()} content={m.Content}\n").ToArray());
var promptTokens = encoding.Encode(promptMsg);
var reslutTokens = encoding.Encode(result);
Console.ForegroundColor = ConsoleColor.Yellow;
Console.WriteLine(promptMsg);
var stats = @$"
Est Tokens: {promptTokens.Count}|{reslutTokens.Count}|{promptTokens.Count + reslutTokens.Count}
Act Tokens: {completions.Usage.PromptTokens}|{completions.Usage.CompletionTokens}|{completions.Usage.TotalTokens}";
Console.ForegroundColor = ConsoleColor.Cyan;
Console.WriteLine(stats);
Console.WriteLine();
Console.ResetColor();
return result;
}
/* ... 略 ... */
var gpt = new ChatGptService();
var response = await gpt.Generate(@"請將以下內容翻譯成zh-tw:
逃げるは恥だが役に立つ");
Console.WriteLine(response);
response = await gpt.Generate(@"指出以下程式碼的錯誤
```js
for (var i = 0; i < 10; i--) {
Console.WriteLine(i);
}
``
");
Console.WriteLine(response);
GetChatCompletionsAsync() 會傳入多組聊天記錄,在 REST API 是用 JSON [{ "role": "system", "content": "..." }, { ... }] 形式傳送,但實測用 JSON 估算 Prompt Token 數偏多,我測試 "role=system content=...\n" 格式較接近 API 回傳的數字,箭頭所指的三個數字分別為 Prompt、Completion、Prompt+Completion Token 數,SharpToken 的預測結果與 API 回傳值幾乎一致。
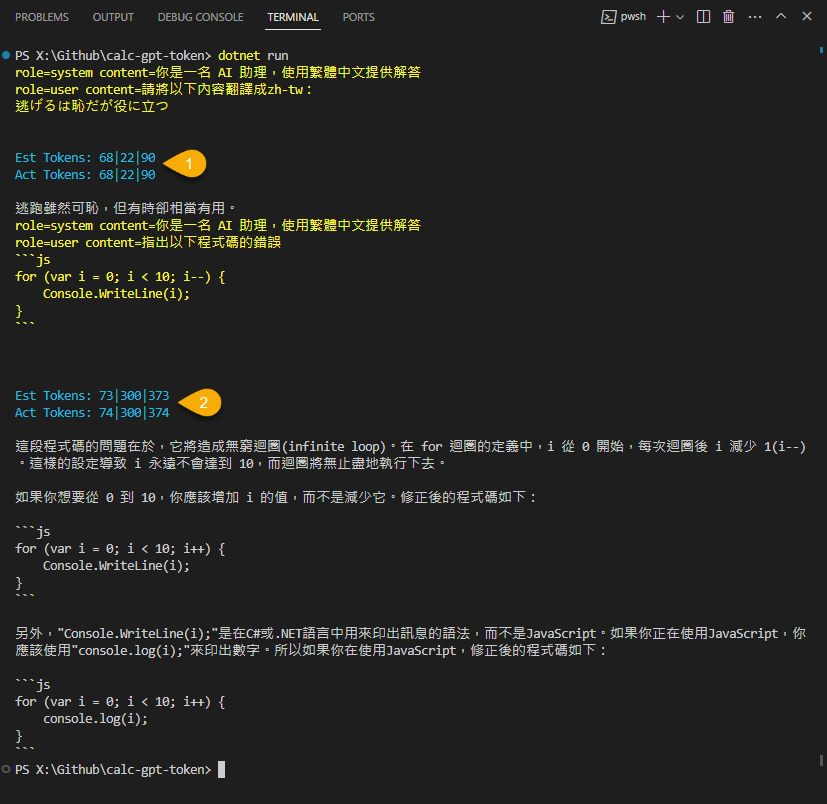
掌握了這個技巧,未來處理冗長 Prompt 便能事先判斷是否會超過上限以及估算成本囉。
Example of using SharpToken to encode text as tokens.
Comments
Be the first to post a comment