詭異的 XDocument XML 讀取錯誤
 |  | 5 |  |  |
被一個 XML 讀取問題卡住大半天,寫篇筆記留念。
我有個 Coding4Fun 電子書製作工具,將 XHTML 範本檔案內嵌成資源(Embedded Resource),再用 GetEmbResString() 讀取範本 XML 交給 XDocument.Parse() 轉成 XML 物件操作:
static string GetEmbResString(string name) =>
Encoding.UTF8.GetString(GetEmbResBytes(name));
static byte[] GetEmbResBytes(string name)
{
using (var ms = new MemoryStream())
{
GetEmbResStream(name).CopyTo(ms);
return ms.ToArray();
}
}
static Stream GetEmbResStream(string name) =>
typeof(EPubMaker).Assembly.GetManifestResourceStream(
typeof(EPubMaker).FullName.Replace(nameof(EPubMaker), "Templates." + name));
//... 讀取 XML 範本轉為 XDocument ...
var template = GetEmbString("template.html");
XDocument.Parse(template);
該 XML 範本在其他地方有用過,內容、格式應該都符合規範。不料,系統噴出 System.Xml.XmlException: 'Data at the root level is invalid. Line 1, position 1.' 錯誤!
有趣的是,我如果換個寫法,改取 Stream 再配合 XDocument.Load 就過關了:
var template = GetEmbResStream("template.html");
XDocument.Load(template);
經過一番研究,我終於搞懂是怎麼一回事了(結論是自己學藝不精、江湖經驗不足),並知道怎麼重現它:
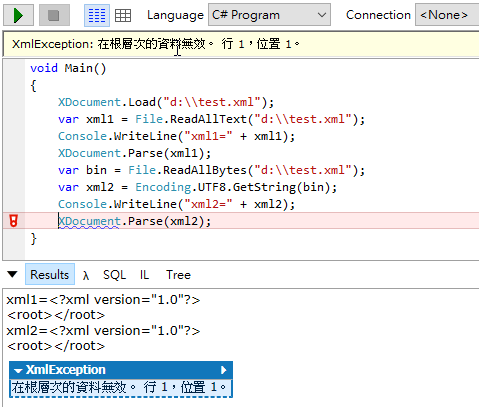
如以上範例,我做了一個超簡單的 XML 檔案,跑 XDocument.Load(XML檔)、XDocument.Parse(File.ReadAllText(XML檔)) 都沒問題;但如果先 File.ReadAllBytes(XML檔) 讀成 byte[] 再 Encoding.UTF8.GetString() 轉字串餵給 XDocument.Parse(),便會重現"在根層次的資料無效。行1,位置1。"錯誤。
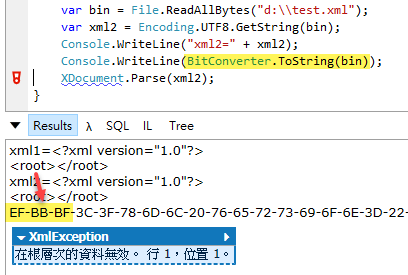
聰明的你,想到是什麼原因了嗎?
Yes,UTF8 BOM!
用 BitConverter.ToString(byte[]) 檢視 ReadAllBytes() 讀取的二進位內容,果然在最前方看到 EF BB BF (UTF8 BOM),File.ReadAllText()、XDocument.Load() 這些處理檔案的函式都認得 BOM,而我的程式傻傻地讓它變成字串內容,引發錯誤。
再學到一些實戰經驗。
A case of UTF-8 BOM issue while processing XML with XDocument.Parse().
Comments
# by 阿光
今天遇到用XDocument.Load會出現 要求已經中止: 無法建立 SSL/TLS 的安全通道的問題
# by Jeffrey
to 阿光,是 .NET 3.5/4/4.5 程式嗎?最常見原因是 TLS 1.2 設定,請參考這篇第 4 點 https://blog.darkthread.net/blog/disable-tls-1-0-issues/ 簡單測試方法 - 同樣程式若改用 .NET 4.6+ 不會出錯,即可確認是 TLS 1.2 問題。
# by 阿光
謝謝黑暗大大的回覆。 是.Net 4.7.2版本,嘗試很多方式都不行,唯獨用了RestSharp套件可以。 但是在XDocument.Parse會出現System.Xml.XmlException: 遺漏根元素。
# by Jeffrey
to 阿光,用瀏覽器開一下 XML URL,看看是否憑證無效,若是停用驗證試試 ServicePointManager.ServerCertificateValidationCallback = delegate { return true; }; https://blog.darkthread.net/blog/webclient-ssl-dismatch/
# by cheng
抱歉,有人有遇過XDocument.Load()後發生Unable to connect to the remote server嗎 而且是有時有,有時沒有一直沒法找到原因