純手工打造 ePub 電子書
| | | 12 | |
【寫在前面】ePub 電子書對大多數人來說只要開閱讀器能讀就好,即便要製作 ePub 電子書,現成軟體、工具、服務或線上轉換器多不勝數,極少人需要去了解技術細節。如果你對 ePub 結構感到興趣,或希望讀得不開心時有能力自己修正調整,或是想寫程式批次產生或轉換,有述需求再繼續讀下去。
去年入手電子書閱讀器,看了不少電子書。電子紙 (e-Ink) 的閱讀體驗很接近印刷紙張,比手機或平板螢幕柔和很多,長時間閱讀眼睛也較不會疲倦。但有時在網路上看到一些長篇技術文件,常會想:如果能抓回來轉成 ePub,再找時間用電子紙看多好?加上好奇心驅使,讓我有自己寫 C# 程式製作 ePub 的念頭。
一切要先從了解 ePub 格式開始
ePub 其實是一個 ZIP 檔,裡面裝了 XHTML、圖檔、css,說穿了跟 Word docx 的概念差不多。(提到 XHTML,寫網頁的老人肯定很有感,這位被 HTML5 推翻的舊時代餘毒竟轉進 ePub 撐起一片天)
用 XHTML 寫好書本內容後,要轉成 ePub 電子書還需要一些額外配件。就用實例來練習吧! 假設我想寫一本「ePub 手作練習」ePub 電子書,內容分成兩章分別存成 format.html 及 diy.html。要打包的檔案結構如下圖,根目錄下有 mimetype 跟 META-INF 及 OEBPS 子資料夾,META-INFO 下只有一個 container.xml,其餘內容都放在 OEBPS 下:(參考:EPUB 2 規格 by 周邦信 筆記本)

以下簡單說明各檔案用途:
- mimetype 檔案(無附檔名),內容必須為 application/epub+zip 不多不少共 20 個字元,而且要是 ZIP 的第一個檔案。
- container.xml 放在 META-INF 子目錄下,指向 content.opf,供閱讀器取得這本電子書相關資訊:
書籍內容檔案建議放在名為 OEBPS (Open eBook Publication Structure) 的目錄下,但此點非強制性,要放在 ZIP 根目錄或任意名稱的資料夾也可以。<?xml version="1.0"?> <container version="1.0" xmlns="urn:oasis:names:tc:opendocument:xmlns:container"> <rootfiles> <rootfile full-path="OEBPS/content.opf" media-type="application/oebps-package+xml"/> </rootfiles> </container> - content.opf 定義了電子書資訊與內容元素。 metadata 可包含書籍作者、出版日期、分類等圖書資訊;manifest 要列舉 ePub 檔內的檔案項目,項目 id 屬性用於與 metadata 及 spine 連結;spine 則定義閱讀時相關元素的先後順序;
<?xml version='1.0' encoding='utf-8'?> <package xmlns="http://www.idpf.org/2007/opf" unique-identifier="uuid_id" version="2.0"> <metadata xmlns:calibre="http://calibre.kovidgoyal.net/2009/metadata" xmlns:dc="http://purl.org/dc/elements/1.1/" xmlns:dcterms="http://purl.org/dc/terms/" xmlns:opf="http://www.idpf.org/2007/opf" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> <dc:language>zh</dc:language> <dc:title>ePub 手作練習</dc:title> <dc:creator opf:file-as="darkthread" opf:role="aut">黑暗執行緒</dc:creator> <meta name="cover" content="cover"/> <dc:identifier id="uuid_id" opf:scheme="uuid">b1ce20ed-9214-470c-97d0-2648fc2f7760</dc:identifier> <dc:contributor opf:role="bkp"></dc:contributor> <dc:publisher>黑暗出版社</dc:publisher> </metadata> <manifest> <item href="cover.jpg" id="cover" media-type="image/jpeg"/> <item href="titlepage.xhtml" id="titlepage" media-type="application/xhtml+xml"/> <item href="format.html" id="html1" media-type="application/xhtml+xml"/> <item href="diy.html" id="html2" media-type="application/xhtml+xml"/> <item href="page_styles.css" id="page_css" media-type="text/css"/> <item href="stylesheet.css" id="css" media-type="text/css"/> <item href="toc.ncx" id="ncx" media-type="application/x-dtbncx+xml"/> </manifest> <spine toc="ncx"> <itemref idref="titlepage" /> <itemref idref="html1"/> <itemref idref="html2"/> </spine> <guide> <reference href="titlepage.xhtml" title="Cover" type="cover"/> </guide> </package> - titlepage.xhtml 為封面定義檔(註:svg ViewBox 的寬高要配合 conver.jpg 尺寸)
<?xml version='1.0' encoding='utf-8'?> <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en"> <head> <meta http-equiv="Content-Type" content="text/html; charset=UTF-8"/> <title>Cover</title> <style type="text/css" title="override_css"> @page {padding: 0pt; margin:0pt} body { text-align: center; padding:0pt; margin: 0pt; } </style> </head> <body> <div> <svg xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" version="1.1" width="100%" height="100%" viewBox="0 0 904 1186" preserveAspectRatio="none"> <image width="904" height="1186" xlink:href="cover.jpg"/> </svg> </div> </body> </html> - toc.ncx 為一個 XML,包含了書本標題、目錄項次。navPoint 的 id 可自訂,不重複即可,src 指向讓章節所在位置,若文章較長可拆成各章一個 html 檔案,小節部分可以用 URL Fragment (例如: #sectionName) 連結。範例:
<?xml version='1.0' encoding='utf-8'?> <ncx xmlns="http://www.daisy.org/z3986/2005/ncx/" version="2005-1" xml:lang="zh-TW"> <head> <meta content="b1ce20ed-9214-470c-97d0-2648fc2f7760" name="dtb:uid"/> <meta content="1" name="dtb:depth"/> <meta content="calibre (3.44.0)" name="dtb:generator"/> <meta content="0" name="dtb:totalPageCount"/> <meta content="0" name="dtb:maxPageNumber"/> </head> <docTitle> <text>ePub 手作練習</text> </docTitle> <navMap> <navPoint id="ch1" playOrder="1"> <navLabel> <text>ePub 格式解析</text> </navLabel> <content src="format.html"/> </navPoint> <navPoint id="ch2" playOrder="2"> <navLabel> <text>動手做書樂無窮</text> </navLabel> <content src="diy.html"/> </navPoint> </navMap> </ncx> - page_styles.css 是全書通用的樣式
@page { margin-bottom: 5pt; margin-top: 5pt } - styles.css 可用來儲存自訂樣式
各章節檔案再用<link href="xxx.css" rel="stylesheet" type="text/css" />指向 page_styles.css 及 styles.css,這部可依網頁設計原理安排,無強制要求。 - 封面圖片,例如: cover.jpg。尺寸上沒有嚴格規定,參考各家電子書平台建議,大約抓寬高 1:1.6,500x800 以上,取 jpg 格式。
準備好上述項目,將整個資料夾壓成 ZIP 檔(注意:mimetype、META-INFO、OEBPS 要直接在 ZIP 內容的根目錄)再更名為 .epub,電子書就完成了!


補充,自製 ePub 過程蠻常因格式、內容錯誤、缺檔造成無法開啟,有個 EPUBCheck 工具能快速指出 ePub 錯誤所在,是 DIY 時不可或缺的好工具:
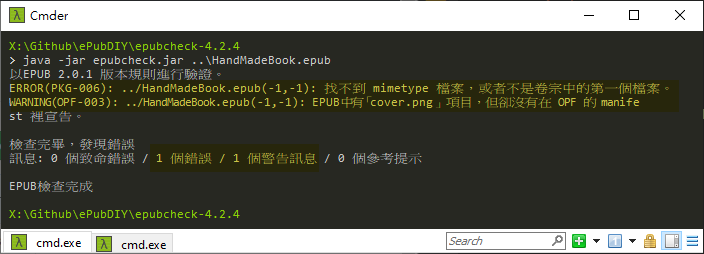
掌握手工製作 ePub 技巧,未來要修校電子書或搞搞網頁批次轉換,都知道怎麼下手囉~
Explaining the structure of ePub format and try to create one by hand.
Comments
# by John
epubcheck錯誤訊息是mimetype為第一個檔案且不要壓縮
# by Jeffrey
to John, 對,後來自己寫 .NET 程式打包刻意不壓縮且放第一個,epubcheck 才不再抱怨,不過實測了 Kobo 跟 Chrome ePub 閱讀器,似乎不在意這條規範。
# by John
如果需要上架販售,epubcheck條件全過是基本條件
# by Jeffrey
to John, 原來如此,長知識了。謝謝分享!
# by Danny Lin
抓網頁真的是博大精深的一門學問。一般要抓網頁目前還是認為用 WebScrapBook 擷取和管理效果最好,至少我會特地去把網頁抓下來,主要目的通常是: 1. 清理垃圾 2. 畫線,寫筆記 3. 保留 metadata 供需要時作為 reference 4. 全文檢索 我在想如果 WebScrapBook 可以滿足絕大部分需求,做成 ePub 只是為了改善在手機、平板、電子閱讀器上排版效果及外出閱讀體驗,或許可以寫個 WebScrapBook => ePub 轉檔程式來處理...🤔 (對電子紙不熟,不曉得目前的電子紙是否可直接看網頁?還是只支援 ePub、pdf 等特定電子書格式?) 但如果製作 ePub 還打算把網頁整個 tidy,格式統一成像一本書的樣子,那可能還是不得不針對各網站寫專門的擷取及格式清理工具了...😂
# by Jeffrey
to Danny Lin, 電子紙因特性關係,畫面更新速度不快(體感換個畫面要花一秒吧),閱讀器的 CPU 完全無法跟手機平板相比,就算能支援一般網頁,瀏覽體驗也好不到哪去。「針對各網站寫專門的擷取及格式清理工具 」<= 一語道破網頁轉 ePub 最大的痛點。如果 WebScrapBook 已有擷取及清理功能,WebScrapBook => ePub 轉檔是好點子,有空來研究一下,感謝分享。
# by Danny Lin
WebScrapBook 主要是設計為「如實擷取螢幕呈現頁面」的通用工具,是有清理功能,但多半是通用性的,如要針對特定站台做清理可以寫針對性的擷取助手,但擷取助手功能相當有限(很大一部分原因是受限於瀏覽器套件的限制),必要時可以考慮寫 bookmarklet 或用其他 monkey 之類的腳本工具。 這就是網頁擷取比較坑的地方,基本上網頁大致可以分成幾類: 1. 一般的公開靜態網頁 2. 需要身分認證的私人網頁 3. 要瀏覽器跑 JavaScript 動態加載的動態網頁 一般第三方擷取工具處理 1. 還行,處理 2. 就很麻煩(要把 cookie 等認證資訊從瀏覽器傳過去,或是自備身分認證處理機制),至於 3.,目前似乎只有瀏覽器擴充套件才有機會正常擷取……(bookmarklet 容易受限於 same origin policy 和 content security policy 而抓不全)。 但是 WebScrapBook 目前還只支援單頁擷取,把連結頁面一併擷取(且維持交互連結)的功能還難產中XD 前身的 ScrapBook X 有這功能,不過 ScrapBook X 架構太舊了,不少現代網頁的新功能無法完全正常擷取,要注意一下。
# by Sherri
請問一下,mimetype為第一個檔案且不要壓縮這件事,我一直沒有成功過,請問大大可以分享一下壓縮流程嗎?
# by Jeffrey
to Sherri, 我是自己寫 C# 程式處理的,接在爬文轉檔程序後面做,但你如果原本沒有程式,用工具軟體可能方便些。網路上有用 7zip 或 zip 的操作範例 https://ebooks.stackexchange.com/a/639
# by Howard
前陣子在三創發現Onyx BOOX 電子閱讀器,畫面更新速度快很多,採用平板級CPU,而且OS使用Android 10,所以可以上Google Play安裝APP。當然電子紙流暢度仍無法和液晶螢幕相比,但瀏覽網頁還算堪用
# by Dennis
最近試著將電子書改成自己喜歡的格式,發現如果在直書中加入有序列表,開頭的數字都會像其他半形字元一樣順時針偏轉90度,有什麼方法使有序列表的阿拉伯數字或拉丁字母標示垂直顯示呢?
# by Jeffrey
to Dennis,這種情況,最具體有效的解法應該是去找本有做到序列表垂直顯示數字的電子書,解開 epub 研究人家如何辦到的,然後拿香跟著拜。