動手玩 AI - 使用 OpenAI Embedding 模型比對文字相似性
 |  | 1 |  |  |
在 ChatGPT 整合自有資料的 RAG 測試學到不少新東西,其中一個是 Embedding。(嵌入、內嵌,這些翻譯我都覺得怪,文章會用英文原文)
Word Embedding 是自然語言處理(NLP)中將文字內容轉成多維向量數值的一種技術,概念是將原本每個詞一個維度(數量以萬起跳)的高維空間嵌入到一個維度低很多的向量空間,文字特徵或表徵(Feature/Representation)被轉成數字,便可運用數學方法進行運算,用以評估文字相似度,實現分類(找出垃圾郵件、情感分析)、文字檢索、機器翻譯、推薦系統... 等各式文字應用。
RAG 範例中用了 OpenAI text-embedding-ada-002 模型將文字內容轉成 Embedding 並存入 Azure AI Search 索引庫,查詢時則將查詢問題也轉 Embedding,交由 AI Search 服務比對找出相關內容。
我過去沒碰過 NLP,現在才發立最基本的概念,打算用見識豬走路的心態實測一下 text-embedding-ada-002。我計劃寫段 .NET 程式做簡單測試,將多段文字使用 OpenAI Embedding 模型轉成 Embedding,透過比對 Embedding 測試彼此間的相似度,是否符合一般的認知,以上就是本次的企劃。
MS Learn 上有 C# 呼叫 OpenAI Embedding API 範例,照抄即能可輕易將一段文字轉成一串 float 浮點數。(註:float 數量共 1536 個,即 text-embedding-ada-002 使用的向量陣列長度,身為門外漢覺得龐大,但其實它只有 davinci-001 的 1/8,已經縮小很多了)
如此我們便可將任意文字都轉成 1536 個 float,但要怎麼用它來判斷文字是否相似?
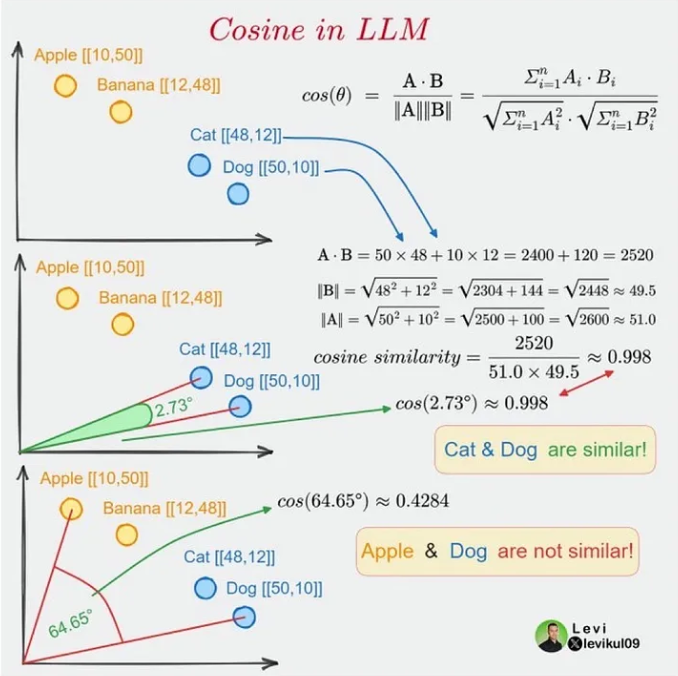
Cosine Similarity (餘弦相似性) 是依據 Embedding 向量計算文件相似性的常用做法,背後有一堆數學理論,若你跟我一樣只想有個概念不想深入,大概的意思是相近文字的對映向量角度也會相似,兩個向量形成的夾角愈小,Cosine 值例大,夾角為 0 時 Cosine 等於 1,完全無關夾角 90 度 Cosine 等於 0。如下圖,Cat 與 Dog Cosine = 0.998,Dog 與 Apple 關聯較少 Cosine 為 0.4284:
以下是我的測試程式,輸入一串 string[],呼叫 OpenAI API 取得 Embedding 向量值,兩兩計算 Cosine Similarity,以 HTML 表單呈現結果,數值為 Consine Similarity 計算值,數字愈高文字顏色愈紅,底色愈黃,代表二者愈相似。
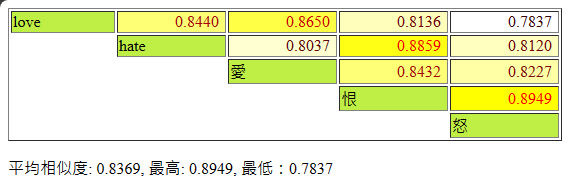
由上圖,恨與怒高度相似,其次是 hate 與恨,再其次是 love 與愛、love 與 hate。Cosine Similarity 值愈大意味文字同時出現機率愈高,二者愈相關,但未必是同義字,像是 love 跟 hate 常伴隨出現,隨然二者詞義相反,但相關性排第四。其中相關度最低的是 love 與怒,愈風馬牛不相及,值愈低。
再試另外一組:

最相關的是炸雞跟薯條,有趣的是,炸雞與反應爐關聯性頗高(因為炸跟爐嗎?);而企鵝跟薯條、炸雞的關聯比企鵝跟南極還密切。天外飛來一筆的氟,跟所有其他項目的關聯最低,其次是南極,也屬於本群中較邊緣的項目。
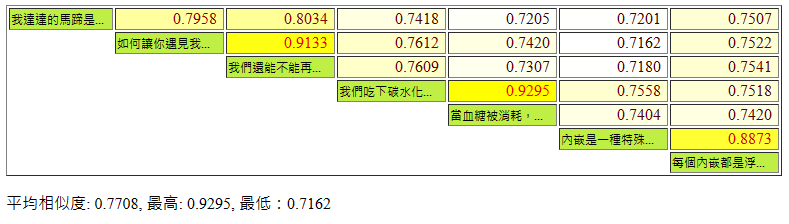
最後試一下文字段落的比對,我準備了以下內容:
var texts = new string[] {
"我達達的馬蹄是美麗的錯誤 我不是歸人,是個過客",
"如何讓你遇見我 在我最美麗的時刻 為這 我已在佛前 求了五百年 求他讓我們結一段塵緣",
"我們還能不能再見面 我在佛前苦苦求了幾千年 願意用幾世換我們一世情缘 希望可以感動上天",
"我們吃下碳水化合物,消化後將轉為葡萄糖進入血液,血糖上升會刺激胰臟 β 細胞分泌「胰島素」,讓血糖進入細胞給細胞利用,並將多餘血糖合成肝醣儲存到肝臟及肌肉",
"當血糖被消耗,血糖濃度會下降,此時胰臟 α 細胞會分泌「升糖素」,分解肝醣釋出葡萄糖以及糖質新生(把體內其他原料轉變為葡萄糖)提高血糖濃度",
"內嵌是一種特殊的數據表示格式,可供機器學習模型和演算法輕鬆使用。內嵌是文字片段語意意義的資訊密集表示法。",
"每個內嵌都是浮點數的向量,因此,在向量空間中兩個內嵌之間的距離與原始格式兩個輸入之間的語意相似度相互關聯。",
};
「一棵開花的樹」與「誓言版求佛」相近,兩段血糖運作原因描述相近,兩段談內崁的文字相近,符合一般的預期:
體驗完畢,對 Word Embedding 有了粗淺的認識,後續再看 RAG 流程就不會霧煞煞囉。
最後附上範例程式,也想動手玩看看的同學可以參考:(專案使用 Azure OpenAI 服務,需 dotnet add package Azure.AI.OpenAI --prerelease 引用相關程序庫,官方教學)
using System.Diagnostics;
using System.Text;
using System.Text.Json;
using Azure;
using Azure.AI.OpenAI;
Uri oaiEndpoint = new("https://<your-host-name>.openai.azure.com");
string oaiKey = "<your-key>";
AzureKeyCredential credentials = new(oaiKey);
OpenAIClient openAIClient = new(oaiEndpoint, credentials);
Func<string, float[]> GetEmbedding = (text) =>
{
EmbeddingsOptions embeddingOptions = new()
{
DeploymentName = "embedding",
Input = { text },
};
return openAIClient.GetEmbeddings(embeddingOptions).Value.Data[0].Embedding.ToArray();
};
// 暫存 Embedding 查詢結果,若測試文字未變,不需每次重新查詢
var results = new Dictionary<string, float[]>();
var cacheName = "results.json";
if (File.Exists(cacheName))
results = JsonSerializer.Deserialize<Dictionary<string, float[]>>(File.ReadAllText(cacheName))!;
string[] texts;
texts = new string[] {
"love",
"hate",
"愛",
"恨",
"怒"
};
texts = new string[] {
"漢堡",
"薯條",
"可樂",
"炸雞",
"反應爐",
"氟",
"企鵝",
"南極"
};
texts = new string[] {
"我達達的馬蹄是美麗的錯誤 我不是歸人,是個過客",
"如何讓你遇見我 在我最美麗的時刻 為這 我已在佛前 求了五百年 求他讓我們結一段塵緣",
"我們還能不能再見面 我在佛前苦苦求了幾千年 願意用幾世換我們一世情缘 希望可以感動上天",
"我們吃下碳水化合物,消化後將轉為葡萄糖進入血液,血糖上升會刺激胰臟 β 細胞分泌「胰島素」,讓血糖進入細胞給細胞利用,並將多餘血糖合成肝醣儲存到肝臟及肌肉",
"當血糖被消耗,血糖濃度會下降,此時胰臟 α 細胞會分泌「升糖素」,分解肝醣釋出葡萄糖以及糖質新生(把體內其他原料轉變為葡萄糖)提高血糖濃度",
"內嵌是一種特殊的數據表示格式,可供機器學習模型和演算法輕鬆使用。內嵌是文字片段語意意義的資訊密集表示法。",
"每個內嵌都是浮點數的向量,因此,在向量空間中兩個內嵌之間的距離與原始格式兩個輸入之間的語意相似度相互關聯。",
};
// 是否文字都是查過的
if (!texts.All(results.ContainsKey))
{
results = texts.ToDictionary(text => text, GetEmbedding);
File.WriteAllText(cacheName, JsonSerializer.Serialize(results, new JsonSerializerOptions { WriteIndented = true }));
}
Func<string, string> SimpTrim = t => t.Substring(0, Math.Min(t.Length, 7)) + (t.Length > 7 ? "..." : "");
var keys = results.Keys.ToArray();
var sb = new StringBuilder();
sb.AppendLine(@"
<!DOCTYPE html>
<style>
td.inv { border: none; }
td { width: 100px; }
td.val { text-align: right; padding-right: 6px; }
td.word { background-color: #bfef45; font-size: 9pt; }
</style>
<table border=1>
");
var simVals = new List<float>();
for (var a = 0; a < keys.Length; a++)
{
sb.Append($"<tr>");
if (a > 0) sb.Append($"<td colspan={a} class=inv></td>");
sb.Append($"<td class=word>{SimpTrim(keys[a])}</td>");
for (var b = a + 1; b < keys.Length; b++)
{
var sim = CosineSimilarity(results[keys[a]], results[keys[b]]);
simVals.Add(sim);
sb.Append($"<td class=val>{sim:n4}</td>");
}
sb.AppendLine("</tr>");
}
sb.AppendLine("</table>");
var avg = simVals.Average();
var min = simVals.Min();
var max = simVals.Max();
var range = max - min;
sb.AppendLine($"<p>平均相似度: {avg:n4}, 最高: {max:n4}, 最低:{min:n4}</p>");
sb.AppendLine(@$"
<script>
const avg = {avg}, max = {max}, min = {min}, range = {range};
const tds = document.querySelectorAll('td');
function toHex(n) {{
return parseInt(n).toString(16).padStart(2, '0');
}}
for (const td of tds) {{
if (td.innerText === '' || isNaN(td.innerText)) continue;
const sim = parseFloat(td.innerText);
const diff = Math.abs(sim - min);
td.style.backgroundColor = '#ffff00' + toHex(255 * diff / range);
td.style.color = '#' + toHex(191 * diff / range + 64) + '0000';
}}
</script>
");
var tmpFile = Path.GetTempFileName() + ".html";
File.WriteAllText(tmpFile, sb.ToString());
Process.Start(new ProcessStartInfo("cmd", $"/c start {tmpFile}")
{ CreateNoWindow = true });
// 1 = 一致, 0 = 無關
static float CosineSimilarity(float[] vector1, float[] vector2)
{
if (vector1.Length != vector2.Length)
{
throw new Exception("Vectors are not the same dimensionality");
}
float dotProduct = 0.0f;
float norm1 = 0.0f;
float norm2 = 0.0f;
for (int i = 0; i < vector1.Length; i++)
{
dotProduct += vector1[i] * vector2[i];
norm1 += vector1[i] * vector1[i];
norm2 += vector2[i] * vector2[i];
}
return (float)(dotProduct / (Math.Sqrt(norm1) * Math.Sqrt(norm2)));
}
Example of using text-embedding-ada-002 model to get embedding and calculate cosine similarity to find similarity between words and paragraphs.
Comments
# by Joker
最近剛好也在玩這個,剛好可以站在巨人的肩膀上,多謝分享。