小試 RAG - 整合 ChatGPT 與自有資料 (駕駛人手冊實測)
| | | 10 | |
最近學到新名詞 - Retrieval Augmented Generation (RAG),號稱可以結合 ChatGPT 這類預訓練大型語言模型(LLM)依據自有資料來源生成內容。要這麼做的理由是預訓練模型會以某個時點的資料定型,如要加入新資料或自訂資料,有兩種做法:用新資料進行微調訓練,或使用 RAG 靠提示工程整合補充資料。
微調訓練可將客製化資料與 GPT 原有知識無縫融合,是最直覺有效的解法,但微調模型成本高昂,非人人負擔得起(以 Azure Open AI 為例,訓練成本是每小時 34 ~ 103 USD,跑自訂模型則每小時 1.7 ~ 7 USD,不考慮訓練成本,每個月光跑服務就要 3 ~ 15 萬台幣 參考)。相較之下,RAG 只需小額課金就能上手,是可行性更高的解決方案。至於運作原理及效果如何,便是我這篇文章研究的重點。
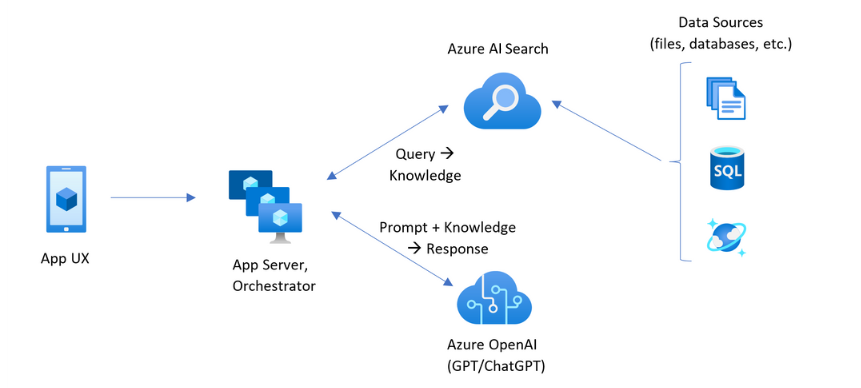
簡單來說,RAG 的架構是 App 服務接受使用者輸入內容,結合 ChatGPT 與自訂文件庫或資料來源,讓 ChatGPT 依據指定資料來源提供使用者回覆。這裡資料通常是機器學習常用的向量索引(Vector Index)形式,其中的資料關聯被轉成 Embedding (將資料/Concept 間的關聯轉為數字序號),而 LLM 有能力從向量資料有效率地找出所需內容。向量索引部分,Azure RAG 解決方案支援 Faiss 開源專案或使用 Azure AI Search。參考
將資料轉成向量是門學問,Azure AI Search 能讓事情簡單些,它提供方法可將文字、圖像、影片、音訊索引成 Token、向量再結合 ChatGPT 運用。

光看文件太抽象,我決定跑個展示實際用看看。我找到 ChatGPT + Enterprise data with Azure OpenAI and Cognitive Search (.NET) 範例專案,它虛構了一家 Contoso 電子公司,建立了一個 AI 交談介面回覆員工公司制度與福利相關問題,制度福利內容均來自 PDF 文件,非憑空生成。
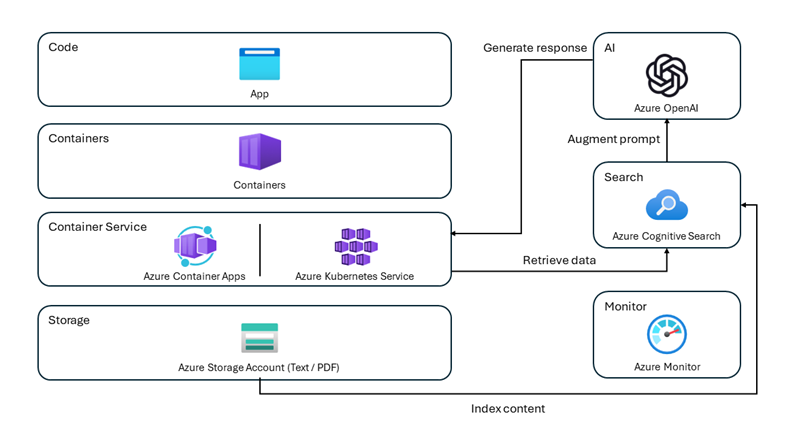
PDF 文件部分透過 Azure AI Search (以前叫 Azure Cognitive Search,2023/11 才改名的 Orz) 轉成向量索引並存入 Azure Storage 帳號;用 Azure OpenAI 服務生成回應內容,其中採用了 Semantic Kernel 架構 (為開源 SDK,提供整合提示工程、記憶上下文、Zero/Few-Shot學習、Zembeddings 等技術的開發模式,簡化生成式 AI 應用的開發工作,參考:運用Semantic Kernel SDK 駕馭生成式AI應用的提示工程(Prompt Engineering) by MVP Ian)。前端部分是用新潮的 Blazor WebAssembly,WebAPI 跑在 ASP.NET Core Minimal API。要運行專案,還需要建立多個 Azure 服務,修改 EndPoint 網址、API Key... 等設定,超複雜。
我被逼著學了新時代雲端服務部署新概念 - Azure Developer CLI,把複雜部署程序寫成 Bicep 或 Terraform 檔,需要部署時,一個指令完成大小事,實現傳說中的 Infrastructure as Code (IaC)。,照著文件說明跑了 azd up就把全部服務設好,程式順利運轉,我進化到「玩過 IaC 的人」惹:D
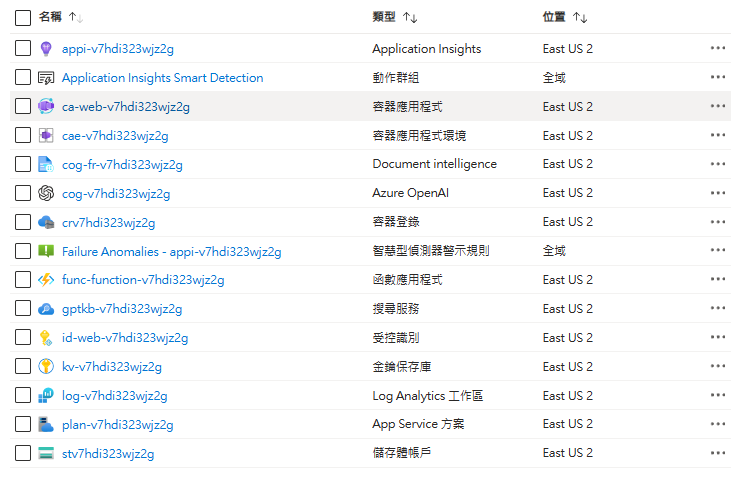
這是它建立的 Azure 服務項目:
執行成果如下,用中文問就會用中文回答,畢竟背後可是 ChatGPT:

我到公路局網站下載了駕駛人手冊,共 7 個分章 PDF 檔,涵蓋駕照、交通規則、號誌、安全駕駛、事故處理... 等駕駛須知,我將範例專案中的公司章程 PDF 換成交通部駕駛人手冊,看 ChatGPT 能否變身老司機?
表現比我預期好很多。
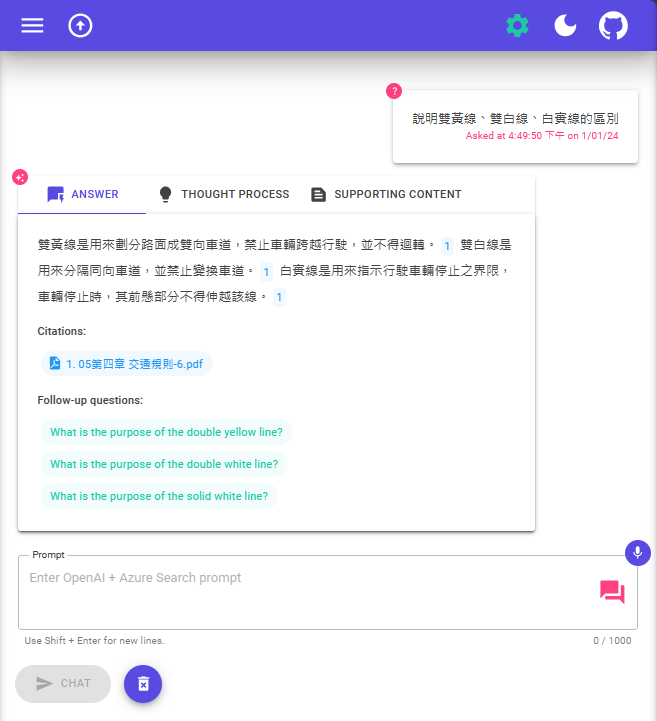
有時來源連結會不正確,如下圖的 sournce 被導向錯誤的 BLOB 連結。

Supporting Content 部分還算精準:

大部分時侯 Citation 連結指向的頁面也是對的:
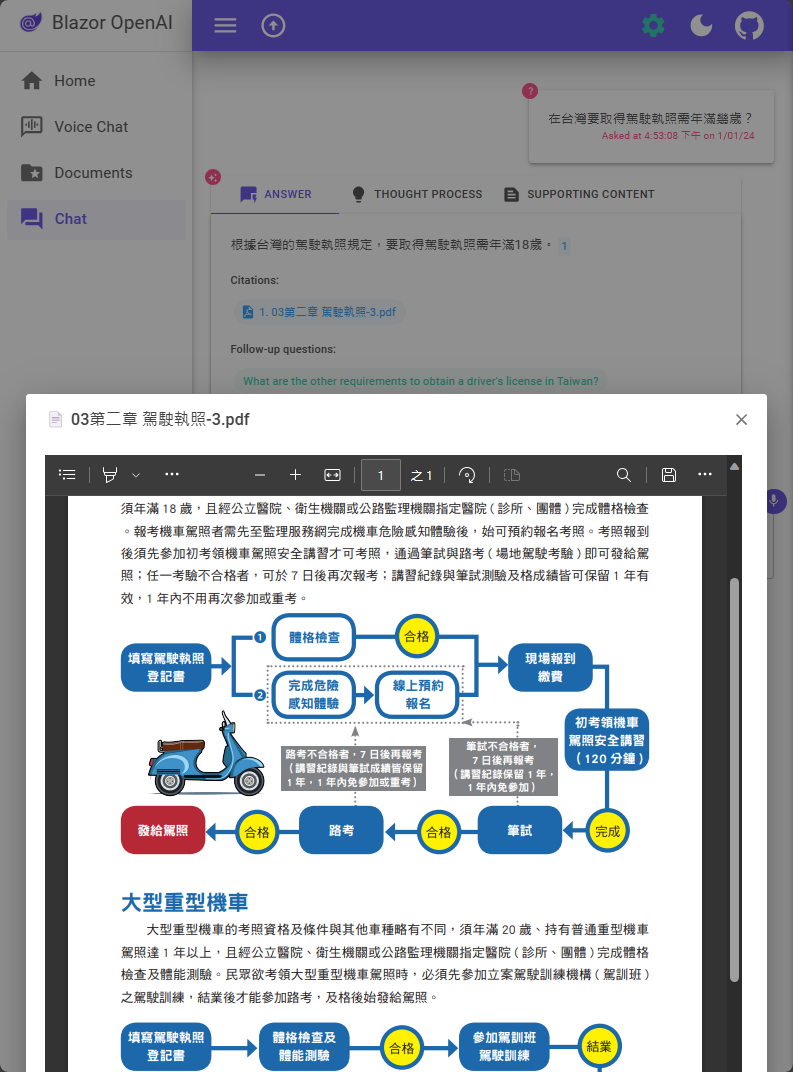
加考重機考照年齡,ChatGPT 也沒被難倒:

甚至惡搞故意胡亂提問... 哈,這回答我給過!
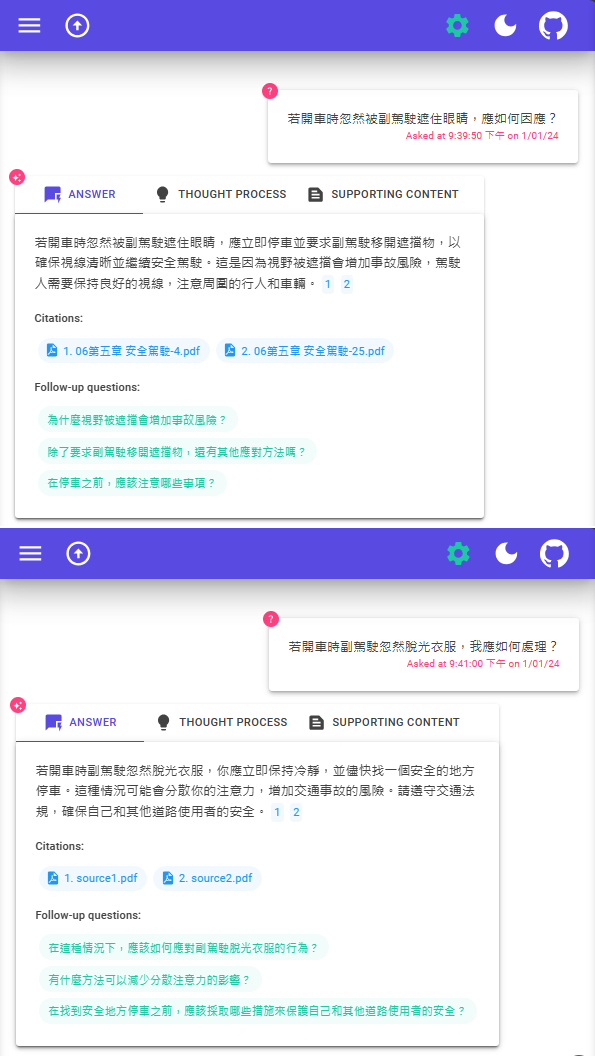
我對機器學習、向量索引不熟,還沒完全搞懂 RAG 原理,但這個實測結果讓我很滿意,感覺已達可上場應戰的水平。未來有適當情境,應可將 RAG 列為解決方案之一。
My first RAG lab to run ChatGPT with custom data.
Comments
# by Cash
還沒完全搞懂 「ARG」 原理,但這個實測結果讓我很滿意 ARG > 應該是 RAG ?
# by Jeffrey
to Cash, Yes, 謝謝指正。
# by Joker
說實在的看了幾個影片,還有使用這個技術下去實做的例子。 認真覺得再過五年可以退休了耶....
# by Samuel
可以去上架 GPT Store了
# by 打球囉
請問有沒有試過 Meta LLAMA2 + RAG 呢 ?
# by Jeffrey
to 打球囉,沒試過,但依 RAG 的原理,LLM 跟向量(或全文檢索)資料庫可任意抽換成你偏好的解決方案,但效果跟 LLM/文件搜索服務的聰明程度有關。
# by Jy
請問黑大,會不會多問幾句就回HTTP 500,自己部署C#、Python的範例程式都有同樣的問題, 看Azure後台是顯示Json格式錯誤,但Json格式錯誤應該每次都會HTTP 500,而不會偶爾正常回答。
# by Jeffrey
to Jy, 多問幾句出錯時,是不是新開話題就 OK?一個常見原因是範例專案會將加入先前交談歷史作為 Prompt,很容易超出 Token 上限,常見解法是當歷史內容過長時請 ChatGPT 將其濃縮摘要成幾句話。
# by Jy
感謝黑大,"Use query-contextual summaries instead of whole documents"勾選就可以了!
# by Jeffrey
to Jy, 感謝分享。