影音檔 Whisper 轉逐字稿之檔案批次處理工具
| | | 3 | |
前陣子介紹了用 Whisper API 將 MP3 轉逐字稿,不需準備高檔顯卡,用一顆茶葉蛋的錢,一小時 MP3 轉逐字稿大約兩分鐘可完成,速度跟品質都頗令人滿意。
實測過幾次,發現免不了需要一些轉檔、併檔、拆檔,基本上靠萬能的 ffmpeg 都能解決,但每次遇到要查指令敲指令很沒效率,是時侯寫成共用腳本檔或程式庫了。這篇會用 PowerShell 示範,但關鍵在 ffmpeg 參數,大家可視需要改寫成自己慣用的語言。
整理我常用的檔案批次作業:
- 錄影或錄音檔有多個,想合併成一個
- 來源為 .mp4,想轉成 .mp3
- Whisper 有單檔 25MB 限制,以 20 分鐘為單位將 .mp3 拆成多個檔案
- 將長時間 .mp3 自動拆檔 Whisper 轉換再組裝成單一 .mp3 (檔案間加上分隔註記方便整理校正)
為此,我寫了三個函式:Az-MergeMp4s、Az-ConvertMp4ToMp3、Az-SplitMp3、Az-TranscibeLongMp3,程式邏輯不難,說穿了就是組裝好參數,召喚 ffmpeg 登場大顯神威罷了。只有幾個小地方值得一提:
- 合併檔案需將動態產生檔案清單文字檔,合併完成後刪除
- PowerShell 內建的 Resolve-Path 無法解析不存在路徑,要取得絕對路徑需額外處理
- ffmpeg 的 -hide_banner 參數可隱藏又臭又長的版本、版權聲明及支援格式資訊 -v warning 只顯示警告等級以上訊息 -stats 顯示進及流計資訊
- 拆分檔案時,用 -ss 指定開始秒數或 mm:ss 時間值、-t 指定長度(我習慣加 60 秒與下段重疊)
function Resolve-AbsPath($relPath) {
return $ExecutionContext.SessionState.Path.GetUnresolvedProviderPathFromPSPath($relPath)
}
function Az-MergeMp4s(
[Parameter(Mandatory=$true)][string[]]$mp4Paths,
[Parameter(Mandatory=$true)][string]$outPath) {
# 寫入檔案清單暫存檔
$tmpListPath = [IO.Path]::GetTempFileName() + '.txt'
$mp4Paths | ForEach-Object { "file '$(Resolve-Path $_)'" } | Set-Content -Path $tmpListPath
# 將路徑解析成絕對路徑 https://blog.darkthread.net/blog/ps-resolve-non-existing-path/
$outPath = Resolve-AbsPath $outPath
& ffmpeg -f concat -safe 0 -i $tmpListPath -c copy -hide_banner -stats -v warning $outPath
Remove-Item -Path $tmpListPath
Write-Host "$outPath created." -ForegroundColor Green
}
function Az-ConvertMp4ToMp3($mp4Path, $outDir = '.') {
$mp4Path = Resolve-Path $mp4Path
$outDir = Resolve-AbsPath $outDir
[IO.Directory]::CreateDirectory($outDir) | Out-Null
$mp3Path = [System.IO.Path]::ChangeExtension($mp4Path, '.mp3')
& ffmpeg -i $mp4Path -hide_banner -stats -v warning $mp3Path
Write-Host "$mp3Path created." -ForegroundColor Green
}
function Az-SplitMp3($mp3Path, $outDir = '.', $sliceLen = 1200, $overlap = 60)
{
$mp3Path = Resolve-Path $mp3Path
[int]$duration = & ffprobe -i $mp3Path -show_entries "format=duration" -v quiet -of "csv=p=0"
$count = [math]::Ceiling($duration / $sliceLen)
for ($i = 0; $i -lt $count; $i++) {
$start = $i * $sliceLen
$timeSpan = [TimeSpan]::FromSeconds($start)
$outFile = [System.IO.Path]::Combine($outDir, [System.IO.Path]::GetFileNameWithoutExtension($mp3Path) + "-$($i+1).mp3")
& ffmpeg -i $mp3Path -ss $start -t ($sliceLen + $overlap) -hide_banner -stats -v warning -c copy $outFile
Write-Host "Split $timeSpan to $outFile" -ForegroundColor Cyan
}
}
function Az-TranscibeLongMp3(
[Parameter(Mandatory=$true)]$mp3Path,
[Parameter(Mandatory=$true)]$prompt,
$outDir = '.\temp', $sliceLen = 1200,
$whisperDelpoy = $whisperDeployName,
$gptDeploy = $gptDeployName
)
{
$outDir = Resolve-AbsPath $outDir
[IO.Directory]::CreateDirectory($outDir) | Out-Null
$mp3Path = Resolve-Path $mp3Path
Az-SplitMp3 $mp3Path $outDir $sliceLen
$files = Get-ChildItem -Path $outDir -Filter '*.mp3'
$transcripts = @()
$toRemove = @()
foreach ($file in $files) {
$transcripts += "==== $($file.Name) ===="
$transcript = Az-WhisperTranscribe $file.FullName -language 'zh' -prompt $prompt -deployName $whisperDelpoy
$transcriptPath = [System.IO.Path]::ChangeExtension($file.FullName, '.txt')
$transcript | Out-File -Path $transcriptPath -Encoding utf8 # backup
$transcripts += $transcript
$toRemove += $file.FullName
$toRemove += $transcriptPath
}
$txtPath = [System.IO.Path]::ChangeExtension($mp3Path, '.txt')
$transcripts | Out-File -Path $txtPath -Encoding utf8
$toRemove | ForEach-Object { Remove-Item -Path $_ -Force }
Write-Host "Transcript saved. [$txtPath]" -ForegroundColor Green
}
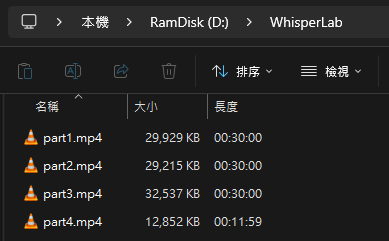
假設我有一堂課程錄影,分為四個檔案:
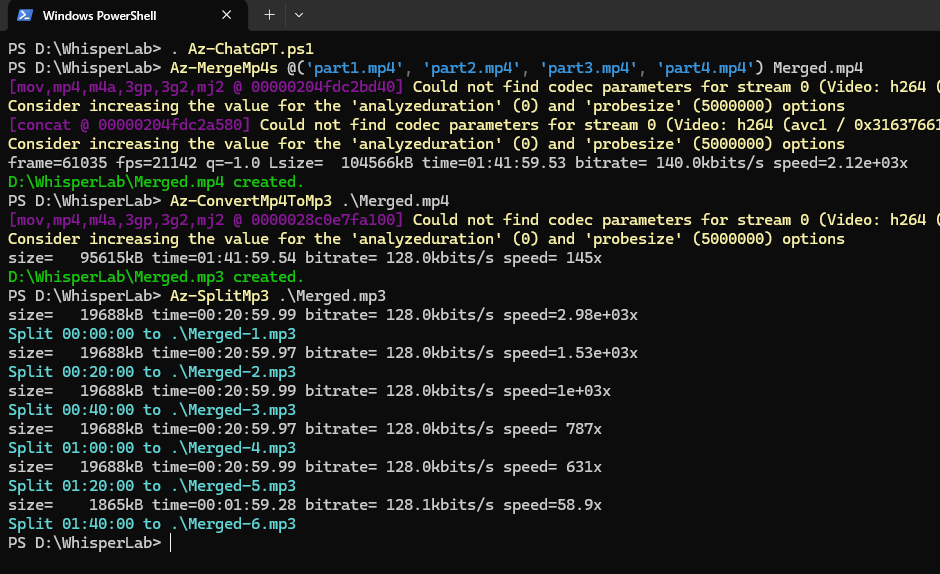
分別執行併檔、MP4 轉 MP3、一小時 44 分的 MP3 以 20 分鐘為單位拆成六個檔:
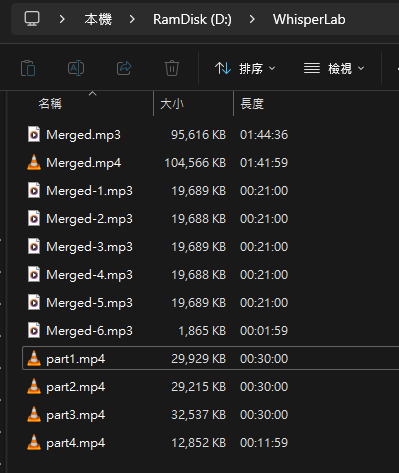
比較檔案大小時,發現一處可疑,.mp4 長度為 1:41:59,但轉換成 .mp3 後長度為 1:44:36。但檢查 part2.mp3 的起始時間確實有對上 .mp4 的 20:00 整。故推測是 Windows 跟 ffmpeg MP3 解碼器的差異造成,不影響結果。
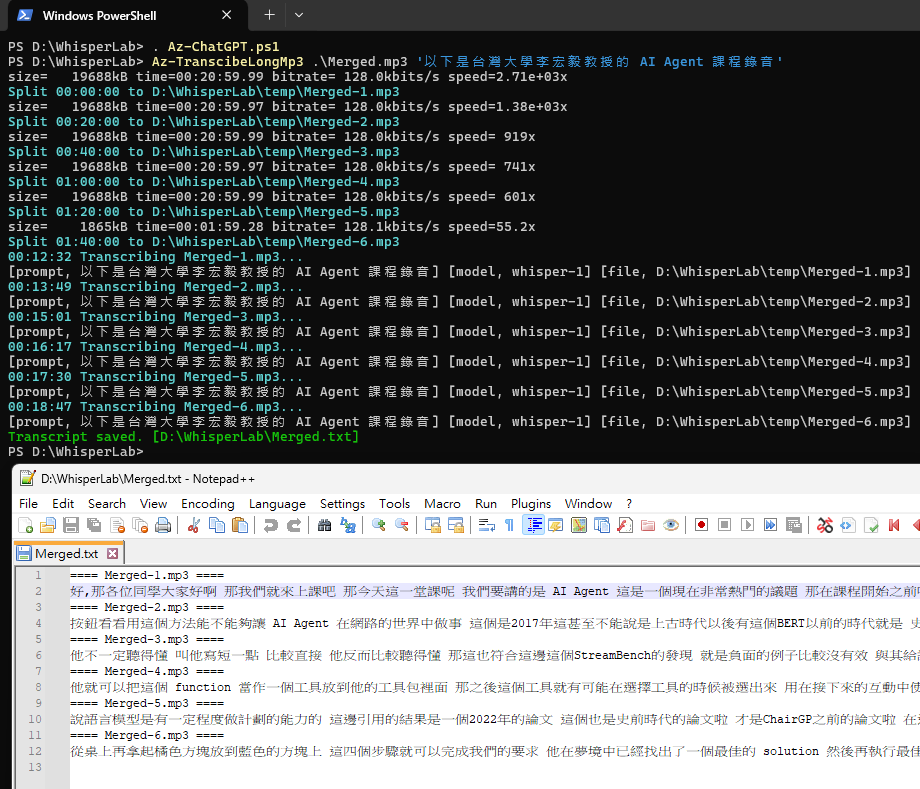
而自動長 .mp3 拆檔呼叫 Whisper 再組裝回單一 .txt 的簡易實測如下,轉 20 分鐘大約要 1'10":
有了以上工具,轉換長檔就簡單多了。
Comments
# by arick
按長度分割再轉文字. 如何處理句子不連貫問題?
# by Jeffrey
to arick, RAG 處理長文件也有相同問題,一般的做法是在切割處向前或向後延伸,讓兩個分割檔有部分重複。我在這的做法是多抓 60 秒,若起首的句子被切到只剩半截,有機會在前一段的結尾找到完整版。
# by Python路過吾好錯過
import os import sys import subprocess import time import requests import argparse from pathlib import Path import json from tqdm import tqdm # 進度條 import logging # 初始化日誌系統 logging.basicConfig( level=logging.INFO, # 設定日誌等級(INFO以上) format='%(asctime)s - %(levelname)s - %(message)s' # 日誌格式:時間 - 等級 - 內容 ) # 全局配置 API_URL = "https://api.openai.com/v1/audio/transcriptions" # OpenAI Whisper API 端點 API_KEY = os.getenv("OPENAI_API_KEY") # 從環境變數讀取 API 金鑰 TEMP_DIR = Path("./temp").resolve() # 暫存目錄的預設路徑 def check_ffmpeg_installed(): """檢查 FFmpeg 是否已安裝 使用子程序執行 'ffmpeg -version' 來驗證 FFmpeg 是否存在於系統路徑 若未安裝則輸出錯誤訊息並終止程式 """ try: subprocess.run(["ffmpeg", "-version"], capture_output=True, check=True) except subprocess.CalledProcessError: logging.error("FFmpeg 未安裝,請先安裝 FFmpeg!") sys.exit(1) def decrypt_api_key(): """驗證並返回 API 金鑰 1. 檢查環境變數 OPENAI_API_KEY 是否存在 2. 若不存在則輸出錯誤訊息並終止程式 3. 目前直接返回環境變數內容(實際使用需替換為加密解密邏輯) """ if not API_KEY: logging.error("未設定 OPENAI_API_KEY 環境變數!") sys.exit(1) return API_KEY def run_ffmpeg(command, log_file=None): """執行 FFmpeg 命令並處理異常 Args: command (str): FFmpeg 命令字串 log_file (str, optional): 輸出日誌檔案路徑 1. 執行 FFmpeg 命令 2. 若指定 log_file,將輸出重定向到指定日誌 3. 捕捉執行錯誤並輸出錯誤訊息 """ try: if log_file: with open(log_file, 'w') as f: subprocess.run(command, shell=True, check=True, stdout=f, stderr=subprocess.STDOUT) else: subprocess.run(command, shell=True, check=True) except subprocess.CalledProcessError as e: logging.error(f"FFmpeg 錯誤: {e}") sys.exit(1) # === 核心功能函式 === def transcribe_audio(audio_path, language='zh', prompt=None): """使用 OpenAI Whisper API 轉錄音訊 Args: audio_path (str): 音訊檔案路徑 language (str): 語言代碼(預設 zh 中文) prompt (str): 轉錄提示(預設使用通用提示) Steps: 1. 解密 API 金鑰 2. 建立 API 請求頭和參數 3. 發送 POST 請求到 Whisper API 4. 解析回傳的 JSON 資料並返回轉錄文字 """ api_key = decrypt_api_key() headers = {"Authorization": f"Bearer {api_key}"} files = {"file": (Path(audio_path).name, open(audio_path, "rb"))} data = { "model": "whisper-1", # 指定 Whisper 模型 "prompt": prompt or "Transcribe the audio", # 轉錄提示 "response_format": "json", # 回傳格式 "language": language # 語言設定 } logging.info(f"開始轉錄 {audio_path}...") response = requests.post(API_URL, headers=headers, data=data, files=files) response.raise_for_status() # 檢查 HTTP 狀態碼 return response.json().get("text", "") def merge_mp4_files(input_paths, output_path): """合併多個 MP4 影片 Args: input_paths (list): 輸入影片清單 output_path (str): 輸出影片路徑 實作步驟: 1. 創建 temp_file_list.txt 並寫入所有影片路徑 2. 執行 FFmpeg 命令合併影片 3. 刪除暫存清單檔案 """ tmp_list = Path("file_list.txt") with open(tmp_list, "w") as f: for path in input_paths: f.write(f"file '{Path(path).resolve()}'\n") # 寫入絕對路徑 output_path = Path(output_path).resolve() cmd = ( f'ffmpeg -f concat -safe 0 -i "{tmp_list}" ' # 使用 concat 協議 f'-c copy "{output_path}"' # 直接拷貝編碼 ) run_ffmpeg(cmd) tmp_list.unlink() # 刪除暫存清單 logging.info(f"合併完成:{output_path}") def convert_mp4_to_mp3(mp4_path, output_dir='.'): """將 MP4 轉換為 MP3 Args: mp4_path (str): 輸入 MP4 檔案路徑 output_dir (str): 輸出目錄 實作: 1. 使用 FFmpeg 提取音軌 2. 轉換為 MP3 格式(libmp3lame 編碼器) """ output_dir = Path(output_dir).resolve() mp3_path = output_dir / Path(mp4_path).with_suffix('.mp3').name cmd = ( f'ffmpeg -i "{mp4_path}" ' # 輸入影片 f'-vn -acodec libmp3lame "{mp3_path}"' # 移除視訊,轉 MP3 ) run_ffmpeg(cmd) return str(mp3_path) def split_mp3_file(mp3_path, output_dir='.', slice_len=1200, overlap=60): """分割長音訊為小片段(含重疊) Args: mp3_path (str): 輸入音訊路徑 output_dir (str): 輸出目錄 slice_len (int): 每段秒數(預設 1200 秒/20 分鐘) overlap (int): 重疊秒數(預設 60 秒) 實作步驟: 1. 取得音訊總長度 2. 計算需要分割的段數 3. 使用 FFmpeg 分割並保留重疊部分 """ output_dir = Path(output_dir).resolve() mp3_path = Path(mp3_path).resolve() # 取得音訊總長度(秒) duration_cmd = ( f'ffprobe -v error -show_entries format=duration ' f'-of default=noprint_wrappers=1:nokey=1 "{mp3_path}"' ) total_duration = float(subprocess.check_output(duration_cmd, shell=True).decode().strip()) num_slices = int(total_duration // slice_len) + 1 # 向上取整 split_files = [] for i in tqdm(range(num_slices), desc="分割音訊"): start = i * slice_len end = start + slice_len + overlap # 含重疊部分 output_file = output_dir / f"{mp3_path.stem}-{i+1}.mp3" cmd = ( f'ffmpeg -i "{mp3_path}" ' f'-ss {start} -t {end - start} ' # 起始時間與長度 f'-c copy "{output_file}"' # 直接拷貝編碼 ) run_ffmpeg(cmd) split_files.append(output_file) return split_files def transcribe_long_audio(mp3_path, prompt, output_dir='.'): """端到端處理長音訊(分割+轉錄) Args: mp3_path (str): 輸入音訊路徑 prompt (str): 轉錄提示 output_dir (str): 暫存目錄 流程: 1. 創建暫存目錄 2. 分割音訊為多段 3. 逐段轉錄 4. 合併結果並刪除暫存 """ output_dir = Path(output_dir).resolve() output_dir.mkdir(parents=True, exist_ok=True) split_files = split_mp3_file(mp3_path, output_dir) transcripts = [] logging.info("開始轉錄所有片段...") for file in split_files: text = transcribe_audio(str(file), prompt=prompt) transcripts.append(f"==== {file.name} ====\n{text}\n") file.unlink() # 刪除暫存音訊 # 儲存最終結果 output_txt = Path(mp3_path).with_suffix('.txt') with open(output_txt, 'w', encoding='utf-8') as f: f.write('\n'.join(transcripts)) logging.info(f"轉錄完成:{output_txt.resolve()}") # === 命令行參數解析 === def main(): """命令行工具主函式 使用 argparse 建立五種子命令: 1. 轉錄單一音訊 2. 合併 MP4 影片 3. 格式轉換 MP4→MP3 4. 分割長音訊 5. 長音訊端到端處理 """ parser = argparse.ArgumentParser(description="音訊/影片處理工具") subparsers = parser.add_subparsers(dest="command", required=True) # 1. 轉錄音訊 transcribe_parser = subparsers.add_parser("transcribe", help="轉錄單一音訊") transcribe_parser.add_argument("audio_path", type=str, help="音訊檔案路徑") transcribe_parser.add_argument("--prompt", type=str, default="Transcribe the audio", help="轉錄提示") transcribe_parser.add_argument("--language", type=str, default="zh", help="語言代碼(zh/eng 等)") # 2. 合併影片 merge_parser = subparsers.add_parser("merge", help="合併 MP4 影片") merge_parser.add_argument("output_path", type=str, help="輸出影片路徑") merge_parser.add_argument("input_paths", nargs="+", help="多個輸入影片路徑") # 3. 格式轉換 convert_parser = subparsers.add_parser("convert", help="MP4 轉 MP3") convert_parser.add_argument("mp4_path", type=str, help="輸入 MP4 檔案") convert_parser.add_argument("--output_dir", type=str, default=".", help="輸出目錄") # 4. 分割音訊 split_parser = subparsers.add_parser("split", help="分割長音訊") split_parser.add_argument("mp3_path", type=str, help="輸入音訊路徑") split_parser.add_argument("--output_dir", type=str, default=".", help="輸出目錄") split_parser.add_argument("--slice_len", type=int, default=1200, help="每段秒數(預設 1200 秒/20 分鐘)") split_parser.add_argument("--overlap", type=int, default=60, help="重疊秒數(預設 60 秒)") # 5. 長音訊端到端 long_transcribe_parser = subparsers.add_parser("transcribe_long", help="處理長音訊") long_transcribe_parser.add_argument("mp3_path", type=str, help="輸入音訊路徑") long_transcribe_parser.add_argument("prompt", type=str, help="轉錄提示") long_transcribe_parser.add_argument("--output_dir", type=str, default="temp", help="暫存目錄路徑") args = parser.parse_args() check_ffmpeg_installed() # 預先檢查 FFmpeg if args.command == "transcribe": text = transcribe_audio(args.audio_path, args.language, args.prompt) print(text) elif args.command == "merge": merge_mp4_files(args.input_paths, args.output_path) elif args.command == "convert": convert_mp4_to_mp3(args.mp4_path, args.output_dir) elif args.command == "split": split_mp3_file(args.mp3_path, args.output_dir, args.slice_len, args.overlap) elif args.command == "transcribe_long": transcribe_long_audio(args.mp3_path, args.prompt, args.output_dir) if __name__ == "__main__": main()