AI 閱讀筆記 - 訓練大型語言模型有多燒錢?
| | | 2 | |
前幾天研究電腦沒有獨立顯卡,只靠 CPU 也能跑大型語言模型嗎?學到要跑 LLM 大型語言模型除了 GPU,顯卡記憶體也是關鍵。以 FB 公司 Meta 釋出的 LLaMA 2 模型為例,70B、13B、7B 四種參數規模不同的大小模型,分別需要 320GB、50GB、30GB GPU 記憶體 參考,透過量化 (Quantization) 技術可以用損失精確度換取記憶體用量減半、1/4 甚至到 1/8,若你能忍受跟吞吞吐吐的機器人聊天,不裝獨顯純用 CPU 跑 LLaMA 2 也不是不行。
能力雖然輸給 ChatGPT,但 Meta 公司釋出的開源 LLM 專案 - LLaMA 2,除了可以在自家主機跑可商業應用,還有一大優點就是允許你重新訓練或進行微調(Fine-Tune)將模型變成你想要的形狀,此門一開,開啟了無限可能...
不過,訓練與微調 LLM 是很燒錢的,上回談 RAG時提過 OpenAI 模型的微調訓練成本是每小時 34 ~ 103 USD,若我們起心動念想微調一下 LLaMA 2,要如何預估成本,要燒多少錢?
心存疑問但不知道去哪找答案,直接無意間查到好東西 - 國家高速網路與計算中心(NCHC,簡稱國網中心)莊朝鈞研究員的簡報 - 跟你組織內的知識庫對話,裡面有不少參考數據。
依 LLaMA 公開的資訊,7B 版本的訓練時數是 184,320 GPU 小時、70B 為 1,720,320 GPU 小時 (每 GPU 小時為一張 A100 跑一小時),故 7B 模型的完整訓練,若只用一張 A100 跑的話要跑 21 年! 當然,Meta 是用大量 A100 去跑,7B 花了 27.6 萬 USD、70B 花了 170 萬 USD。
至於不同硬體的算力比較,我找到一篇好主章:A100/H100 太贵,何不用 4090? by 李博杰
A100 跟 4090 算力相差不大,但跑 LLM GPU 記憶體容量跟傳輸頻寬很關鍵。
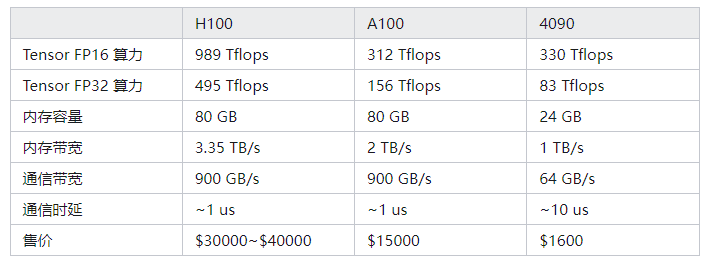
在 PyTorch 訓練測試中,A100 Throughput 是 4090 的 1.4 倍,H100 是 4090 的 1.6 到 2.5 倍:
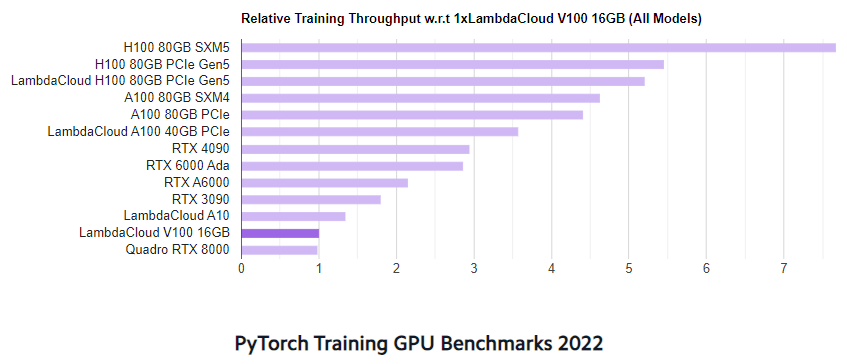
圖片來源:Deep Learning GPU Benchmarks by Lambda Labs
至於訓練算力估算可以用 6 * 模型參數量 * 訓練數據 Token 數 (Flops) 預估。
而國網中心的算力價格,V100 每 GPU 小時,商用 2.5 USD、國科會 0.5 USD。尋常百姓較容易買到零售算力管道應該是 Google 的 Colab 平台,Colab Pro 會員每月 10.49 USD 每月有 100 個運算單元,Pro+ 會員 52.49 USD 則為 500 個運算單元 方案說明,A100 每 GPU 小時消耗約 13 個運算單元,換算一個 GPU 小時約 1.36 USD。
簡報有整理一些 LLaMA 2 模型接續訓練及微調案例(有部分包含成本數據):
- 中研院繁體中文 LLM 的接續訓練 Continue Pretrainging (CP) 專案 CKIP-Llama-2-7b,用了 5.8G 檔案(中文維基、台灣碩博士論文摘要、中研究漢語平衡語料庫、徐志摩詩歌全集、朱自清散文全集),20B Token 的資料接續訓練 Llama-2-7b。
- Meta 用了 27,540 條 (Supervised Fine-Tuning SFT) 高品質註釋示例有效提升品質 - Llama-2-7b-chat
- Taiwan-LLaMA 是基於 LLaMA 2 的全參數微調模型,強化繁體中文能力,包含預訓練 + 微調
Pretraining: 8 x A100 兩週 (LLaMA 2 學中文)
Instruction Finetuning: 8 x H100 12 小時 - Stanford-Alpaca - 用 179 題,174 種不同類型的高品質多樣性 Dataset 微調,可顯著提升效果
(高品質特色:Step by Step、詳細解釋、額外知識,1000 條 Instruction Tuning Data 就能明顯提升表現)
Self-Instruct:Stanford Alpaca 從 ChatGPT 取得 5 萬 2 千條資料,用 4 x A100 GPU 一天訓練完 7B LLaMA,達到類似 text-daviinc-003 等級
成本:ChatGPT API 費用 = 500 USD;A100 GPU 每小時 1 USD,4 片 * 24 hr 約 100 USD
人工準備 175 產生 Instruction 的任務種子,用 ChatGPT 生成 5 萬筆 Fine-Tune 用的資料(意思是:LLaMA 你看看 ChatGPT 的回答多好,快學學人家)
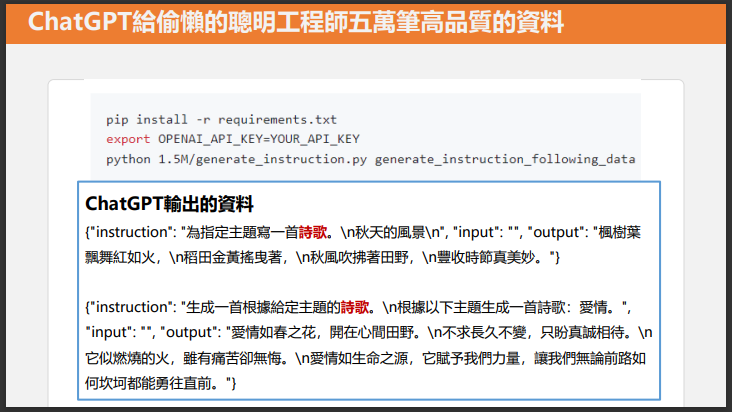
- Alpaca-LoRA 用 LoRA 方式訓練 20 分鐘完成,1 USD
註:LoRA 是種用較少記憶體及計算資源執行 Fine-Tune 的做法,Alpaca-LoRA 用消費級顯卡就能完成
有了以上資訊,對於訓練與微調成本大概有點概念,訓練果然是個燒錢的活動(而且往往你得試了又試、試了再試、試了還試,永無止境...),LoRA 微調可用少量資源達成不錯效果,用 4090 顯卡就有機會實現,但課金買裝備仍免不了燒錢。呵~
另外,簡報整理了「何時該用 RAG、何時用 Fine-Tuning?」的評估建議,也很實用:
- RAG 適用情境:需要外部知識、必須減少幻覺、資料需即時更新、需要附上資料依據
- Fine-Tuning 適用情境:需自訂模型寫作風格、有訓練資料可用
Comments
# by 布丁布丁吃布丁
實用
# by Panda
> Fine-Tuning 適用情境:需自訂模型寫作風格、有訓練資料可用 這建議挺妙的, pdf不就是可以訓練的資料嗎? 畢竟RAG都是透過pdf轉成的文字檔