GUID 叢集索引測試 2:索引碎片化分析與資料表虛胖問題
| | | 6 | |
上篇我們觀察到用 GUID 做為叢集索引,INSERT 耗時較久且偶發慢到 4 ~ 6 秒的狀況。
依直覺索引碎片化的影響主要在於讀寫效能不佳(要走過更多資料分頁),但觀察容量計時我發現另一件有趣的事,同樣是一千萬筆資料,IntClustIdx 比 GuidClustIdx 多一個 BIGINT 欄位,每筆資料多 8 Bytes (2035 vs 2027),但 IntClustIdx 用的空間比較少,只有 27 GB,少一個欄位的 GuidClustIdx 反而用掉 40GB,這是怎麼一回事?
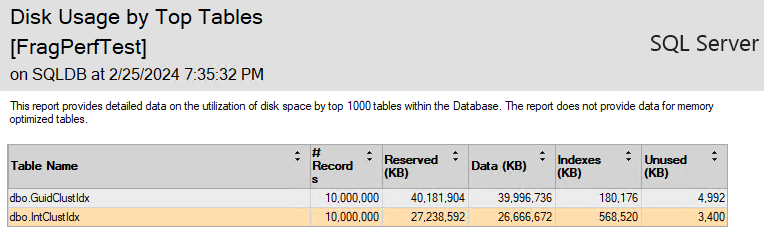
這也與叢集索引碎片化有關。
由於 GUID 無連續性,INSERT 資料時會導致 Page Split,拆分為兩個分頁並將資料拆成 50/50,各使用一半空間 (Internal Fragmentation)。
要觀察索引碎片化狀態,dm_db_index_physical_stats 是最效的指標。(相關背景知識可參見保哥文章:讓 SQL Server 告訴你有哪些索引應該被重建或重組)
使用 dm_db_index_physical_stats 查詢索引碎裂狀態,我們可以得到兩項重要指標:avg_fragmentation_in_percent、avg_page_space_used_in_percent。
avg_fragmentation_in_percent 可視為碎片化的程度。Logical fragmentation 官方翻譯為邏輯片段,我覺得譯成「邏輯碎片」更體切,指的是索引資料分頁邏輯順序與實體順序不一致,邏輯上依索引順序應該連續的資料分頁,被放在不連續的實體位置,如此存取將需要更多 IO 動作,拖慢效能。此值介於 10 到 15 之間時建議做索引重組,大於 15 時應考慮進行索引重建。
avg_page_space_used_in_percent 則是資料分頁存放資料的比率,比例過低將造成空間浪費(本案例的狀況),代表要走訪更多分頁才能蒐集完所需要資料,勢必影響效能。這個值介於 60 到 75 之間時建議做索引重組,低於 60 時應考慮索引重建。
以下 SQL 指令修改自保哥文章,增加顯示筆數與每筆資料長度:
SELECT OBJECT_NAME(dt.object_id),
si.name,
dt.index_level,
dt.avg_fragmentation_in_percent,
dt.avg_page_space_used_in_percent,
dt.record_count,
dt.avg_record_size_in_bytes
FROM
(SELECT object_id,
index_id,
index_level,
avg_fragmentation_in_percent,
avg_page_space_used_in_percent,
record_count,
avg_record_size_in_bytes
FROM sys.dm_db_index_physical_stats (DB_ID(), NULL, NULL, NULL, 'DETAILED')
WHERE index_id <> 0
) AS dt --does not return information about heaps
INNER JOIN sys.indexes si
ON si.object_id = dt.object_id
AND si.index_id = dt.index_id
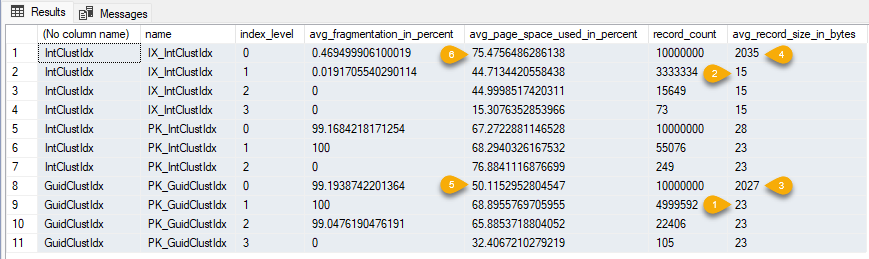
利用這個機會,來研究其中數字的奧祕。非 Leaf Page (index_level > 0) 的每筆索引長度(avg_record_size_in_bytes) 為什麼是 23 [1] 及 15 [2]?
由官方文件:Index_Row_Size = Fixed_Key_Size + Variable_Key_Size + Index_Null_Bitmap + 1 (for row header overhead of an index row) + 6 (for the child page ID pointer),當索引沒有 Nullable 欄位,Index_Null_Bitmap = 0,因此 GuidClustIdx 為 16 (Uniqueidentity 長度) + 1 + 6 = 23,IntClustIdx 為 8 (Bigint 長度) + 1 + 6 = 15。
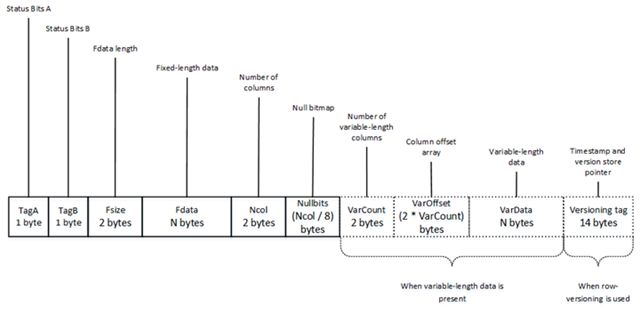
至於叢集索引的 Leaf Page (index_level == 0) 會實際儲存資料內容,其結構為 TagA (1) + TagB (1) + Fsize (2) + Fdata (N, 固定欄位資料) + Ncol (2) + Nullbits (Ncol/8) + VarCount (2) + VarOffset (2*VarCount) + VarData(N) + VersioningTag (14 或 0),LongText 欄位為長度 1000 的字串,以 Unicode 編碼儲存為 2000 Bytes。故 GuidClustIdx 資料列長度為 1 + 1 + 2 + 16(PK) + 2 + 1 + 2 + 2 + 2000 = 2027 [3],IntClustIdx 長度為 1 + 1 + 2 + 8(SeqNo) + 16(PK) + 2 + 1 + 2 + 2 + 2000 = 2035 [4]。詳細計算方式
由此推估,使用 GUID 叢集索引的問題在於碎片化造成資料分散在兩倍以上數量的資料分頁(Data Page),每個分頁只咬半口,浪費空間是一回事,需走訪更多資料分頁影響效能是更嚴重的問題。每筆 2027 Bytes * 1000 萬筆理應 20GB,因資料分頁利用率 50% [5],故實際佔用容量加倍成為 40GB。而 IntClustIdx 資料表資料分頁利用率 75% [5],20G / 0.75 = 27G。
追根究根,避用 GUID 當叢集索引是解緩索引碎片化的治本之道,但異動 Schema 工程浩大,不是所有系統都能配合修改,此時只能寄望索引重組或索引重建改善。
很少有機會做出這個規模的測試資料,順便試試 120GB 3000 萬筆資料索引重建要花多久?我測了 ALTER INDEX PK_GuidClustIdx ON GuidClustIdx REBUILD WITH (ONLINE = ON) (線上模式,索引作業期間可讓並行使用者存取基礎資料表、叢集索引資料,及任何關聯的非叢集索引。但耗時會比較久且過程效能也會下降)
索引重建前,破碎比例 99%,空間使用率 50%,耗用空間 120GB:
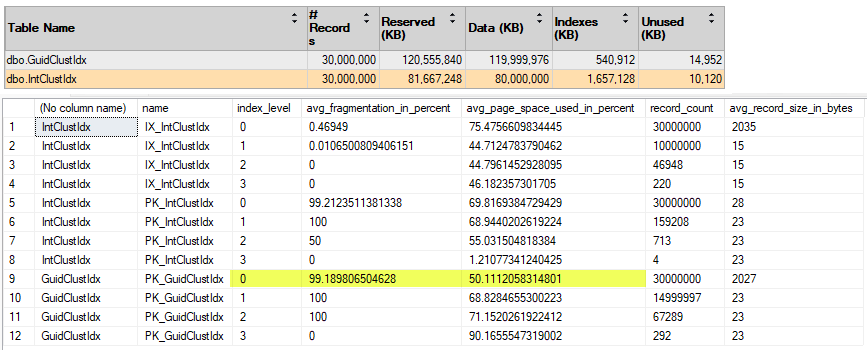
實測線上重建三千萬筆資料叢集索引共耗時 15'50"。重建後,使用空間下降到 80G,破碎比例 0%,空間使用率上升到一般標準 75%。

最後來研究索引各層的筆數(Record Count)。
下圖是另一次 1000 萬筆測試的 dm_db_index_physical_stats 查詢結果,我在最後補了兩個欄位,每頁實際筆數 = record count / page count,每頁實際筆數 = 每頁實際筆數 / avg page space used %:
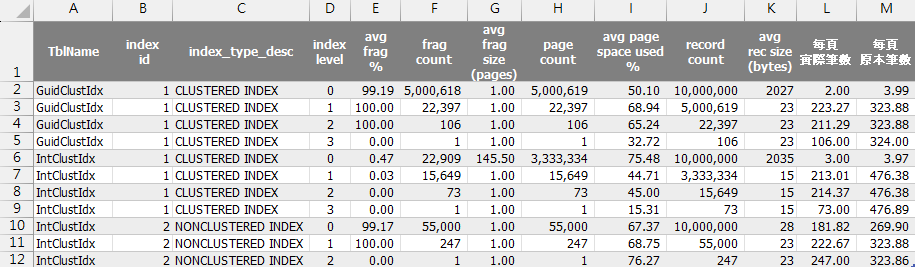
在上圖中,我們可以看到 GuidClustIdx 跟 IntClustIdx 的叢集索引都是四層,Leaf 層(Level 0)都是 1000 萬筆,但 Level 1,GuidClustIdx 為 5000619 筆,IntClustIdx 為 3333334 筆,Level 2 為 22397 vs 15549。
SQL 採用 B+ 樹結構:
(延伸閱讀與下圖來源:資料庫層的核心 - 索引結構演化論 B+樹 by 拿鐵派的馬克)
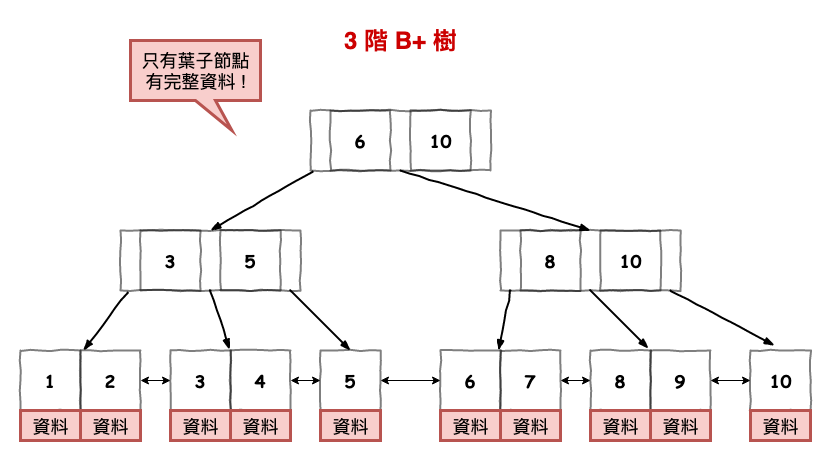
依據官方文件算出非 Leaf 層每個 Page 可以容納的索引資料列數為 Index_Rows_Per_Page = 8096 / (Index_Row_Size + 2),故可得 Guid 叢集索引為 8096 / (23 + 2) = 322、BIGINT 叢集索引為 8096 / (15 + 2) = 474,這數字很接近【每頁原本筆數】(該欄位依實際狀況反推,每頁有多有少,故不會完全相等),而下層可容納最多索引資數為上層的 322 及 474 倍,故 Level - 1 是 Level 層的 322/474 倍,322/474 為理論值,實際數字要用【每頁實際筆數】計算,GuidClustIdx 可得 106 * 211.29 = 22397,22397 * 223.27 = 5000619;IntClustIdx 為 73 * 214.37 = 15649、15649 * 213.006 = 3333334,數字就對上了。
而 Leaf 層每頁可容納筆數的算法為 Rows_Per_Page = 8096 / (Row_Size + 2),用 2027 或 2035 算約 3.9,依使用率 50.10%、75.48% 推算每頁 2 及 3 筆,Leaf 層筆數為 1000 萬,除以 2 及 3 便是 GuidClustIdx 與 IntClustIdx Level = 1 層 5000619 與 3333334 的由來。而依此估算,當 GuidClustIdx 資料超過 322^3 (約 3339 萬筆) 時,索引結構會用到五層,如下圖:(測試環境六千萬筆 dm_db_index_physical_stats (DB_ID(), NULL, NULL, NULL, 'DETAILED') 要跑五分多鐘)

既然跑了實驗,順便附上一口氣跑 3400 萬筆 INSERT 的測試數據:

再累積一些索引碎片化知識。
The web page shows that using GUID causes more fragmentation, lower page space utilization, and slower INSERT performance than using BIGINT. It also explains the structure and size of the index rows and data pages, and how they affect the storage space and efficiency.
Comments
# by Anonymous
好文! 比書籍會寫的內容好上 100 倍 希望黑大多類似的文章(很厚顏
# by SSS
請問黑大這樣還會推薦使用 GUID 當索引嗎?
# by 小黑
這篇很頂
# by Jeffrey
to SSS, 另設自動跳號 INT/BIGINT 當叢集索引,GUID 設非叢集索引當 Primary Key (如 IntClustIdx 資料表的設計) 就能享受 GUID PK 的優點又避免索引碎片化問題,詳情可參考前一篇文章跟「GUID Primary Key資料庫避雷守則」
# by steven211
優質文 我們家是tb級sql server 有用uuid當PK也遇過慘痛的效能問題 新寫的也會避免uuid當PK 不過我與3RD廠商進行資料串接還是喜歡用UUID 不過近年分散式db大流行 uuid變得非常好用
# by Jeffrey
to steven211,好奇一問,效能悲劇是因為 GUID PK 兼叢集索引嗎?我的理解是另設自動跳號當叢集索引 GUID 專心當 PK,應該頂得著 TB 級資料庫才對。