閱讀筆記 - LLM 模型發展歷程基本知識
 |  | 2 |  |
ChatGPT 帶起大型語言模型(LLM)熱潮,對程式開發產業帶來無法忽視的衝搫。有程式需求但不會寫?跟 ChatGPT 許願就有。一行行敲程式碼太慢?Github Copilot 知道你想做什麼,自動幫你寫完。C# 老鳥遇到適合用其他語言開發的情境,不需要抱著 .NET 硬幹,有 Github Copilot 當靠山,切換不同語言快速寫完小需求是小菜一碟,近期寫 Pyhon 算百分數畫圖表及用 Node.js 寫 WebAPI的經驗即可為證。AI 出現,程式開發生態自此改變。
在這個基礎程式開發能力不再值錢的時代,程式老鳥的傳統領先優勢逐步消失,想繼續保有競爭力需要調整技能樹配置,我認為整合 LLM 的應用程式開發是極具潛力的新領域,也是我近期會投注心力的發展方向。
在安德魯 RAG 的檢索與應用一文看到 AWS 生成式 AI 技術負責人,Aishwarya Naresh Reganti,提供的免費線上課程 - Applied LLMs Mastery 2024 / 精通 LLM 應用,講得不深(但不代表淺顯,文章用詞精簡,有些地方需要機器學習及程式開發背景才易理解)但涵蓋很廣,將 LLM 應用開發的工具技術、開發策略、部署調校,乃至於安全法規道德性一網打盡,也有附上想深入研究的論文連結,大概是「絕世武功目錄」的概念,讀完或能在此 AI 革命狂潮中博個九死一生。(笑)
課程裡有一堂在講 LLM 背後機器學習技術的演進挺有意思,看完至少對 LLM 相關的專業術語會有基本認識,故這篇就花點時間簡單筆記整理備忘。
機器學習模型可區分成:生成式(Generative)及鑑別式(Discriminative)兩大類。LLM 屬於前者,透過從資料中學習如何依據輸入資料生成對映的資料(文字、影像、聲音...);而鑑別式模型則可依據輸入資料決定結果(例如:分類、是或否)或產生預測。
RNN
要訓練可生成文字的模型,最早是使用 Recurrent Neural Network (RNN,循環神經網路)。
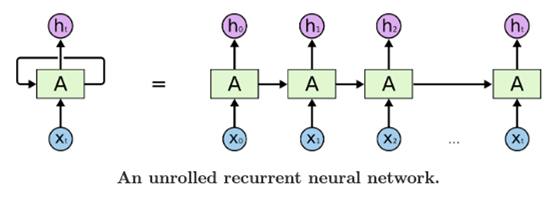
RNN 的特色是輸入 Xt 時,會依指定權重結合狀態資料 ht-1 產生 ht,進而計算出 yt(可用於分類、預測或序列資料生成),最終得到先前一段範圍的輸入影響當前輸出的效果。但 RNN 有難以參考長範圍資料以及梯度爆炸或消失問題,故後來出現了 RNN 的變形,例如:Long Short-Term Memory (LSTM) 及 Gated Recurrent Units (GRUs) 以克服無法參照大範圍資料及梯度相關問題。
LSTM
LSTM 在模型加入了 Memory Cell 以長期記憶資訊,其使用三個 Gate (Input/Output/Forget) 控制資訊流入/流出 Memory Cell 或遺忘,藉此處理更長範圍的資料(RNN 只會參考 t-1,LSTM 用 Gate 控制故能記住很久)。
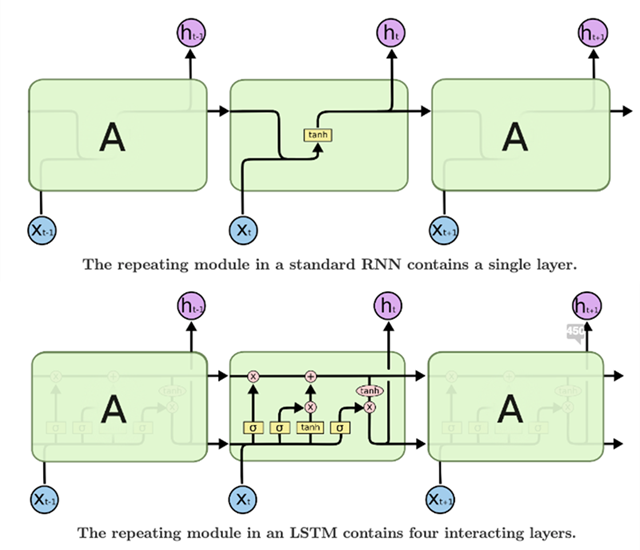
RNN 跟 LSTM 被廣泛應用在語言模型任務上,用來預測下一個輸出的字。但在處理輸入長度與輸出長度可變的情境,其固定長度的隱藏狀態保留機制,侷限了能力。
延伸學習:李宏毅老師 機器學習線上課程:RNN & LSTM (下圖為 LSTM 更詳細的分解)
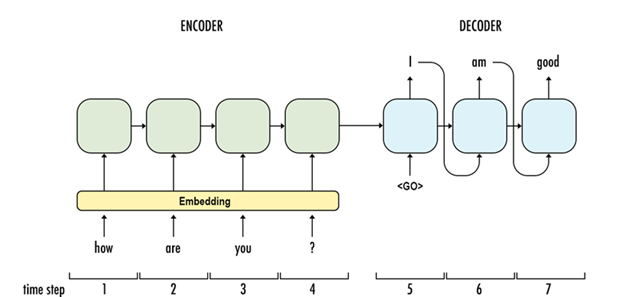
Seq2seq
Sequence-to-Sequence (Seq2seq) 模型採用 Encoder - Decoder 設計,文字經 Embedding轉成固定維度向量輸入到 Encoder,Encoder 串接 Decoder 輸出結果,輸出的第一個文字做為輸入決定第二個輸出文字,以此類推。自此,模型能處理可變長度的內容,並有效補捉語意產生相關結果,圖中的每個單元仍是 RNN 架構。
Seq2seq with Attention
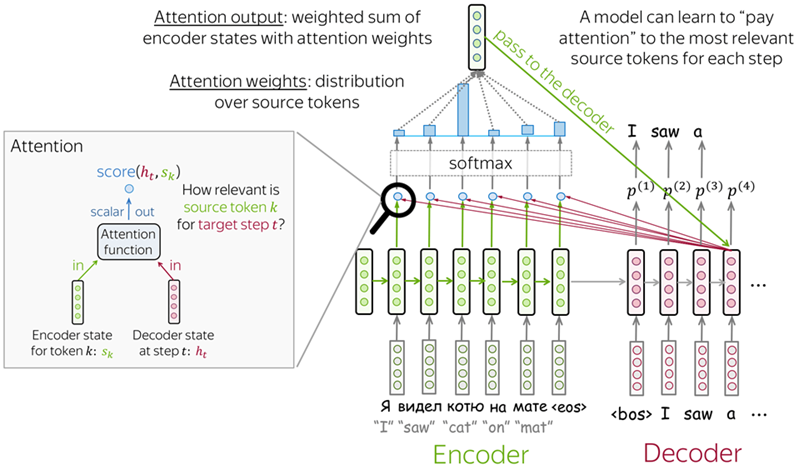
Seq2seq 有個問題是所有輸入資料最後轉成單一向量,無法突顯其中重要部分,使其產生較大影響。Seq2seq Model with Attention 改良模型加入注意力機制,試圖改善此一問題。在 Decoder 階段,由接收 Encoder 最後輸出改為考慮 Encoder 所有 RNN 狀態(s1, s1 ... sm),由 Attention Function 調配每個 sk 與 ht 相關度計算 score(ht, sk),得到象徵重要性的 Attention Score,以該評分作為權重計算輸出,如此輸出便能專注在重要部分。
Transformer
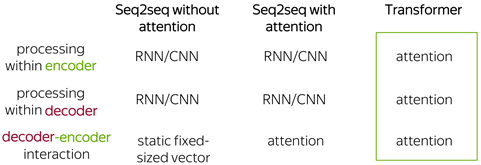
Seq2seq Model with Attention 仍存在計算效率差及無法有效捕捉長序列相依性的問題,Google 在 2017 發表了著名的 Attension is All You Need 論文,Transformer 模型自此成為當今 LLM 主流。
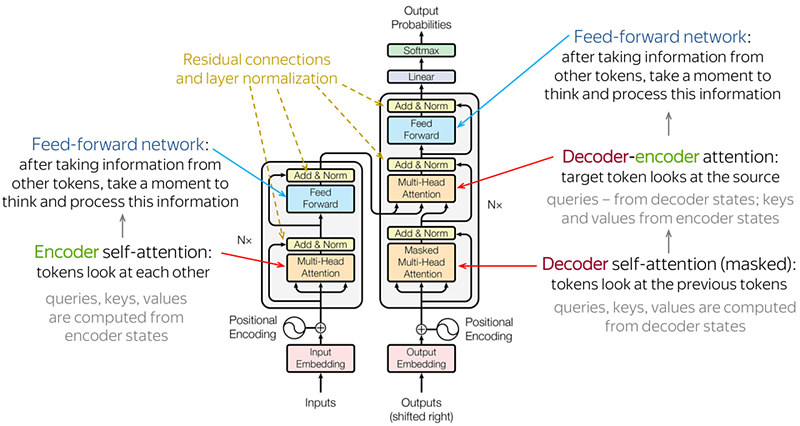
Trasformer 使用 Self-Attention 機制(Mutli-Head Attention Block)在 Encoder / Decoder 階段都考量整個 Sequence,增加值得注意部分的權重,如此能用更少訓練時間得到更好的結果。
Transformer 被廣泛應用在語言模型,目前檯面上的 LLM,如 BERT、GPT、LLaMa、Mistral、Gemini、Claude 清一色都是採用 Transformer 模型,儼然已成業界標準。
延伸學習:
早期語言模型
遠在 ChatGPT 一砲而紅前,已有一些模型如 BERT (Bidirectional Encoder Representations from Transformers)、GPT (Generative Pre-trained Transformer)、T5 (Text-To-Text Transfer Transformer) 發展多年,他們都是基於 Transformer,透過以下步驟建構:
- Pre-Train 與 Fine-Tune:先使用大量語料進行預訓練,熟悉語言表達及基本知識,再使用標示資料(Labeled Data)針對不同 NLP (自然語言處理)任務微調,例如:文字分類、問答、機器翻譯等。
- Bidirectional Context:BERT 使用雙向上下文模型,使其能做到更深的語意捕捉,提升表現。
- Autoregressive Generation:GPT 利用先前生成元素作為上下文來預測下一個元素(自迴歸生成),能很好地產生流暢有結構的文字內容。
- Text-to-Text Approach:T5 用統一的 Text-to-Text 框架對應不同的 NLP 任務,簡化訓練及部署程序,並能滿足各項任務需求。
- Large-Scale Training:這些模型使用數十億 Token 規模的資料集訓練,使用大量算力硬體及分散式技術完成,在語意捕捉能力上有很大的進步。
大型語言模型 LLM
近期的 LLM 如 Llama 及 ChatGPT,與 BERT、GPT 相比,有以下提升:
- 任務導向:BERT 及 GPT 屬多用途,可用於分類、語言產生、問答,而 Llama 主打多模態(涵蓋文字、影像),ChatGPT 專注對話應用。
- 多模態:Llama 及 Gemini 等模型主打 Multimodal 多模態,可支援文字、聲音、影像應用。
- 效率提升:能用較少參數達到相似效果。
- 允許針對特定領域知識進行微調(Fine-Tune),結合預訓練資料在專屬應用上有更好表現。
- 互動及動態回應:擅長依據互動交談內容,動態產生人類預期的回應內容。
Comments
# by Allen C.
本文中的 Genimi 應該是 Gemini ? 謝謝黑大的分享 ~
# by Jeffrey
to Allen C. 修正了,感謝!