物件序列化之舉手之勞省空間
 |  | 5 |  |  |
分享一下最近學會的序列化壓縮技巧。
情境如下,查詢資料庫後取得List<User>物件,打算透過序列化成檔案的方式保存,方便日後能快速還原回List<User>查詢比對,以達到離線使用的目標。
在.NET要玩序列化不過是小事一樁,只要針對類別建構出DataContractSerializer物件,再搭配FileStream,一個SerializeObject()指令就能將物件儲存成檔案,還原時也只要一個Read()指令就搞定,十分方便。
以下程式模擬了一個20萬筆資料的巨型集合物件 -- List<User>,以DataContractSerializer序列化為檔案,再反序列化回List<User>,並抽樣檢查還原的第1024筆資料,比對是否與序列化前相同,以確認資料正確無損。
using System; using System.Collections.Generic; using System.Diagnostics; using System.IO; using System.Linq; using System.Runtime.Serialization; using System.Text; namespace ZipSer { internal class Program
{ private static void Main(string[] args)
{ //隨機假造20萬筆User資料 List<User> bigList = GenSimData();
string fileName = "serialized.data";
int indexToTest = 1024; //用來比對測試的筆數
//序列化前取出第indexToTest筆資料的顯示內容 string beforeSer = bigList[indexToTest].Display, afterDeser = null; DataContractSerializer dcs =
new DataContractSerializer(bigList.GetType()); Stopwatch sw = new Stopwatch(); sw.Start();
//將List<User>序列化後寫入檔案 using (FileStream stm = new FileStream(fileName, FileMode.Create)) { dcs.WriteObject(stm, bigList);
}
sw.Stop();
Console.WriteLine("Serialization: {0:N0}ms", sw.ElapsedMilliseconds); sw.Reset();
sw.Start();
//由檔案反序列化還原回List<User> using (FileStream stm = new FileStream(fileName, FileMode.Open)) { //還原後一樣取出第indexToTest筆的User顯示內容 afterDeser =
(dcs.ReadObject(stm) as List<User>)[indexToTest].Display; }
sw.Stop();
Console.WriteLine("Deserialization: {0:N0}ms", sw.ElapsedMilliseconds); //比對還原後的資料是否相同 Console.WriteLine("Before: {0}", beforeSer); Console.WriteLine("After: {0}", afterDeser); Console.WriteLine("Pass Test: {0}", beforeSer.Equals(afterDeser)); Console.Read();
}
private static List<User> GenSimData()
{ List<User> lst = new List<User>(); Random rnd = new Random(); for (int i = 0; i < 200000; i++)
{ lst.Add(new User() { Id = Guid.NewGuid(),
RegDate =
DateTime.Today.AddDays(-rnd.Next(5000)),
Name = "User" + i, Score = rnd.Next(65535)
});
}
return lst; }
[Serializable]
private class User
{ public Guid Id { get; set; } public DateTime RegDate { get; set; } public string Name { get; set; }
public decimal Score { get; set; }
public string Display
{ get
{ return string.Format(
"{0} / {1:yyyy-MM-dd} / {2:N0}", Name, RegDate, Score);
}
}
}
}
}
執行結果如下:
Serialization: 2,349ms
Deserialization: 2,953ms
Before: User1024 / 2001-07-22 / 43,320
After: User1024 / 2001-07-22 / 43,320
Pass Test: True
序列化及反序列化的速度都蠻快的,花不到3秒,但有個問題:
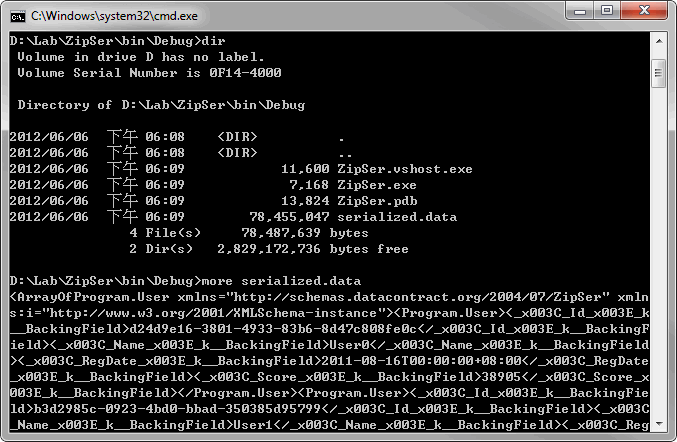
序列化後的serialized.data檔案大小高達78MB!! 檔案痴肥是開發人員不夠專業的象徵,所以就快來研究如何改善吧!
要減少序列化後的體積,自訂更有效率的序列化邏輯是一種解決;而我看到序列化後的內容接近文字形式,則有另一個點子,何不在序列化存檔前進行壓縮縮小體積;在還原時,則讀檔後先解壓縮再做反序列化? 在種內容接近文字的情境,應能省下可觀空間,實做起來也會比自訂序列化邏輯簡單許多。
簡單嘗試後,發現GZipStream的設計概念很棒,我們只需為FileStream包上一層GZipStream,然後將WriteObject()及Read()的資料串流對象由FileStream改成GZipStream,只改個兩行程式,馬上就有壓縮/解壓縮功能!!
sw.Start();
//將List<User>序列化後寫入檔案 using (FileStream stm = new FileStream(fileName, FileMode.Create)) { //用GZipStream把FileStream包起來 using (GZipStream zip = new GZipStream(stm, CompressionMode.Compress)) { //序列化結果改寫入GZipStream dcs.WriteObject(zip, bigList);
}
}
sw.Stop();
Console.WriteLine("Serialization: {0:N0}ms", sw.ElapsedMilliseconds); sw.Reset();
sw.Start();
//由檔案反序列化還原回List<User> using (FileStream stm = new FileStream(fileName, FileMode.Open)) { //一樣用GZipStream把FileStream包起來 using (GZipStream zip = new GZipStream(stm, CompressionMode.Decompress)) { //還原的二進位資料來源改為GZipStream afterDeser =
(dcs.ReadObject(zip) as List<User>)[indexToTest].Display; }
}
sw.Stop();
Console.WriteLine("Deserialization: {0:N0}ms", sw.ElapsedMilliseconds); 測試結果,加入壓縮解壓程序後,執行時間略為增加(也只多出不到2秒),比對測試則驗證還原後資料無損。
Serialization: 4,072ms
Deserialization: 3,801ms
Before: User1024 / 2007-08-25 / 791
After: User1024 / 2007-08-25 / 791
Pass Test: True
接著來驗收壓縮成果,原本78.5MB的檔案,壓縮後只剩11.3MB,縮小為14%。
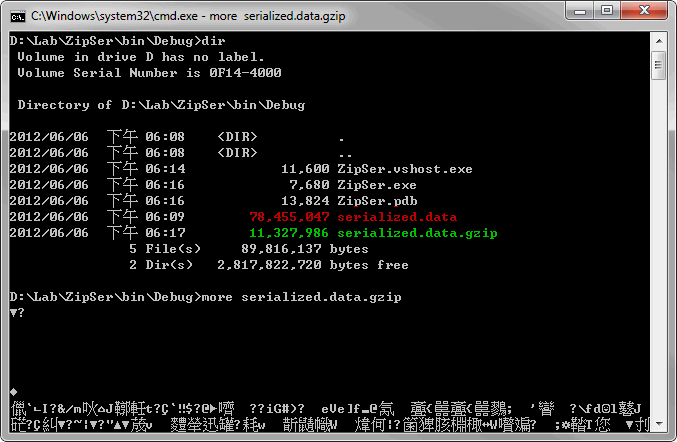
只用幾行程式,就讓序列化增加了壓縮功能,又到了該為.NET歡呼的時刻,讚啦!!!
Comments
# by Laneser
這個 GzipStream 我只有遇到一個地雷...就是壓縮之前大小不能超過 4GB ...
# by 蹂躪
那個限制在4.0就拿掉了
# by Ammon
為何不用 binary serialize?
# by Jeffrey
to Ammon, 有考慮過BinaryFormatter,但評估集合的資料物件有很大比例的屬性值是重複的,這部分只能透過壓縮來減少體積,使用Binary也幫不了太多忙。
# by Litfal
Deflate在C#裡面的大地雷不是4GB 是Block在太小時,壓縮率極差。 更甚者Block在某個大小時,壓縮後的體積反而誇張的增大。 (之前測試過,很奇怪的問題,用的block不大,好像是256左右,因為是測試用的程式碼,可能要找找看) 而用Stream傳遞給寫入器,最大的優點與缺點是封裝,隱藏寫入的細節,所以沒辦法知道寫入函式裡對於block如何處裡。 Serializer內容不清楚,雖然大多案例看起來沒問題,但總會害怕哪時忽然出事。 根據我實驗的結果,在建立GZipStream後,再用一層BufferedStream包起GZipStream,最後將BufferedStream指定給寫入器是比較通用的閃雷法。