Coding4Fun - Arduino/ESP u8g2 中文字庫自動化工具
| | | 12 | |
玩了一陣子 SSD1306 OLED 顯示器,也玩了幾回點陣中文字型,是時侯把它們結合在一起 - 試試在單色 OLED 上顯示中文。
之前我主要用 Adafruit 驅動程式庫接 SSD1306 OLED,其文字顯示侷限在 ASCII 字元集,要顯示 Unicode 字元,大部分人會使用 U8g2 程式庫。
u8g2 的前身是 u8glib - Universal Graphics Library for 8 Bit Embedded Systems,原作者 olikraus 另起 U8g2 Library for monochrome displays, version 2 專案,它的特色是支援各式開發板及單色顯示器(甚至含 MAX7219 8x8 LED 矩陣),不負 Universal 之名。而更令人驚喜的是,u8g2 內建字型,甚至支援中文。
我選擇用 VSCode + PlatformIO 開發,硬體則用 ESP32 開發板 + 0.96" SSD1306 I2C 介面單色 OLED,來試試用 u8g2 在 OLED 顯示中文。
在 PlatformIO / Libraries 畫面輸入 u8g2 很快可以找到它:
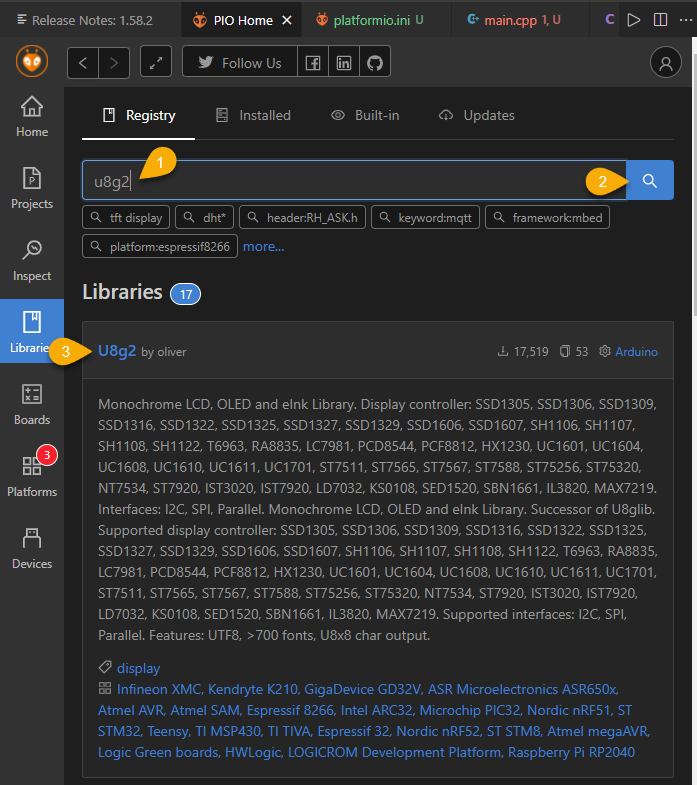
點開按【Add to Project】將其加入專案:
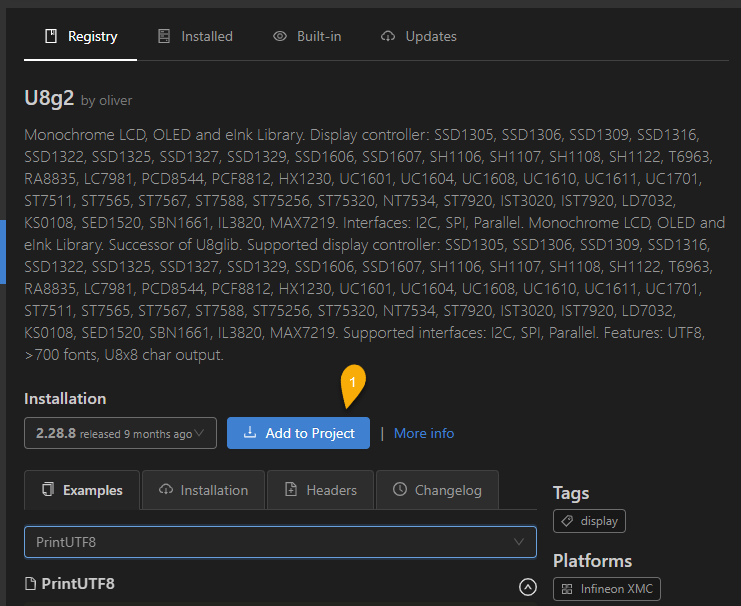
接下來,依據你的硬體宣告對映的類別,以我的 SSD1306 I2C 為例,會是 U8G2_SSD1306_128X64_NONAME_F_HW_I2C,名稱分為五節:
- 第一節 U8G2 為固定前置字串
- 第二節 SSD1306 是控制晶片名稱
- 第三節是 128X64_NAME 是解析度模式
- 第四節有 1/2/F 三種選擇,代表同時一次載入幾列緩衝區 byte[] 到實體記憶體,1、2 可節省記憶體,但需搭配 firstPage()/nextPage() 方法,但分段處理效能較差。若實體記憶體夠用,建議選 F 再搭配 clearBuffer()、sendBuffer() 使用.
- 第五節為通訊介面,有 4W_SW_SPI、4W_HW_SPI、2ND_4W_HW_SPI、3W_SW_SPI、SW_I2C、HW_I2C、2ND_HW_I2C、6800、8080 等選項。
完整硬體支援清單可以看這裡。
依照官方提供的 PrintUTF8 範例,我成功在 OLED 上印出中文:
#include <Arduino.h>
#include <Wire.h>
#include <U8g2lib.h>
U8G2_SSD1306_128X64_NONAME_1_HW_I2C u8g2(U8G2_R0, /* reset=*/ U8X8_PIN_NONE);
//for ESPro Matrix board
//U8G2_SSD1306_128X64_NONAME_F_HW_I2C u8g2(U8G2_R0, U8X8_PIN_NONE, 27, 26);
void setup()
{
Serial.begin(115200);
u8g2.begin();
u8g2.enableUTF8Print();
u8g2.setFont(u8g2_font_unifont_t_chinese2); // use chinese2 for all the glyphs of "你好世界"
u8g2.setFontDirection(0);
u8g2.clearBuffer();
u8g2.setCursor(0, 15);
u8g2.print("Hello World!");
u8g2.setCursor(0, 40);
u8g2.print("你好, 世界!");
u8g2.sendBuffer();
}
void loop()
{
}

所以,搞定收工了?
你猜對了,世界沒有想像那麼美好。Arduino/ESP 開發板記憶體跟儲存空間有限,不太可能把所有中文字型都裝進去,故 u8g2_font_unifont_t_chinese2 等字型只包含幾百個常用的簡體中文字,如果輸入中文測試只會看到中文兩個字,記錄兩個字有,但 print("記錄") 沒用,要寫簡體 print("记录") 才行。
因此,實務要顯示繁體中文字需量身訂做專用字庫。做法是先整理所有程式會顯示的中文字元,用 u8g2 提供的工具轉成專屬字型資料把替換原始程式庫的 u8g2_font_unifont_t_chinese1 換掉,程序非常繁瑣,傑森創工有篇部落格文章 - 使用u8g2函式庫建立自訂字庫,讓OLED顯示中文 有完整介紹,照做即可。
但大家都知道,性急如王藍田,我哪有可能耐著性子照著教學步驟慢慢弄:先整理用到哪些中文字元、用線上服務把中文字轉成 Unicode、把 Unicode 貼到 chinese1.map、把 \ 罝換成 $、輸入 DOS 指令產生 .c 程式碼、從 .c 選取並複製程式片段、找到程式庫原始碼把 u8g2_font_unifont_t_chinese1 byte[] 換掉... 光寫步驟我就煩躁了,更甭提每次加字整個流程得從頭來一次,想到這裡我已頭皮發麻。
沒錯,大家又猜到了。懶人如我,當然要寫段 PowerShell 將以上動作一氣喝成,把原本要花五到十分鐘的操作縮簡成一個指令一秒完成!
這個自動化工具的運作原理是 - 在專案新增一個 tool 資料夾,用 Git 下載 u8g2 專案,將其 tools\font 目錄下的 bdf、bdfconv、build 目錄複製到 tool 資料夾下。我寫了一個 make-cht-font.ps1,它負責去掃瞄 ..\src\main.cpp (如果你的顯示文字放在其他檔案,請自行調整) 出現哪些中文字元(光省掉手工撿字這段便讓我心花怒放),將字元清單自動轉成 Unicode 編碼存成 chinese1.map,再呼叫 bdfconv.exe 依據 chinese1.map 產生 u8g2_font_unifont_t_chinese1 byte[] 寫入 u8g2_font_unifont.c;原本需要自己去 u8g2_font_unifont.c 複製陣列內容,在 u8g2\src\clib\u8g2_fonts.c 尋找 u8g2_font_unifont_t_chinese1 置換的苦差事也全部交給 PowerShell 代勞。
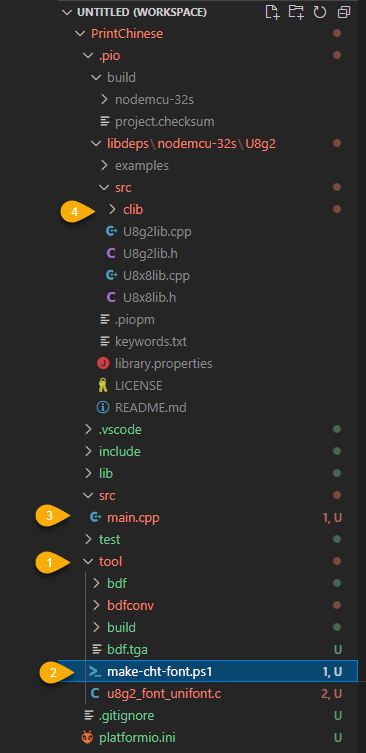
有了全自動工具,每次在 main.cpp 用到新的中文字元,只需下一行指令:.\make_cht_font.ps1,PowerShell 便會在一秒內完成前述教學文章裡的所有字庫作業,我們照標準程序編譯上傳即可,新加入的中文自然會在 OLED 出現。
神奇的自動化工具 - make_cht_font.ps1,程式只有短短幾行:
$src = Get-Content "..\src\sutra.h" -Encoding UTF8 -Raw
$uniEnc = [System.Text.Encoding]::Unicode
$uniChars = [System.Text.RegularExpressions.Regex]::Matches($src, '[^\x0a-\x7f]') |
ForEach-Object { $_.Value } | Sort-Object | Get-Unique
Write-Host "發現中文字元: "
$uniChars -join ', '
(@("32-128") + ($uniChars | ForEach-Object { '$' + ([Uint32]([char]$_)).ToString('X4') })) -join ",`n" | Out-File ".\build\chinese1.map" -Encoding utf8
# 依列舉字元表,製作 u8g2_font_unifont_t_chinese1 陣列宣告
# -b Font build mode, 0: proportional, 1: common height, 2: monospace, 3: multiple of 8
# -f Font format, 0: ucglib font, 1: u8g2 font, 2: u8g2 uncompressed 8x8 font (enforces -b 3)
# -M Read Unicode ASCII mapping from file 'mapname'
& .\bdfconv\bdfconv.exe -v ./bdf/unifont.bdf -b 0 -f 1 -M ./build/chinese1.map -d ./bdf/7x13.bdf -n u8g2_font_unifont_t_chinese1 -o u8g2_font_unifont.c
# 找到 .pio 下的 u8g2_fonts.c,將 u8g2_font_unifont_t_chinese1 內容換掉
$regexPattern = '(?ms)u8g2_font_unifont_t_chinese1\[\d+\] U8G2_FONT_SECTION.+?";\s'
$fontData = [System.Text.RegularExpressions.Regex]::Match((Get-Content "u8g2_font_unifont.c" -Encoding utf8 -Raw), $regexPattern).Value
Get-ChildItem ..\.pio -Recurse -Filter u8g2_fonts.c | ForEach-Object {
# 將 u8g2_font_unifont_t_chinese1 內容換掉
$code = Get-Content $_.FullName -Encoding utf8 -Raw
$code.Replace([System.Text.RegularExpressions.Regex]::Match($code, $regexPattern).Value, $fontData) |
Out-File $_.FullName -Encoding ascii
}
為了發揮斜槓精神,我順便練習影片剪輯、上字幕,做了一段展示影片。
自己想想也覺得好笑,我寫 Arduino 的主要樂趣好像不在結合軟硬體做出有創意的生活化應用,反而整天把腦筋花在怎麼簡化開發流程、研發輔助工具上,這算本末倒置嗎? 我不知道,反正程式寫得開心就好。
Example of using PowerShell to complete lousy u8g2 font convertion manual tasks in one second.
Comments
# by 程式小兵
真的,寫程式,開心就好。認同這句話。
# by 徐開
謝謝大大造福人群
# by J
強
# by eric
謝謝分享,先收藏應該有用。
# by cory
大大您好,我最近也在使用esp32s2要在oled上顯示中文,但是不管是我照步驟轉、還是用您這個轉 甚至我自己拿新細明體轉bdf來用,都無法正確顯示(原本的chinese1是可以顯示"中文"這兩個字的) 也確認了tga檔是正確的,但還貼到chinese1上還是無法顯示,連"中文"兩個字都不顯示了 不知道可能出錯的方向在哪裡呢? 既然一開始可以顯示"中文" 應該代表u8g2可以用在esp32s2這張板子上吧?
# by Jeffrey
to cory, 一開始我搞錯 Unicode 碼高低位元組順序,也曾出現原本 chinese1 可以顯示"中文"兩個字,換了挑字版本 chinese1 連中文兩字都不顯示的狀況,跟你說的問題一樣。後來校正錯誤,換成正確的 chinese1 才成功。 建議先按傑森創工的教學用 u8g2 官方 unifont.bdf 手工挑字轉檔做完一次,確認檔案、工具、程序都是對的,再嘗試用自動化程序。
# by EYEFOTO
您好,文中提到此法也支援max7219 8*8 led矩陣,我自己用四組max7219DIY了16*16的led矩陣,如果想套用相同的程序將輸入的中文轉換至二進制的陣列資料,具體可否指引出一個方向?因為參考過您之前的文章但因為不熟c語言而覺得卡關惹@@"
# by Jeffrey
to EYEFOTO, 這塊我沒深入研究過,但有找到有人試做過 U8G2_MAX7219_16X16_F_4W_SW_SPI ,應也是 16*16,你可以參考看看。 https://github.com/olikraus/u8g2/blob/master/sys/arduino/u8g2_full_buffer/MAX7219_U8g2/MAX7219_U8g2.ino
# by EYEFOTO
非常感謝~
# by mahbird
你好,Google搜到你這篇,真的很好用,非常感謝。 不過由於我使用習慣跟你有點不同,我以你這個工具為基礎改了一個python版本,不知你介不介意我將我改的pyhton放到github上? 會加credit到你這篇,謝謝
# by Jeffrey
to mahbird, 歡迎! Push 後可再來留言分享 Github 連結,讓需要 Python 的同學參考~
# by mahbird
感謝你,放到github上了~ https://github.com/mahbird/u8g2_chinese_convert_tool_py