用入門級顯卡 RTX 3050 + Ollama 跑小模型,會比 CPU 快多少倍?
 |  | 8 |  |  |
學會用 Ollama 有一陣子了,受限於迷你工作機只有內顯,至今都是用 CPU 跑模型,據說只要有 GPU,即便是人門款顯卡都能把 CPU 壓在地上摩擦,了解 GPU 並行運算架構就知道這是想當然爾的結果,但沒親手體驗過,總覺得少了點什麼。
趁著週末向小木頭借了他的 RTX 3050 獨顯 11 代 i7 筆電試跑 Ollama。(順便向他展示用 CLI 帥氣下指令跟用 VSCode 跑程式,加減推坑 Coding 的美麗世界 XD)
3050 屬入門級只有 4GB VRAM,但用來跑前幾天玩過的 Google Gemma 2 跟微軟的 Phi-3,模型參數量分別是 2B 及 3.8B,有機會塞進 VRAM 用 GPU 跑,夠讓我這個從沒用 GPU 跑過模型的土包子開眼界了。
Ollama 很聰明,跑模型時若有 GPU 可用會用 GPU,若沒有則會用 CPU,你都會得到結果,要怎麼確認 Ollama 是用 GPU 跑模型?一個簡便做法是載入模型後使用指令 ollama ps 查詢,Ollama 會顯示該模型大小,有多少比例使用 CPU、多少是用 GPU:

以微軟的 Phi-3 3.8B 小模型為例,phi3:mini 大小為 3.6 GB,5% 用 CPU 跑,95% 用 GPU。由工作管理員的 Nvidia GPU 資訊頁可查到類似結果:
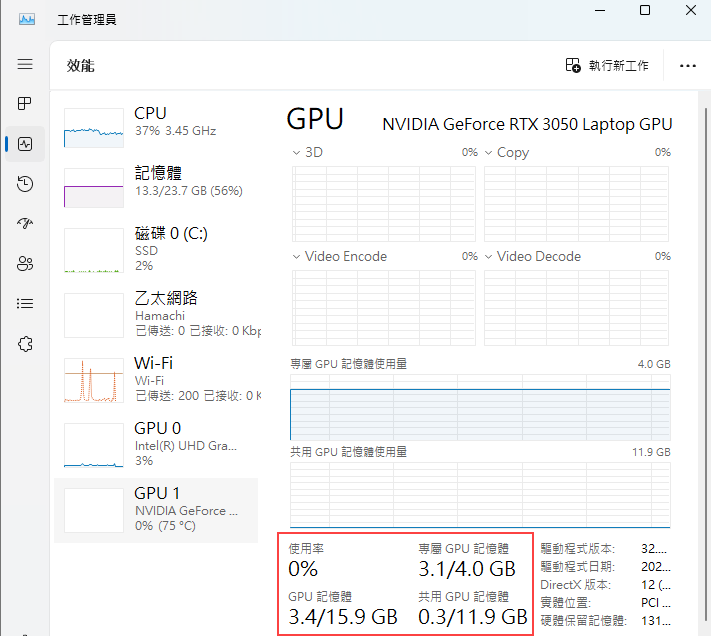
要看懂以上資訊,有個基本知識:工作管理員顯示的 GPU 資訊時有分「專屬 GPU 記憶體」跟「共用 GPU 記憶體」,前者指給 GPU 專用的記憶體,通常指焊在 GPU 晶片周圍一圈的 GDDR 高速記憶體(就在 GPU 晶片旁,距離愈近愈好),下圖為香噴噴貴森森的消費顯卡至尊 RTX 4090,GPU 晶片被 12 顆 GDDR6X (傳輸頻寬是 DDR4 的 10 倍) 記憶體眾星拱月,專屬 GPU 記憶體來到 24 GB。

照片來源:UNIKO'S HARDWARE
而「共用 GPU 記憶體」來自主機板上的實體記憶體,其中一半容量開放 GPU 跟 CPU 共用。但這不是說主機如果有 32 GB RAM,會撥 16 GB 給 GPU,其他程式只能用剩下的 16GB;而是若 GPU 需要,最多可動用 50% (16GB) 的記憶體,但這 16GB 使用上仍需與一般應用程式協調,GPU 只具有稍高優先權。
我測試的這台筆電插了 16 + 8 共 24GB RAM,GPU 為筆電版 RTX 3050 有 4GB VRAM 即專用 GPU 記憶體大小,目前用掉 3.1GB;共用記憶體 24 * 50% = 12G,用掉 0.3G。而運算分配為 GPU 95%、CPU 5%。
phi3:mini 大小為 3.6GB,照理可全部塞進 4GB VRAM,不確定為何沒法全部放進 VRAM 100% 用 GPU,我猜有可能 VRAM 不能 100% 用完,需留下一定比例的保留空間,或是 Ollama 判斷將部分 Layer 移到 CPU 運算會更有效率。
再來看 Gemma 7B 版,模型大小 7.8G (下圖[1]),其中 VRAM 用掉 2.9GB、共用 GPU RAM 用 4.8G,二者相加約 7.8G,而其運算比例 CPU 57%、GPU 43%。

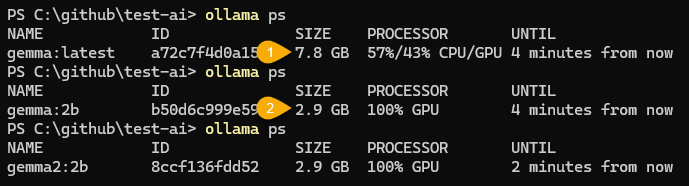
最後是 Gemma 2B 版,模型大小 2.9GB,VRAM 佔 2.6GB、共用 GPU RAM 0.5GB,終於實現 100% 都用 GPU! (上圖[2]),至於 Gemma2 2B,大小亦為 2.9GB,也是 100% 使用 GPU。

Gemma 2 2B 的生成速度讓人驚豔,但沒有明確數據不夠科學,所以我改寫上回的 C# 範例,要求模型以 AI 為主題寫一小篇英文作文,測量每秒可以吐幾個字元。為求簡便,測速我是直接算字元數量,沒換成 Token 數,反正字元數接近肉眼感受,且用於對照不同模型、GPU 與 CPU 的差異,用 Token 或字元數都有足夠代表性。
程式碼如下:
// set up the client
using System.Runtime.InteropServices.Marshalling;
using OllamaSharp;
Action<string> printHeader = (header) =>
{
Console.ForegroundColor = ConsoleColor.Yellow;
Console.WriteLine(header);
Console.ResetColor();
};
var charCount = 0;
DateTime? startTime = null;
const string EOF = "\x04";
void print(string msg = "")
{
if (msg == EOF)
{
var elapsed = (DateTime.Now - startTime!.Value).TotalSeconds;
Console.ForegroundColor = ConsoleColor.White;
Console.WriteLine("\nRate: {0:n1} chars/sec", charCount / elapsed);
Console.ResetColor();
}
else
{
charCount += msg.Length;
Console.Write(msg);
}
}
void start() {
startTime = DateTime.Now;
charCount = 0;
Console.ForegroundColor = ConsoleColor.Cyan;
}
var uri = new Uri("http://localhost:11434");
var ollama = new OllamaApiClient(uri);
ollama.SelectedModel = "gemma2:2b"; // "phi3:mini"
ConversationContext context = null!;
printHeader("Article Generation Test");
string prompt = @"Write a 256-word article on artificial intelligence";
start();
context = await ollama.StreamCompletion(prompt, context, stream => print(stream?.Response ?? ""));
print(EOF);
我測試了 Phi-3 及 Gemma 2 兩個小模型:
- phi-3:mini 3.8B 參數
- gemma 2:2b 2B 參數
實測各跑五次,得到 chars/sec 數據及 GPU 使用狀況擷圖如下:
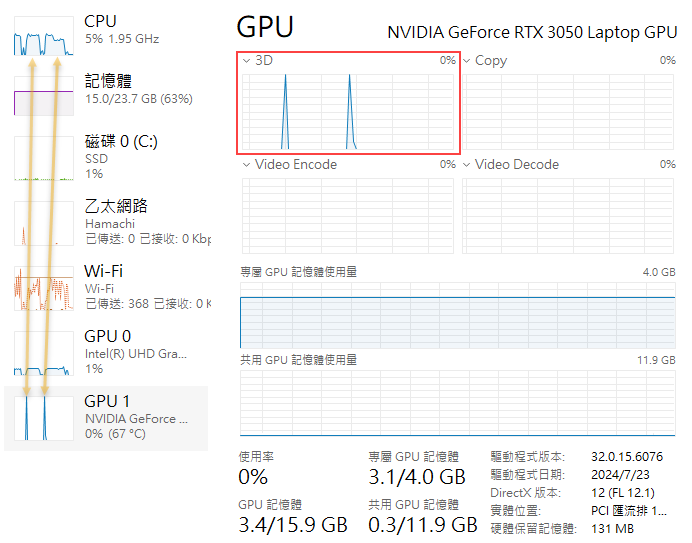
- phi3:mini - 160.1 142.9 155.2 152.3 154.1 每秒 150 個字元左右

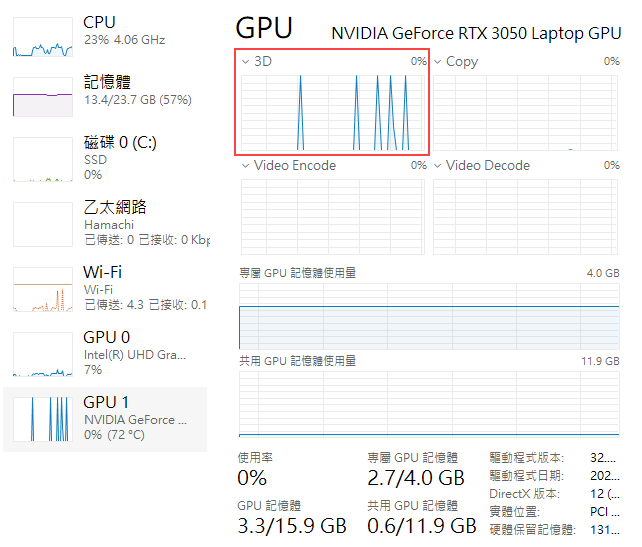
Phi-3 3.8B,5% 使用 CPU,95% 用 GPU,擷圖前做了兩次測試,可觀察到 GPU 有兩個小小的尖峰(紅框),對應當時 CPU 有兩段小高原(雙箭頭所指處),感覺 CPU 處理這 5% 還挺吃力的。 - gemma2:2b - 229.9 229.8 229.3 215.3 212.3,每秒可輸出兩百多個字元
Gemma2 2B 100% 用 GPU,擷圖前測了五次,GPU 3D 使用率可觀察到 5 個尖峰,CPU 使用率則看不出明顯對應。
看完奢華版 GPU 跑分,來看看平價版 i5 12500 的純 CPU 表現。
Gemma2 2B,每秒約 75 個字元,RTX 3050 的 1/3。
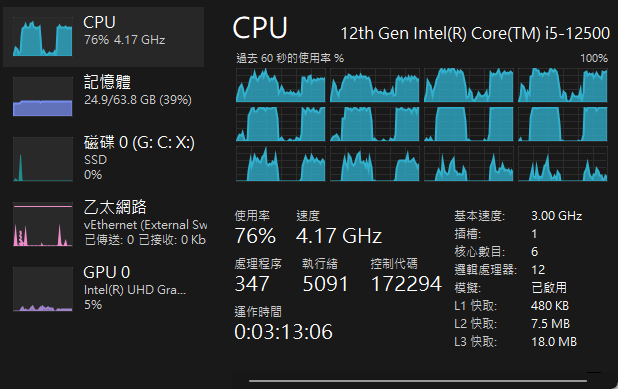
Phi3 3.8B,每秒約 53 個字元,差不多也是 RTX 3050 的 1/3。
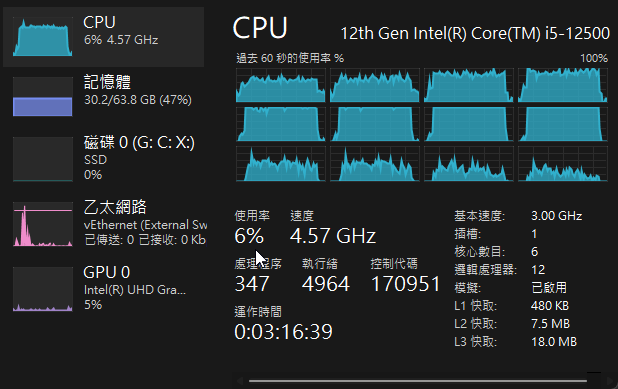
在這個 Ollama 跑 Phi3、Gemma 2 小模型的測試中,RTX 3050 4GB VRAM 輕鬆以三倍速輾壓 12 代 i5。各位同學如有更高級的 4050/4060/4070/4080/4090 也歡迎分享實測數字。
The blog explores testing AI models on a GPU (RTX 3050) vs. CPU, using Ollama to run models like Google Gemma 2 and Microsoft Phi-3. It demonstrates significant speed improvements with GPU usage and provides detailed performance metrics and observations.
Comments
# by yoyo
看起來Ollama像是LLM版的docker 許多機制都有相似
# by chihkang
RTX 3050 4GB VRAM 輕鬆以三部速輾壓 12 代 i5 應該是三倍速
# by jackson273
你要拍動畫,才會知道 字 出來多快
# by Jeffrey
to chihkang,謝謝指正。(錯字是「純手工寫作、非 AI 生成」的象徵,哈~)
# by Jeffrey
to jackson273,有想過。但後來想到不附動畫,有人可能會好奇字多快出來,自己跑程式試看看,有推坑效果。(謎:並不會)
# by Hank
CPU VS GPU 對比展示 https://www.youtube.com/watch?v=AwJ0dU_K2tM
# by 海大叔
以下是在H100上透過Ollama跑出來的分數。 Python 3.11.9 | packaged by conda-forge | (main, Apr 19 2024, 18:36:13) [GCC 12.3.0] OS: Linux, PyTorch version: 2.3.1.post300 Current Device: NVIDIA H100 NVL, CUDA: cuda 0, GPUs: 1 model = llama3:70b total_duration time = 16672.96 ms load_duration time = 7700.90 ms prompt eval time = 72.30 ms / 16 tokens eval time = 8896.52 ms / 342 tokens Performance: 38.44(tokens/s)
# by Jin
請問這是否意味著,在相同造價的情況下( 約美金 2000 ),macOS 跟擁有獨顯的 Windows 系統相比,對於本地端透過 Ollama 跑 LLM , Windows 系統會有絕對優勢?