傻瓜 LLM 架設 - Ollama + Open WebUI 之 Docker Compose 懶人包
| | | 10 | |
不久前發現不需要 GPU 也能在本機跑 LLM 模型的 llama.cpp,接著如雨後春筍冒出一堆好用地端 LLM 整合平台或工具,例如:可一個指令下載安裝跑 LLM 的 Ollama (延伸閱讀:介紹好用工具:Ollama 快速在本地啟動並執行大型語言模型 by 保哥),還有為 Ollama 加上 GUI 介面,連指令都不用敲就能架個 LLM 跟你聊天的 Open WebUI(原 Ollama WebUI 改版)。複雜繁瑣的地端 LLM 架設工作簡化到像傻瓜相機一樣簡便,稍具概念便能上手。(小朋友:傻瓜相機是什麼?)
要懶就賴到最高點,裝 Ollama 用 Docker 容器跑比安裝方便,而 Open WebUI 需搭配 Ollama 運行,一次跑兩個容器當然是用 Docker Compose 做成同綁包更省事。
在 Github 找到網友寫的 Docker Compose 版本,但它多跑一個 App 容器放了簡單的 Pynthon 導引網站,對我來說是多餘的。另外,它還在用 Ollama WebUI,也該改成新版 Open WebUI,於是我改寫成以下的 docker-compose.yml:
version: '3.8'
services:
ollama:
image: ollama/ollama:latest
ports:
- 11434:11434
volumes:
- .:/code
- ./ollama/ollama:/root/.ollama
container_name: ollama
pull_policy: always
tty: true
restart: always
networks:
- ollama-docker
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
volumes:
- ./ollama/open-webui:/app/backend/data
depends_on:
- ollama
ports:
- 8080:8080
environment:
- '/ollama/api=http://ollama:11434/api'
extra_hosts:
- host.docker.internal:host-gateway
restart: unless-stopped
networks:
- ollama-docker
networks:
ollama-docker:
external: false
註:上述範例是 CPU 版本,若你有 Nvidia 顯卡想用 GPU 加速,可參考專案說明,執行以下程序安裝 CUDA 支援並測試:
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg \
&& curl -s -L https://nvidia.github.io/libnvidia-container/stable/deb/nvidia-container-toolkit.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt-get update
sudo apt-get install -y nvidia-container-toolkit
# Configure NVIDIA Container Toolkit
sudo nvidia-ctk runtime configure --runtime=docker
sudo systemctl restart docker
# Test GPU integration
docker run --gpus all nvidia/cuda:11.5.2-base-ubuntu20.04 nvidia-smi
docker-compose.yml ollama 部分則可修改如下:
ollama:
volumes:
- ./ollama/ollama:/root/.ollama
container_name: ollama
pull_policy: always
tty: true
restart: unless-stopped
image: ollama/ollama:latest
ports:
- 11434:11434
networks:
- ollama-docker
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: 1
capabilities: [gpu]
準備好 docker-comopse.yml,在有安裝 Docker 的主機執行 docker-compose up -d,容器啟動後下載執行後便可連上 http://localhost:8080/ 進入 Open WebUI。介面需要登入,Sign Up 輸入姓名、Email (隨便敲) 及密碼註冊,第一位註冊的使用者會成為管理者,接著如下圖輸入模型名稱按 Pull <domain-name> from Ollama.com 就會自動下載安裝模型,稍後便可跟它愉快聊天。
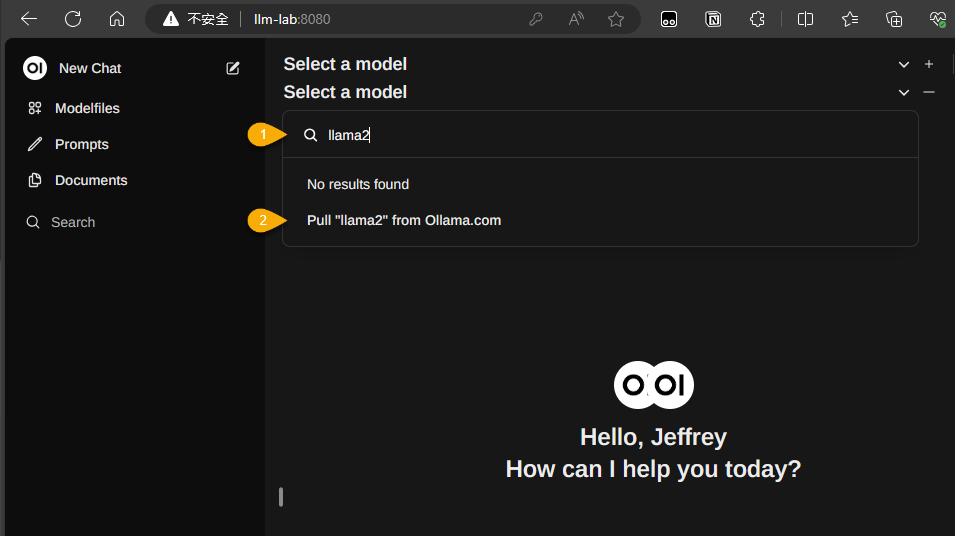
若不確定模型名稱,可在 https://ollama.com 輸入關鍵字查詢,例如,輸入 breeze-7b 可查到聯發科集團聯發創新基地釋出的繁體中文強化 LLM - breeze-7b-instruct-v1_0:

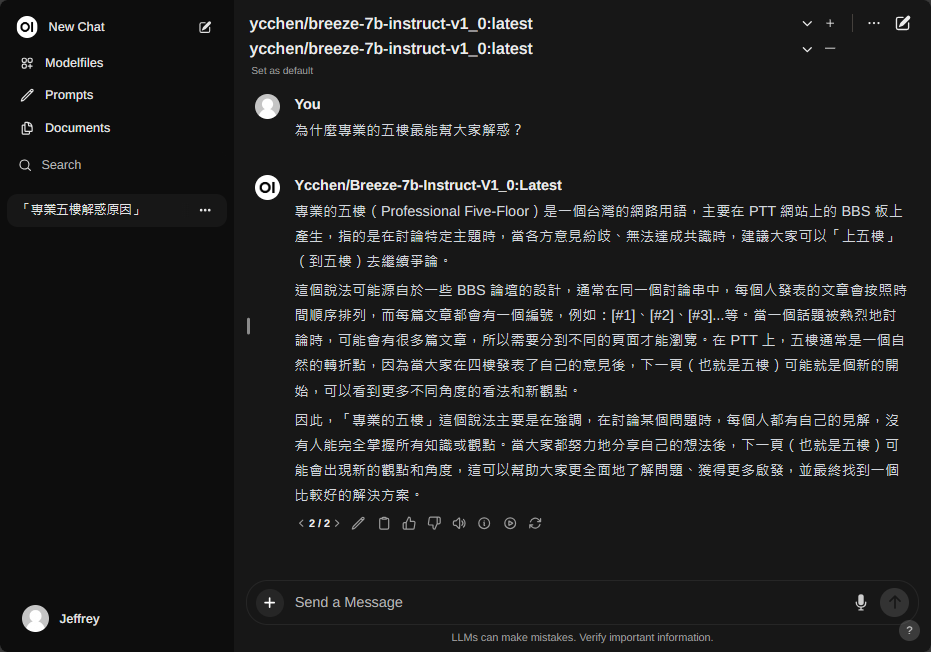
小試一下它知不知道何謂「專業的五樓」,驗證 Breeze 是地端的在地 LLM 無誤,呵。
Comments
# by jerry
LM Studio也很方便。
# by Hank
請問用 docker 跑 LLM 可以用到本機的顯卡麼?
# by Jeffrey
to Hank, 文章有安裝 Docker CUDA 支援的相關說明。
# by Gaan
跑LLM 如果需要它能懂c語言 c++ linux scripts kernel api 。需要額外的訓練資料嗎?還是這個本身就會自帶?
# by Jeffrey
to Gaan, 要解程式問題,一般會用具 Coding 專長的 LLM,例如:Codellama。自己訓練難度有點高。
# by 鄉民
感謝分享,實際操作後,使用相同聯發科模型和預設設定下得到的輸出並不了解「專業的五樓」的特殊含義,請問首先可以調整什麼參數呢?
# by popo
請問一下,如果想要把ollama換成vllm有辦法嗎?
# by Henry
請問你的系統配置是什麼,我都會遇到 Ollama: 500, message='Internal Server Error', url=URL('http://localhost:11434/api/chat')
# by michsu
image: ghcr.io/open-webui/open-webui:main 用wsl docker compose up 會噴錯 openwebui error getting credentials - err: exit status 1, out: `` 改用 powersheel 就好了
# by Tady
模型拉不下來都顯示,不知道什麼問題。問題。