Coding4Fun - 集保罕用字轉換工具 .NET 飆速版
 |  | 4 |  |  |
多年前研究過集保罕字集與 BIG5 造字,當時我用官方提供的編碼對照表(Map_code.txt)寫過一版 .NET 轉換函式。近期接到通報說程式跑出來的結果跟官方轉換工具不一樣,不知是不是操作方法有問題?,雖然懷疑程式是照著官方對照表轉換為何會有出入?莫非程式有 Bug?但既然官方有提供轉換工具,回歸官方解決方案才是正解。
防疫禁足放假被關在家有點無聊,又想起這事兒,便稍微研究集保提供的轉換工具,原來它是一支 Java 程式,可將 BIG5 檔案轉成 UTF-8,厲害的部分是能將造字對映成 Unicode 字元,也能反向將 UTF-8 轉回 BIG5。要將這功能整進 ASP.NET 或 .NET Console Application 也不是難事,用 Process 物件從 .NET 呼叫 Java 程式即可(參考:呼叫命令列程式並即時接收輸出),但每次執行建立新 Process 一定有額外效能損耗;另一個較嚴重的問題是 Java 轉換工具的速度比我預期慢,離我心中「適合高頻呼叫放心使用的好用元件」有段差距。想想這組轉換邏輯也不複雜,寫成原生版 .NET 程式庫還是較完美的解決方案。Google 了一下,好像沒人分享過 .NET 解法。說什麼 C# 也是程式語言界前五大門派,此刻怎能缺席?就讓我來開第一槍吧!
防疫期間沒法跑馬拉松,索性來場黑客松 - 來寫一個能取代 Java 版轉換工具的 .NET 版程式庫吧!
為了確保 .NET 版轉換程式與 Java 版執行結果一致,我想到一個驗證的好方法。轉換工具包裡有兩個檔案 Map_code.txt 與 Map_code_2.txt,前者包含所有集保造字:(如下圖,但要安裝官方工具裡的字型才能正確顯示)
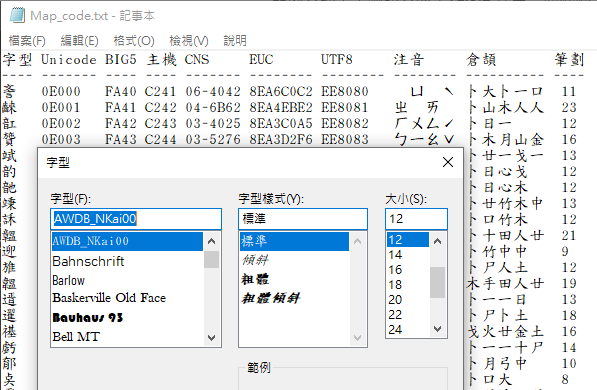
後者則有所有造字所對映的 Unicode 字元:
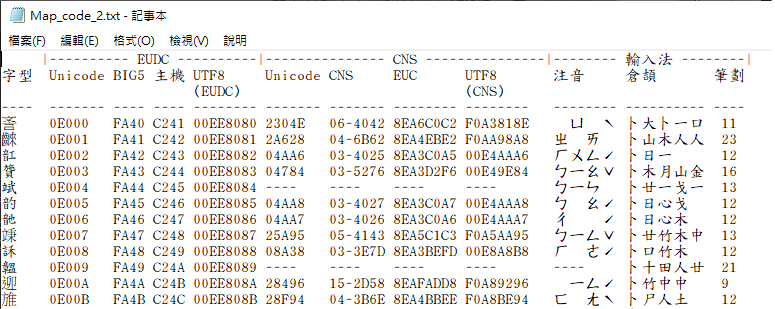
這兩個檔案相當於「樂透包牌」,能涵蓋所有需要轉換的字元,將 BIG5 編碼的 Map_code.txt 轉成 UTF-8、將 UTF-8 編碼的 Map_code_2.txt 轉成 BIG5,就等同把所有字元都驗證過一遍。
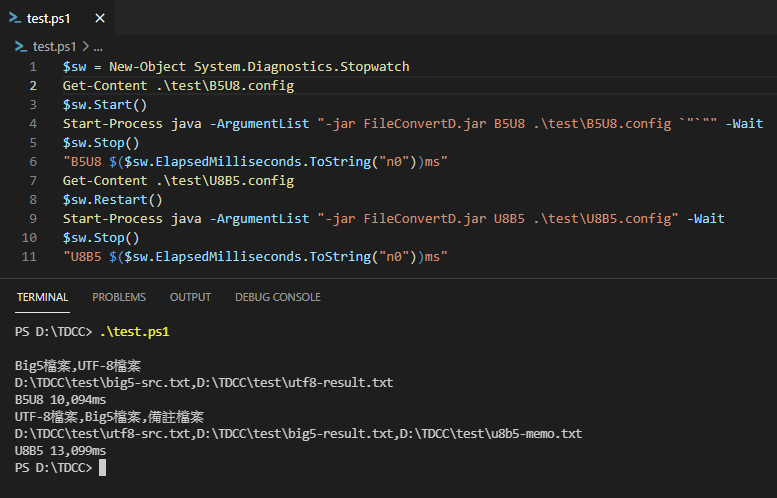
我先寫一小段 PowerShell 呼叫 java -jar FontConvD.jar 完成上述兩個檔案的轉換並計時:
$sw = New-Object System.Diagnostics.Stopwatch
Get-Content .\test\B5U8.config
$sw.Start()
Start-Process java -ArgumentList "-jar FileConvertD.jar B5U8 .\test\B5U8.config `"`"" -Wait
$sw.Stop()
"B5U8 $($sw.ElapsedMilliseconds.ToString("n0"))ms"
Get-Content .\test\U8B5.config
$sw.Restart()
Start-Process java -ArgumentList "-jar FileConvertD.jar U8B5 .\test\U8B5.config" -Wait
$sw.Stop()
"U8B5 $($sw.ElapsedMilliseconds.ToString("n0"))ms"
Map_code.txt (big-src.txt) 2MB、Map_code_2.txt (utf8-src.txt) 2.9MB,兩個檔案的轉換分別花了 10 秒跟 13 秒,速度有點慢,看起來較適合批次作業,用在即時系統頻繁呼叫應該會有心理壓力。
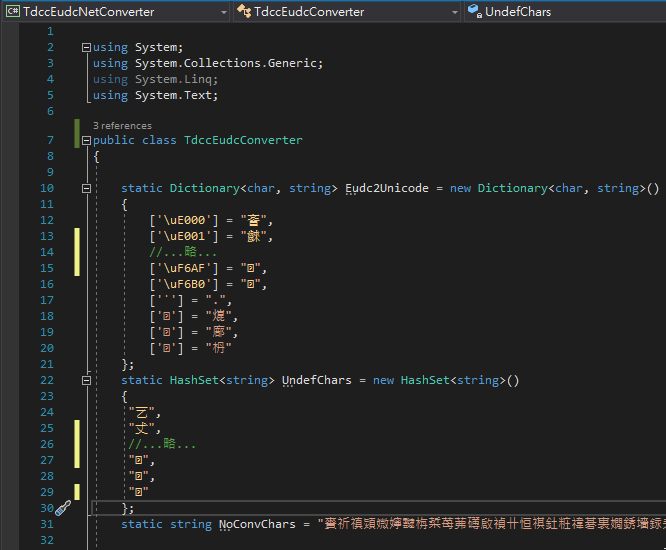
我照樣以 Map_code_2.txt 為依據寫了以下的程式產生器,用 Hard-Coding 方式寫死 Dictionary 字元對照表進行轉換,Unicode 罕用字一個字由兩個字元組成,我用了 Dictionary<char, Dictionary<char, string>> 的小技巧搞定。
試跑對照後發現一些 Map_code_2.txt 沒說的眉角,例如:造字檔沒定義的 Unicode 罕用字要翻成 "■" 而不是 "??"、有大概 90 個字元(包含:賚祈禛熲媺...)雖然有造字,但 BIG5 本來就有,故 Unicode 轉 BIG5 時不需對映回造字、Unicode 轉 BIG5 時注音輕聲符號也要轉換、還有一個特例: F3 90 對映到 廍,但反向則是 BF DB B4 DF 對映 F3 90,這些差距也許就是文章開始提到官方轉換結果會不同的原因。
程式碼產生器範例如下:
private static void GenClass()
{
Dictionary<string, string> map = new Dictionary<string, string>();
List<string> undefChars = new List<string>();
foreach (var line in File.ReadAllLines("Map_code_2.txt", Encoding.UTF8).Skip(4))
{
string convChar = line.Substring(0, line.IndexOf(" "));
var m = Regex.Match(line.Substring(1, 16), " 0(?<u>[0-9A-F]{4})");
if (m.Success)
{
map.Add($@"\u{m.Groups["u"].Value}", convChar);
}
else undefChars.Add(convChar);
}
//注音輕聲符號
map.Add("˙", "․");
//額外修正
map["\uE506"] = "熴";
map["\uF390"] = "廍";
map["\uF393"] = "枬";
var sb = new StringBuilder();
sb.AppendLine(@"
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
public class TdccEudcConverter
{
");
sb.AppendLine("\tstatic Dictionary<char, string> Eudc2Unicode = new Dictionary<char, string>()");
sb.AppendLine("\t{");
sb.AppendLine(
string.Join(
",\r\n",
map.OrderBy(o => o.Key).Select(o => $@" ['{o.Key}'] = ""{o.Value}""").ToArray())
);
sb.AppendLine("\t};");
sb.AppendLine("\tstatic HashSet<string> UndefChars = new HashSet<string>()");
sb.AppendLine("\t{");
sb.AppendLine(string.Join(
",\r\n",
undefChars.Select(o => $@" ""{o}""").ToArray())
);
sb.AppendLine("\t};");
sb.AppendLine("\tstatic string NoConvChars = \"賚祈禛熲...略....\";");
sb.AppendLine(@"
static Dictionary<char, string> SngCharMapping = new Dictionary<char, string>();
static Dictionary<char, Dictionary<char, string>> DblCharMapping = new Dictionary<char, Dictionary<char, string>>();
static TdccEudcConverter()
{
var big5 = Encoding.GetEncoding(950);
Func<string, string> convB5Bytes = (c) =>
BitConverter.ToString(big5.GetBytes(c));
var dict = new Dictionary<string, string>();
foreach (var kv in Eudc2Unicode)
{
if (dict.ContainsKey(kv.Value) || NoConvChars.Contains(kv.Value))
{
continue;
}
dict.Add(kv.Value, kv.Key.ToString());
}
foreach (var uc in UndefChars)
{
if (!dict.ContainsKey(uc)) dict.Add(uc, ""■"");
}
foreach (var kv in dict)
{
if (kv.Key.Length == 1)
SngCharMapping.Add(kv.Key[0], kv.Value);
else if (kv.Key.Length == 2)
{
var c1 = kv.Key[0];
var c2 = kv.Key[1];
if (!DblCharMapping.ContainsKey(c1))
DblCharMapping.Add(c1, new Dictionary<char, string>());
DblCharMapping[c1].Add(c2, kv.Value);
}
else
throw new NotSupportedException();
}
//特例規則: F3 90 對映到 廍,但反向則是 BF DB B4 DF 對映 F3 90
DblCharMapping['\udbbf']['\udfb4'] = ""\uf390"";
}
public static string ConvEudcToUnicode(string src)
{
var sb = new StringBuilder();
foreach (char c in src)
{
if (Eudc2Unicode.ContainsKey(c))
sb.Append(Eudc2Unicode[c]);
else
sb.Append(c);
}
return sb.ToString();
}
public static string ConvUnicodeToEudc(string src)
{
var sb = new StringBuilder();
var i = 0;
while (i < src.Length)
{
var c = src[i];
if (SngCharMapping.ContainsKey(c))
sb.Append(SngCharMapping[c]);
else if (DblCharMapping.ContainsKey(c))
{
if (i + 1 < src.Length && DblCharMapping[c].ContainsKey(src[i + 1]))
{
sb.Append(DblCharMapping[c][src[i + 1]]);
i++;
}
else
sb.Append(c);
}
else
sb.Append(c);
i++;
}
return sb.ToString();
}
");
sb.AppendLine("}");
File.WriteAllText("TdccEudcConverter.cs", sb.ToString(), Encoding.UTF8);
}
執行產生的程式碼高達 28,479 行,寫死 Dictionary 對照表不是什麼高明技巧,但它簡單粗暴,用在程式產生器不增加維護成本,程式好寫且效能不差:(提醒:近三萬行的程式碼會拖累 Visual Studio IDE,讓 CPU 使用率飆高,建議把它編譯成 DLL 參照使用,不要直接將把 TdccEudcConverter.cs 加進專案)
編譯完成 DLL 大小約 514KB,我一樣寫 PowerShell 做測試,.NET 版轉換速度超快,第一次啟動初始化較慢約 0.5 秒,之後 2MB BIG5 轉 UTF8 不到 0.1 秒、2.9MB UTF8 轉 BIG5 耗時 0.2 秒,轉 UTF-8 比 Java 版快了約 100 倍、反向轉換快了約 65 倍,而用 git diff 驗證也與 Java 版的轉換結果一致,我非常滿意! (這個做法有個缺點 - 若未來對映表有變動,必須重新產生程式重新編譯,但我猜頻率不致太高在可接受範圍,而 Java 版速度慢也可能是邏輯較具彈性的代價)
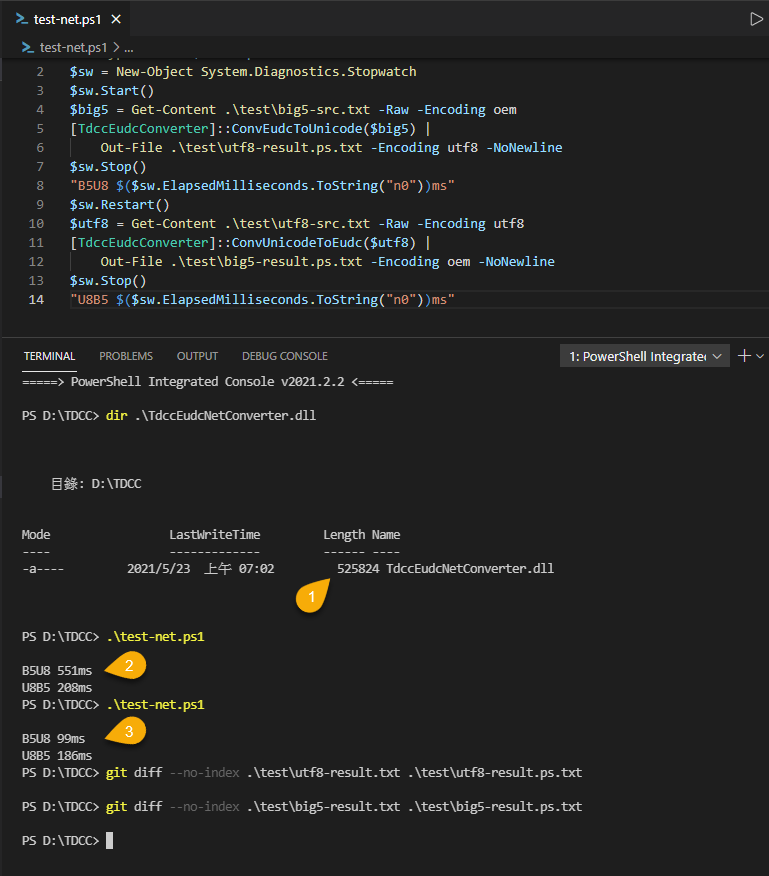
就算系統不是用 .NET 開發,也值得考慮把它包成 WebAPI 或 EXE 作為 Java 版轉換工具的替代方案。什麼?你說你的系統不是跑 Windows?放心,改用 .NET Core/.NET 5 編譯就好了,跨平台問題早已不是 .NET 的限制。
程式碼我放上 Github 了,採用 MIT 授權,歡迎大家取用(免費、可改寫、可自由散佈、可商業使用,但正確性請自行驗證),算是我對開源社群的小小回饋,也邀請大家一起壯大 C# 門派。唯一的小要求是 - 請大家在使用前,先呼口號「C# 蒸蚌,.NET 好威呀!」 幫我的 Github 專案 點顆星星,讓我知道我的程式幫助到多少人:(老人更需要大家的互動與關懷 XD)
C# 真棒,.NET 好威呀!
Trying to write my .NET version to replace TDCC end user defined characters convertion tool.
Comments
# by Youlin
目前難字轉換為使用cns11643,集保要被取代
# by sa
C# 蒸蚌,.NET 好威呀!
# by eric lin
想請問 UTF8仍是造字如何顯示正常跟列印?? 用到本地端造字檔(購買某造字管理程式)
# by Jeffrey
to eric lin,若要採用造字管理程式解決方案,軟體廠商應該會提供使用說明才對。