Guid Primary Key 問題新解法 - SequentialGuidValueGenerator
| | | 7 | |
關於資料庫是否該用 Guid 當 Primay Key,正反雙方各有擁護著,使用 Guid 的好處是不需依賴資料庫即可取得唯一識別碼,有助提高系統設計彈性,同時 Guid 無法被猜測具安全防護效果;缺點則是不利人工查詢、消耗儲存空間及當作叢集索引(Clustered Index) 時易導致索引破碎(Index Fragement)衝擊效能(有 3 秒變 40 秒的案例),這些在 GUID Primary Key 資料庫避雷守則一文已做過深入探討,想了解更多的同學可自行參考。
依先前研究心得,人工查詢不便及儲存空間問題不大,因 Guid 不連續性造成索引破碎,對效能的殺傷力則不容小覷。雖然 SQL Server 有提供 NEWSEQUENTIALID 產生連續性 GUID 避免類似問題,但如此會提高對資料庫的依賴,Guid 也變得可猜測,對我而言 Guid 的優勢盡失,算不上是完美解決方案。
前幾天讀者 eric 留言提到一個好東西 - EF Core 1.0 起提供了所謂 SequentialGuidValueGenerator,一種可在 .NET 產生對 SQL 具連續性 Guid 的產生器,意思是它保證後產生的 Guid 排序一定在後面,如此即使把 Guid 當叢集索引也不會造成索引破碎,從而擺脫 Guid Primary Key 的最大罩門。(關於 Guid 排序規則,可參考昨天的冷知識)
在 Github 找到 SequentialGuidValueGenerator 的原始碼,會發現它的原理出奇簡單,初始化時以 DateTime.UtcNow.Ticks 當計數器初始值,每次取 Guid 時計數器 +1,先用 Guid.NewGuid() 產生一般的 Guid,再將 Guid 16 Bytes 的第 10-15、8-9 Byte 換成計數器內容,由於 SQL 排序 Guid 時會先比 10-15、再比 8-9,而計數器每次加 1,「原則上」就能確保後產生的 Guid 會比早先產生的大。(只是原則上,後面會再說明)
private long _counter = DateTime.UtcNow.Ticks;
/// <summary>
/// Gets a value to be assigned to a property.
/// </summary>
/// <param name="entry"> The change tracking entry of the entity for which the value is being generated. </param>
/// <returns> The value to be assigned to a property. </returns>
public override Guid Next(EntityEntry entry)
{
var guidBytes = Guid.NewGuid().ToByteArray();
var counterBytes = BitConverter.GetBytes(Interlocked.Increment(ref _counter));
if (!BitConverter.IsLittleEndian)
{
Array.Reverse(counterBytes);
}
guidBytes[08] = counterBytes[1];
guidBytes[09] = counterBytes[0];
guidBytes[10] = counterBytes[7];
guidBytes[11] = counterBytes[6];
guidBytes[12] = counterBytes[5];
guidBytes[13] = counterBytes[4];
guidBytes[14] = counterBytes[3];
guidBytes[15] = counterBytes[2];
return new Guid(guidBytes);
}
由上述原理,不難模擬「後產生 Guid 比早先產生 Guid 小」的情境,例如:有兩個 SequentialGuidValueGenerator 在同一個 DateTime.UtcNow.Ticks (姑且稱之 TicksX) 時建立,第一個連續 Next() 產生十個 Guid,計數器為 TicksX + 10,第二個在半小時後才產生第一個,計數器等於 TicksX + 1,雖然較晚產生,但排序在 Ticks + 10 之前。不過若每次要用才 new SequentialGuidValueGenerator(),此種狀況發生機率很低,出現也不致有毁滅性後果。另一個問題這種連續式 Guid 的隨機部分只剩 58 位元(64 再扣除 4 Bit 版號及 2 Bit UUID Variant),不重複性大幅下降,原本號稱海枯石爛都很難重複的特性不復存在 (但仍高到有生之年都很難遇到就是了)。延伸閱讀:好問題:GUID 真的不會重複嗎?
研究完理論,來實作體驗一下。在 SQL 建兩個 Table,Idx 是產生順序、Uuid 是 Guid。NewSeqIdTest 設了 [Uid] Uniqueidentifier DEFAULT NEWSEQUENTIALID() 以使用 SQL 連續式 GUID:
CREATE TABLE [dbo].[SeqGuidTest]
(
[Idx] INT NOT NULL PRIMARY KEY,
[Uid] Uniqueidentifier NOT NULL
)
CREATE TABLE [dbo].[NewSeqIdTest]
(
[Idx] INT NOT NULL PRIMARY KEY,
[Uid] Uniqueidentifier DEFAULT NEWSEQUENTIALID()
)
用一小段程式呼叫 SequentialGuidValueGenerator 產生 5 筆 Guid,再用 SQL 產生 5 筆連續 Guid,分別比較這些 Guid 在 .NET 排序及 INSERT 到 SQL 資料表的排序:
class Item
{
public int Idx { get; set; }
public Guid Uid { get; set; }
}
static void Main(string[] args)
{
var sgvg = new SequentialGuidValueGenerator();
var seqGuidList = Enumerable.Range(1, 5).Select(o => new Item
{
Idx = o,
Uid = sgvg.Next(null)
}).OrderBy(o => BitConverter.ToSingle(o.Uid.ToByteArray())).ToList();
Console.WriteLine("SequentialGuid Sorting in .NET");
Console.WriteLine(new string('=', 48));
seqGuidList.ForEach(o =>
{
Console.WriteLine($"{o.Idx}. {o.Uid}");
});
Console.WriteLine();
using (var cn = new SqlConnection(cs))
{
cn.Execute("DELETE FROM SeqGuidTest");
cn.Execute("INSERT INTO SeqGuidTest (Idx, Uid) VALUES (@Idx, @Uid)",
seqGuidList.ToArray());
var res = cn.Query("SELECT * FROM SeqGuidTest ORDER BY Uid").ToList();
Console.WriteLine("SequentialGuid Sorting in SQL");
Console.WriteLine(new string('=', 48));
res.ForEach(o =>
{
Console.WriteLine($"{o.Idx}. {o.Uid}");
});
Console.WriteLine();
cn.Execute("DELETE FROM NewSeqIdTest");
cn.Execute("INSERT INTO NewSeqIdTest (Idx) VALUES (@Idx)",
Enumerable.Range(1, 5).Select(o => new Item { Idx = o }).ToArray());
res = cn.Query("SELECT * FROM NewSeqIdTest ORDER BY Uid").ToList();
Console.WriteLine("NewSequentialId Sorting in SQL");
Console.WriteLine(new string('=', 48));
res.ForEach(o =>
{
Console.WriteLine($"{o.Idx}. {o.Uid}");
});
Console.WriteLine();
Console.WriteLine("NewSequentialId Sorting in .NET");
Console.WriteLine(new string('=', 48));
res.OrderBy(o => o.Uid).ToList().ForEach(o =>
{
Console.WriteLine($"{o.Idx}. {o.Uid}");
});
}
}
結果如下,由於 .NET 與 SQL 的 Guid 排序邏輯不同,SequentialGuidValueGenerator.Next() 產生的 Guid 在 .NET 排序呈隨機分佈,但 INSERT 到 SQL 後會依產生先後排序;至於 SQL NEWSEQUENTIALID() 產生的 Guid 為不含隨機成本的連號數字,在 .NET 與 SQL 都是依產生先後順序排列。
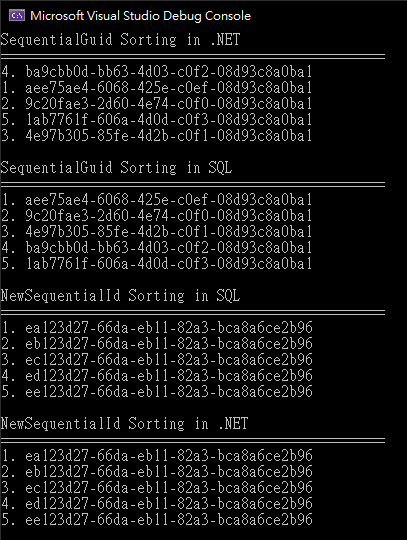
SequentialGuidValueGenerator 雖然來自 EF Core,但概念不複雜,可以輕易搬到任意 .NET 版本使用。
【結論】 由實測結果,SequentialGuidValueGenerator 確實具備可不依賴資料庫直接產生、具隨機性無法猜測以及資料排序呈線性等優勢,用來取代 Guid 可避免惱人的索引破碎問題。小缺點是其隨機性遠不如 Guid,永不重複的保證性較差 (即便如此,要遇到仍比中樂透還難),還有一點隱憂是 - 若系統設計成 Guid 當成叢集索引並依賴 SequentialGuidValueGenerator 防止索引破碎,則必須嚴格防止所有 INSERT 程式誤用 Guid.NewGuid(),若有人沒遵守即可能發生災難(大部人看到 Schema 是 Uniqueidentifier,直覺都會認為塞 Guid 沒錯),從防禦性設計觀點來看有點脆弱。我個人的話,應該會傾向用自動跳號當成叢集索引 + Guid Primary Key 的方式克服缺陷,讓系統設計意圖更明顯,不易被誤用。
【延伸閱讀】
Introduction to SequentialGuidValueGenerator and how it resolves Index Fragement issue.
Comments
# by kkman021
最近導入新系統在看完部落格後,就決定採用:自動跳號當成叢集索引 + Guid Primary Key 的方式。 原本以為這一篇會再次顛覆我的決定,文章看完還是一樣用原有方式就好。 感謝一直的分享!受益良多!
# by Jeffrey
to kkman021,決策跟個人偏好有關,常因人而異。我習慣都會說明決策的依據,大家可參考理由再挑選自己認可的選項。我蠻偏好防禦性設計,擔心依賴 SequentialGuidValueGenerator 卻被誤塞 Guid 的風險,是回歸原本選擇的主因。
# by jeff
您好 想問一下如果使用自動跳號當成叢集索引 + Guid Primary Key的話,若遇到要刪除整個table然後重倒資料的話是否就要先手動停止自動跳號功能再倒,倒完再開啟
# by Jeffrey
to jeff, 這種情境的自動跳號多半不會當成查詢條件,數值多少不重要,重倒之後跳號數字與原先不同應不致有影響(想到的唯一例外是跳號欄位設大小,筆數 x2 怕爆掉),或是你們其他特殊考量?
# by Deh
看起來跟COMB guid差不多 還是用流水號Clustered Index GUID當PK這樣好的感覺
# by Miki
嗨 在近日逐漸流行的分散式 DB 系統(或稱NewSQL?) ,例如:Spanner, CosmosDB, CockroachDB 等 由於為了避免遇到熱點問題,都鼓勵採用 GUID 作為 Key且GUID越沒有順序越好(可以避免資料被集中到某一個節點失去份散式架構的好處,俗稱熱點問題) 不知道大家對這方面的議題有沒有研究過,在與傳統 SQL 系統之間該如何做取捨? (例如:保留日後遷移至NewSQL的彈性與減少遷移作業等) 跟與大家集思廣益看能不能找到一種方式能夠在各種優劣種找到平衡?
# by NewBorn DBA
實務上我們使用 UUID_SHORT() 解決有序唯一值的問題,取代 AUTO_INCREMENT 天花板的問題 但純數字好猜測是硬傷 ; 也解決了 GUID 長度過長,資深工程師不適應的問題 但都比 AUTO_INCREMENT bigint 乾淨些 XD #沒有對錯,只有合不合適