PDF 取文字解析與 RegularExpression 練習
| | | 2 | |
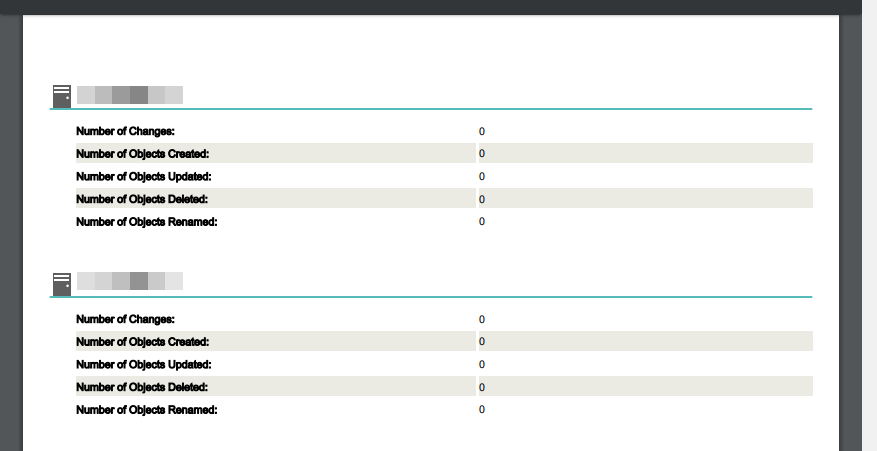
工作上的小需求,監控系統定期發送 PDF 報表,回報像下面的主機監控數據。
覺得每天重複收信開 PDF 檔用肉眼檢查很蠢,但監控系統不在轄區沒法要求其他格式,怎麼辦?
幸好,我們可是會寫程式的人呢,不怕不怕。
先寫一隻小程式檢查 Outlook 收件匣依主旨特徵挑出監控系統報表,從中取出 PDF 檔,再取出文字比對。
大家常用的 .NET PDF 元件,iTextSharp,前陣子聽說似乎有授權疑慮,特別查了,狀況應是 iTextSharp 4.1.6/iText 4.2.0 之前原本採用 MPL 和 LGPL 授權(註:GPL 的感染力直逼僵屍病毒,專案只要沾到 GPL 程式庫就必須跟著 GPL 開源, 讓開發者退避三舍,因此有些元件會採用較寬鬆的 Lesser General Public License/LGPL,免除單純呼叫函式也必須公開原始碼的限制。參考: 避免無謂的商業授權費,搞懂LGPL與GPL的不同), 但在 5.0 版後,iTextSharp 改為 AGPL,於非開源專案使用必須購買商業許可,開發商並主張 4.x 包含非 LGPL 程式碼,使用可能侵犯著作權。參考
研究了一下,一時沒找到好用的 iTextSharp 替代品。但由於我只需要純文字,想到另一條路 - 用 IFilter 把 PDF 轉成純文字 (延伸閱讀:為 PDF、Office 檔案產生文字索引)。 我找到一個 NuGet 套件 - IFilterTextReader:
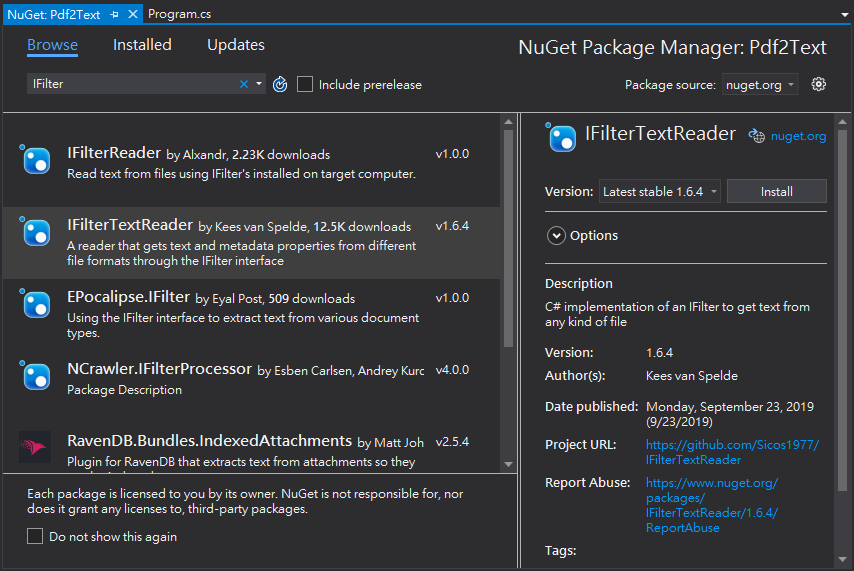
可以一行搞定 PDF 轉字串:
var text =
new IFilterTextReader.FilterReader("test.pdf").ReadToEnd();
FilterReader 會將文章開頭圖例的表格轉成如下文字:
192.168.1.100 Number of Changes: Number of Objects Created: Number of Objects Updated: Number of Objects Deleted: Number of Objects Renamed: 11 2 1 0 8 192.168.1.101 Number of Changes: Number of Objects Created: Number of Objects Updated: Number of Objects Deleted: Number of Objects Renamed: 23 9 5 2 7
而我的目標是要轉成以下格式:
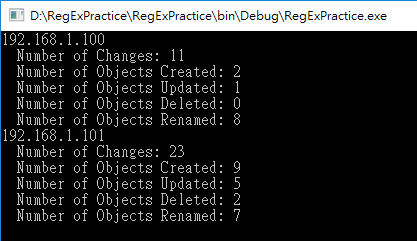
對我來說這是一次 RegularExpression 隨堂測驗,我花了半個小時交卷,學會一個知道但沒實際用過的進階樣式 Positive Lookahead (右合樣)。(延伸閱讀:使用 Regular Expression 驗證密碼複雜度 by 保哥)
範例程式如下:
class Program
{
static string source =
"192.168.1.100 Number of Changes: Number of Objects Created: Number of Objects Updated: Number of Objects Deleted: Number of Objects Renamed: 11 2 1 0 8 192.168.1.101 Number of Changes: Number of Objects Created: Number of Objects Updated: Number of Objects Deleted: Number of Objects Renamed: 23 9 5 2 7";
static void Main(string[] args)
{
foreach (Match hostData in Regex.Matches(source, @"(?<ip>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})(?<data>.+?(?=\d{1,3}\.\d{1,3}\.|$))"))
{
var ip = hostData.Groups["ip"].Value;
var data = hostData.Groups["data"].Value;
var labels = Regex.Matches(data, @"(?<h>Number of .+?:)+").Cast<Match>()
.Select(o => o.Groups["h"].Value).ToArray();
var values = Regex.Matches(data, @"(?<n>[0-9]+)").Cast<Match>()
.Select(o => o.Groups["n"].Value).ToArray();
Console.WriteLine(ip);
for (var i = 0; i < labels.Length; i++)
{
Console.WriteLine($" {labels[i]} {values[i]}");
}
}
Console.ReadLine();
}
}
程式執行原理是先用 (?<ip>\d{1,3}\.\d{1,3}\.\d{1,3}\.\d{1,3})(?<data>.+?(?=\d{1,3}\.\d{1,3}\.|$)) 拆出以 ddd.ddd.ddd.ddd (d 代表 0-9 數字)起首到下一段 ddd.ddd. 或字串結尾的一段文字。 (?=X|$) 即所謂 Positive Lookahead,限制該段文字後要接 X 或是字串結尾才吻合。比對結果跑迴圈取出 IP 及 IP 後方的 Number of ***: 及數字等內容,再分別各用 (?<h>Number of .+?:)+ 及 (?<n>[0-9]+) 取出欄位標題及欄位數值。 這裡有用到先前介紹過讓 MatchCollection 支援 LINQ 的小技巧,接著爽爽寫 LINQ 轉成字串陣列,理論上欄位標題及數值的數目要相同,用迴圈輸出結果,大功告成。
My practice of using regular expression positive lookahead to extract info from text which is extracted from PDF by IFilter.
Comments
# by Huang
這個試試 http://www.squarepdf.net/pdfbox-in-net
# by Jeffrey
to Huang, 感謝補充,已筆記。