範例:使用 .NET 程式擷取 Word 表格內容
| | | 0 | |
寫 .NET 存取 Excel 檔對我已是家常便飯,基本上只要有 ClosedXML 就能搞定。但偶爾會遇到資料存在 Word 表格,在江湖行走,這點雜耍技巧多少要懂。
研究了一下,比想像簡單。MS Docs 有篇簡單扼要的範例,原理是先用 MainDocumentPart.Document.Body.Elements<Table> 取得 DocumentFormat.OpenXml.Wordprocessing.Table 物件,再由 Table.Elements<TableRow>() 取得列集合,接著 TableRow.Elements<TableCell>() 拿到欄集合,即可從中取出文字內容。
在網路上胡亂找了個書單 Word 檔當範例,打算從中取出三個表格裡的書名、作者跟出版社:

要解析 Word 檔,專案要先安裝 OpenXML SDK:
程式碼很簡單,照著 Table、TableRow、TableCell 一路巡下來,再用 InnerText 取出 TableCell XML 元素的純文字內容,搭配好用的 LINQ 語法,不到 50 行便輕鬆搞定:
using DocumentFormat.OpenXml.Packaging;
using DocumentFormat.OpenXml.Wordprocessing;
using System;
using System.Collections.Generic;
using System.IO;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace DocxTableParserExample
{
class Program
{
public class Book
{
public string Title { get; set; }
public string Author { get; set; }
public string Publisher { get; set; }
}
static void Main(string[] args)
{
//我的案例檔案以 byte[] 方式傳入,故此處採資料不落地寫法
var content = File.ReadAllBytes("推薦書單.docx");
using (var ms = new MemoryStream(content))
{
using (var wp = WordprocessingDocument.Open(ms, false))
{
var doc = wp.MainDocumentPart.Document;
var tables = doc.Body.Elements<Table>().ToList();
Console.WriteLine($"表格數: {tables.Count}");
var list = new List<Book>();
foreach (var table in tables)
{
foreach (var tr in table.Elements<TableRow>().Skip(1))
{
var tds = tr.Elements<TableCell>().ToArray();
list.Add(new Book
{
Title = tds[0].InnerText,
Author = tds[1].InnerText,
Publisher = tds[2].InnerText
});
}
}
foreach (var book in list)
{
Console.SetCursorPosition(0, Console.CursorTop);
Console.Write(book.Title);
Console.SetCursorPosition(32, Console.CursorTop);
Console.Write(book.Author);
Console.SetCursorPosition(48, Console.CursorTop);
Console.WriteLine(book.Publisher);
}
}
}
Console.ReadLine();
}
}
}
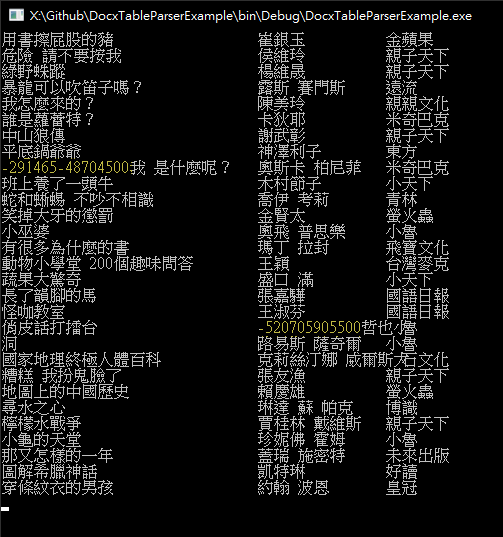
執行程式拿到結果,但有個小問題,部分書名或作者名夾雜奇怪數字,例如 「我 是什麼呢?」變成「-291465-48704500我 是什麼呢?」:
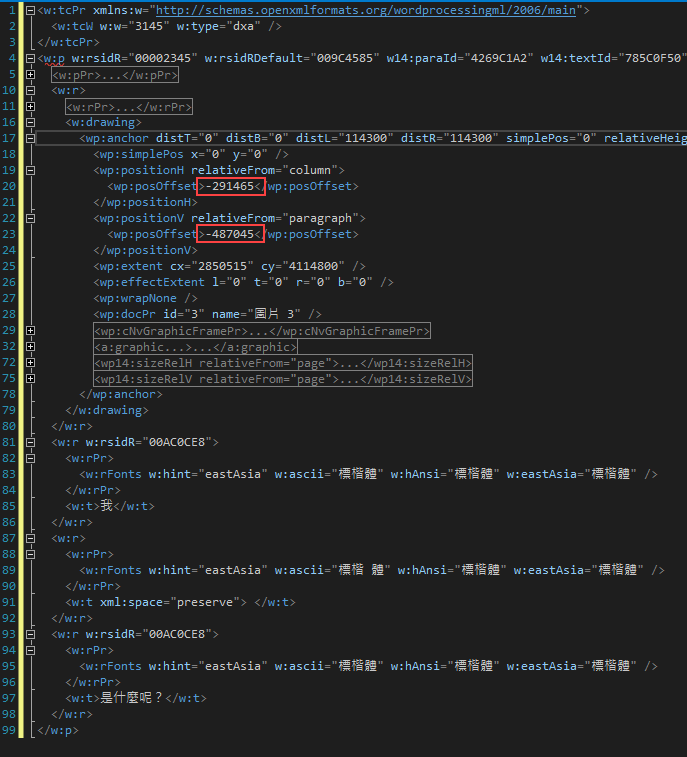
取出 TableCell XML 檢查,發現文件裡的插圖實際上被儲存在表格欄裡,再用文繞圖設定調整顯示位置,InnerText 出現的數字是座標參數 XML 節點的內容:
我寫了一個改良版,不直接取 InnerText,改由 Descendants<Text>() 篩選所有 Text 元素,再將其 InnerText 組合成字串,便可避開參雜非文字問題,成功!
static string ExtractText(DocumentFormat.OpenXml.OpenXmlCompositeElement element)
{
return string.Join("", element.Descendants<Text>().Select(o => o.InnerText).ToArray());
}
static void Main(string[] args)
{
//我的案例檔案以 byte[] 方式傳入,故此處採資料不落地寫法
var content = File.ReadAllBytes("推薦書單.docx");
using (var ms = new MemoryStream(content))
{
using (var wp = WordprocessingDocument.Open(ms, false))
{
//... 略 ...
foreach (var tr in table.Elements<TableRow>().Skip(1))
{
var tds = tr.Elements<TableCell>().ToArray();
list.Add(new Book
{
Title = ExtractText(tds[0]),
Author = ExtractText(tds[1]),
Publisher = ExtractText(tds[2])
});
}
//... 略 ...
}
}
Console.ReadLine();
}
C# example to parse tables in Word docx file with OpenXML SDK.
Comments
Be the first to post a comment