【茶包射手日記】Oracle 字元集與 VARCHAR2 長度問題
 |  | 0 |  |  |
今天在兩台 Oracle 資料庫間搬資料時踩到地雷。
一模一樣的 Table Schema,從 A 資料庫 SELECT 取出資料塞入 B 資料庫,竟有幾筆冒出字串長度過長錯誤。進一步分析,關鍵在某個 VARCHAR2(30) 欄位,內容包含中文理應設成 NVARCHAR2(30) 才合理,但它被設成 VARCHAR2,但有可能文字內容單純沒有罕用字或 Unicode 符號,故使用多年無人反映有錯。我找到一筆出錯的字串類似: '蒜味香雞排-要切-不要辣',總共十個中文字加兩個-符號。
經過推敲,推測問題與資料庫字元集設定不同有關。資料庫 A 是 ZHT16MSWIN950,而資料庫 B 是 AL32UTF8,十個中文字加兩個減號存入 VARCHAR2,若以 BIG5 編碼是 10 * 2 + 2 = 22 < 30;以 UTF8 編碼則是 10 * 3 + 2 > 30。依此規則抽樣出錯資料,都是中文字元算 2 個 Byte 長度小於 30,算 3 個 Byte 則長度大於 30。推論成立。
用實驗來驗證這點。
在 ZHT16MSWIN950 字元集環境,宣告 VARCHAR2(8) 寫入 '中文測試' (8 Bytes) 沒問題,寫入 '中文測試A' (9 Bytes) 便會出錯:
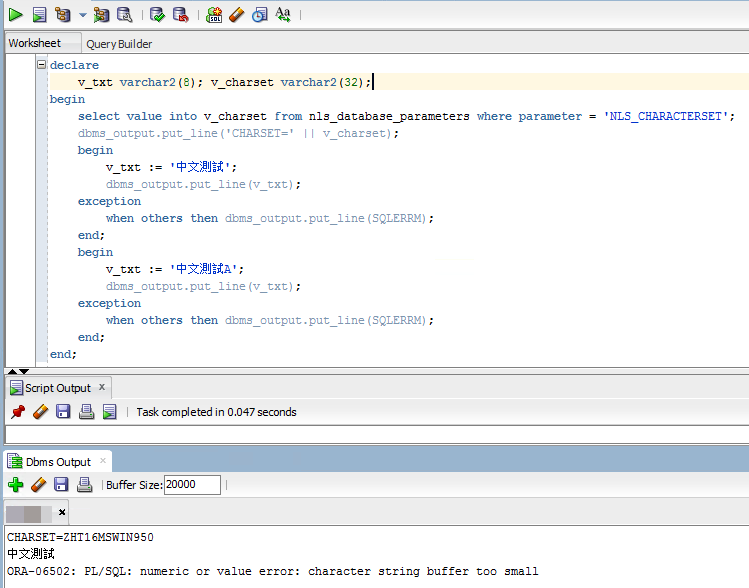
同樣的測試搬到 AL32UTF8 字元集 Oracle,寫入 '中文' (6 Bytes) 成功,多一字'中文測' (9 Bytes) 就爆炸,故得證:
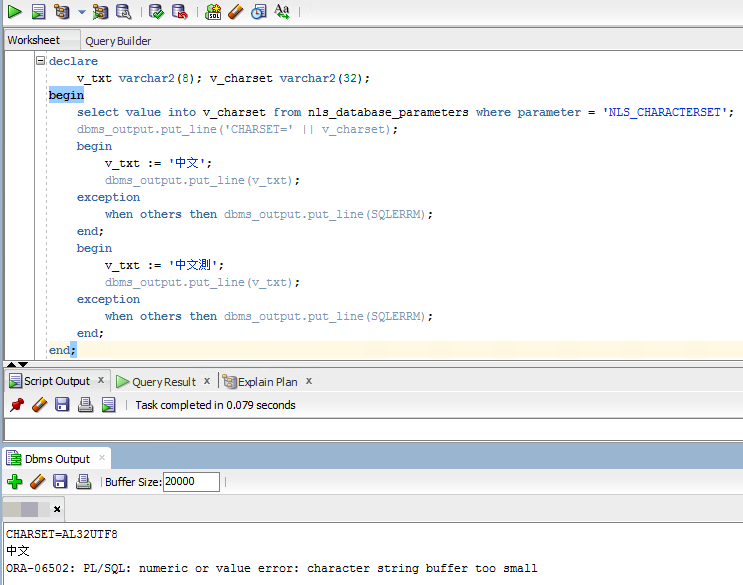
依過去經驗,MSSQL 支援為資料表或資料欄位指定不同字元集,原想依法炮製當成 Workaround。研究後發現 Oracle 的字元集設定必須全資料庫一致,資料表或欄位無法個別指定字元集。最後,只能協調修改 Schema 將欄位改為 NVARCHAR2 解決問題。
Comments
Be the first to post a comment