OpenClaw 龍蝦佐本地 AI 模型:從評估到放棄?
| | | 15 | |
上週在 FB PO 了篇閒聊,提到許多人對在 Mac Mini 養龍蝦 (OpenClaw,原名 Clawdbot/Moltbot) 有過度美好的幻想。嫌 AI 訂閱貴,燒 Token 燒到心疼,便以為 Mac Mini RAM 買大一點改跑本地端模型,便能 24 小時爽跑 AI 模型用到飽:
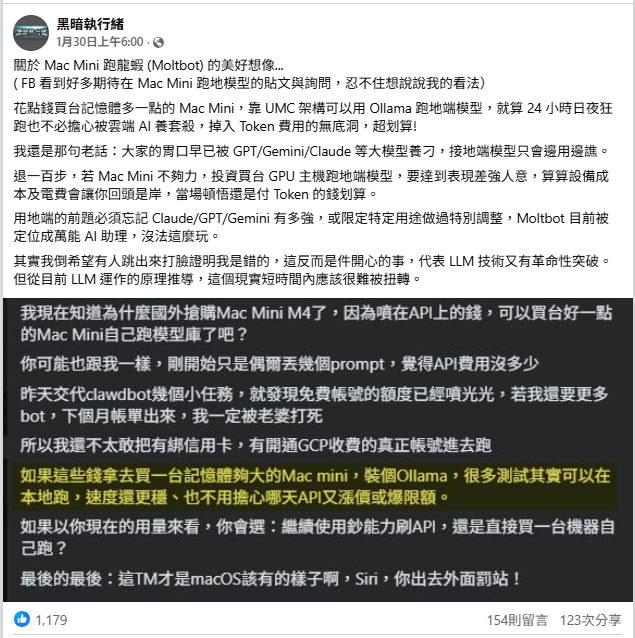
過去對跑地端模型的硬體曾做過功課(延伸閱讀:電腦沒有獨立顯卡,只靠 CPU 也能跑大型語言模型嗎?、訓練大型語言模型有多燒錢?、用來跑 AI 模型的「八卡機」長什麼樣子?、不專業整理 - A100 / RTX 6000 / 4090 價格與 LLM 效能數據),雖然終究無緣摸到制式武器實際跑過,但對訓練及運行地端 LLM 模型加減有點概念,多少能在公堂之上假設一下。
PO 文意外得到許多擁有正規軍事裝備,也實際把玩過本地端模型的讀者回響,分享專業心得(特此感謝),偷吸到不少經驗值(:D)。黑編(咦?)這裡整理大家的實戰經驗,當成回饋:
硬體
留言有提到 Mac Mini 16G/64G、Mac Studio、RTX 3090/4070、GB10 等硬體的使用經驗
- Mac Mini M4 16GB:就只是玩具,無法跑大模型,Phi-4 14B 模型速度只有每秒 9.8 Token (TPS),正常人應該無法忍受,能忍受的人應該不正常
- Mac Mini M4 Pro (64GB RAM / 20 GPU):7B 等級的模型,有可能用於執行低智力、高資料敏感度的自動化任務(如掃描郵件)
- Mac Studio (M3 Ultra / 256GB - 512GB RAM):比較有機會跑像樣的大模型
- LM Studio 跑 gpt-oss-120B 英文聊天可達 69.7 TPS ~ 80 TPS,但處理時間偏久,能明顯感受到延遲。(256G RAM 使用率 44%)
- qwen2.5-vl-32b-instruct 速度 29 TPS (慢,但支援多模態)
- qwen3-30b-a3b-2507 速度約 88 TPS,Context 提高到 262KB 記憶體仍有餘裕,WhatsApp/Telegram 回應僅需幾秒
- RTX 4070 Ti (12GB VRAM):12B 模型已是極限但表現不佳像廢物一樣,8B 模型雖快但品質不佳
- RTX 3090 (24GB VRAM):OpenClaw 跑 30B 量化模型的低標,勉強堪用。若要跑 70B,需兩張 3090
- ASUS GX10 (GB10 晶片小主機):跑 120B 模型速度還行,但不如雲端 (價格約 16~20 萬)
- NVIDIA B200:跑 GLM 模型仍覺得不太聰明
- Raspberry Pi 5:當然不可能用來跑本地端 LLM,但跑 OpenClaw 串雲端 LLM OK
模型選擇及測試
不同模型各方面表現的綜合整理:
- 7B - 8B 模型 (如 Llama 3.1-8b):
- 適用於簡單語言任務(聊天、總結、翻譯)
- 普遍被評為「太蠢」、「智力不足」,無法處理複雜 Agent 任務
- 12B - 20B 模型:
- 12B: 在 4070 Ti 上運行緩慢。
- GPT-OSS-20b:適用於少許數學邏輯任務
- 30B - 32B 模型:
- Qwen3-32b:具備推理能力。
- Qwen3-VL-8b:用於 OCR 任務。
- 30B 量化模型:是本地端勉強能用的最低標準,但需要 24GB VRAM。
- 70B - 120B 模型:
- GPT-OSS-120B:在高階 Mac Studio 上運行順暢,具備英文與繁體中文對答能力
- Ollama 跑 70B 模型:即便在 128GB RAM + 5090 顯卡的配置下,仍有人覺得是「垃圾」
- 其他模型:
- GLM-4.7-flash: 速度與能力平衡不錯,讓人驚艷
- Kimi k2:舊版在角色扮演上表現優於新版及 Thinking 版本
地端模型的絕對優勢
即便在速度及能力上被雲端大模型輾壓,地端模型在特定情境仍具絕對優勢。所有人一致贊同的應用是:雲端模型不可以色色,地端模型是製作 NSFW 色圖的唯一選擇。另外,若基於資安或隱私考量,不想資料被發送到雲端,又想要運用 LLM,那麼也只能忍受笨一點的地端模型。
另一種適用地端模型的情境是要處理海量資料,但任務單純,Token 爆量但不需要雲端先進模型的高智商,用地端模型能省下可觀的成本。
除了以上幾種狀況,即便必須付 Token 費用,論投資報酬率,雲端模型絕對能把地端模型壓在地上摩擦。
同場加映:從嘗試到放棄的案例
可能最近都在講龍蝦,YT 順勢推了我的這支影片:OpenClaw + Ollama 本地 AI 建置血淚史!為什麼我最後含淚棄坑回歸雲端 LLM?,也不少本地端模型的踩坑細節,一併收錄。
作者的測試環境為 RTX 6000 滿血版 (96GB VRAM,價格約 30 萬) 用 Ollama 前後測了 Qwen、GLM、GPT-OSS 等模型。
最嚴重的問題是不管 QWinNext 80B(模型大小 50GB)、qwen2.5:72B、glm-4.7-flash、gtp-oss:120b,即便號稱支援 Function Calling,實測下來,要嘛完全不懂要用工具,要嘛錯用或成效不佳,結果都不如預期。
再者是 OpenClaw 遇到複雜任務時會啟動 Subagent 分工處理,本地端模型無法支援會噴 Sessions Spawn Forbidden 錯誤,必須停用 Subagent 功能才能解決。另外,本地端模型也無法正確執行一些較複雜的任務,例如用 Playwright MCP 實際開啟瀏覽器截圖、選擇較有效率解法。總歸一句話,就是笨到讓人失望。(沒辦法,大家的胃口早被 GPT、Gemini、Claude 養刁了)
在坑裡掙扎了兩天,作者最後乖乖改用雲端 AI,走 GitHub Copilot 的 GPT-4o 模型,不計 Token 吃到飽,效果尚可接受,但已比本地端強很多,工具總算能正確呼叫。
[2026-02-08 有更新影片] 作者再奮鬥了四天,最後試出成功組合:llama.cpp + GPT-OSS 120B + OpenClaw,終於能正確使用工具執行任務,但規劃沖繩自由行任務耗時 9 分鐘且需要人工持續介入糾正,效果與雲端 AI 仍有極大差距。
附上對照組:在 Mac Studio 養龍蝦,原本要死不活,訂閱 Claude Max 模型改成 Opus,自此脫胎換骨...
結語
蒐羅完大家的經驗,回到先前的公堂假設:「大家的胃口早已被 GPT/Gemini/Claude 等大模型養刁,接地端模型只會邊用邊譙。」、「買 GPU/UMC 主機跑地端模型,要達到表現差強人意,算算設備成本及電費會讓你回頭是岸,當場頓悟還是乖乖付 Token 費划算。」,維持原判! 😄
Comments
# by SHIH-HUNG YANG
最近在玩小作品的翻譯,對這篇文章在認同不過了,用 RTX 4080 跑 14B 模型跑到天荒地老...買 Token 不用2小時跑玩了
# by 小紀
Ollama 70B:即便在 128GB RAM + 5090 顯卡的配置下,仍有人覺得是「垃圾」 ollama 是模型?
# by 小劉
20~30B的MoE在4 bit量化下不需要到24GB的VRAM吧?MoE就算大部分放RAM也還是能跑。在我的4060筆電版(8GB VRAM)上除了會吃很多RAM(10GB左右)以外速度跟12~14B的模型差不多。 但本地端模型的工具呼叫能力是真的不大可靠。我用AnythingLLM玩過幾次Ollama+Agent就不敢讓他放手亂跑。
# by 小民
大人英明
# by 小沢
之前玩過,深有同感,基本上地端模型對tool calling, 可以視為沒有或者亂用,幾乎無法達到auto planning loop的效果
# by yang
我只拿串免費的線上ai 排程回報天氣的作用而已
# by Jeffrey
to 小紀,精準說是用 Ollama 跑 70B 模型,至於是哪一款留言沒提
# by cc
等我dgx spark到了我來研究一下,理論上應該可以透過任務分級將簡單任務分給便宜模型或是本地模型,任務規劃給線上頂級模型,這樣應該可以省下不少API token(我估計50%)
# by niko
确实,我在DGX spark上使用本地模型,tool工具调用远不如联网api
# by wellxion
要想落地用爽爽只能靠鈔能力 XDD
# by Jacky
我用Github Copilot 的 GPT5-mini覺得效果很不錯,費用也不貴
# by light
所以現在玩AI是屬性有錢人的玩具,窮人玩不起,要玩也只能在地端上跑
# by 喵醬
隨著2月底發布了Qwen3.5-122B-A10B ,今年新出的模型不知道是不是有根據agent用途訓練,都可以驅動本地跑龍蝦。 我用BG10現在本地龍蝦已經能用,很慢但是便宜。 nvidia nemotron 3 super也可以。
# by 小王
微調、全調AI,做出很會使用工具的地端AI,有沒有機會呢?
# by Jeffrey
to 小王,如有辦法訓練出很會使用工具的地端 AI,光拿來養龍蝦太浪費,還可以發論文揚名國際哩~