如何自訂 OpenCC 字彙轉換表
| | | 5 | |
OpenCC 已提供十分優質的繁簡轉換,不過呢,實際使用下來難免會有些不到位的地方。所幸,OpenCC 的架構開放又有彈性,修改 json 設定檔就能載入自訂轉換字典,如果對既有轉換表或轉換規則不滿意,OpenCC 開放源碼,絕對讓你改到開心為止。
用個簡單例子示範如何自訂字彙轉換。假設我想將「黑暗執行緒在雲霄飛車上吃便當」翻成簡體,如使用包含常用詞彙轉換的設定檔 tw2sp.json,轉換結果如下:
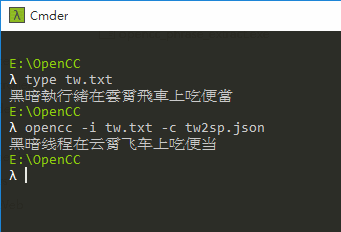
輸出結果為「黑暗綫程在云霄飞车上吃便当」,而我希望保留「執行緒」不要翻成「綫程」,並將「云霄飞车」與「便当」 翻成大陸用語「过山车」與「盒饭」。
遇到 OpenCC 未包含的轉換字彙,最簡單的解決方法是在 json 設定加掛自訂的轉換表。如下圖,每行文字以 Tab 鍵相隔,前方是繁體中文詞彙,後方是希望轉換的簡體中文詞彙:
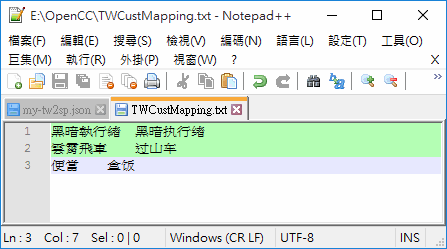
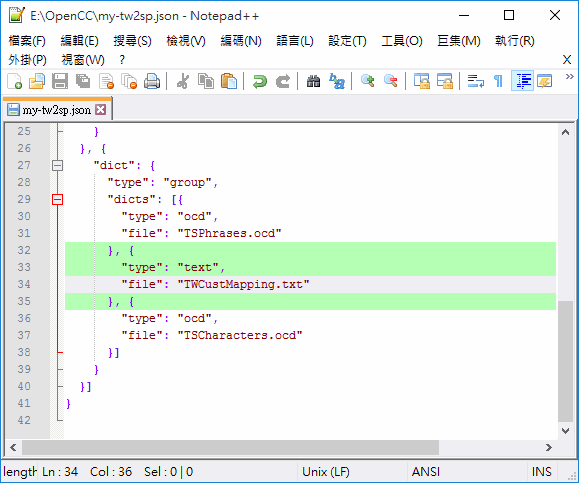
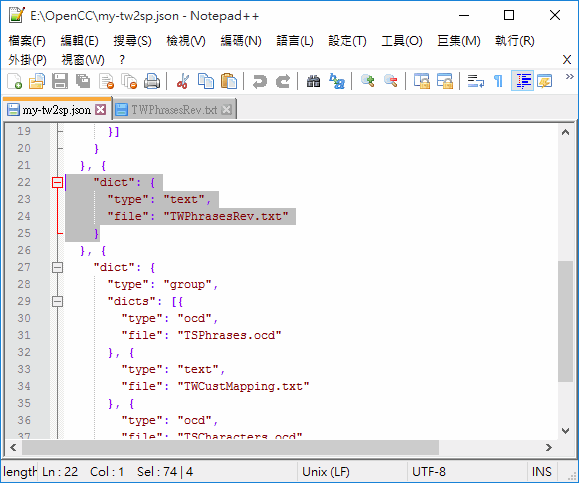
將 tw2sp.json 另存為 my-tw2sp.json 再修改加入{ "type": "text", "file": "TWCustMapping.txt" }:
改用 my-tw2sp.json,「过山车」與「盒饭」對了,但「綫程」沒改過來:
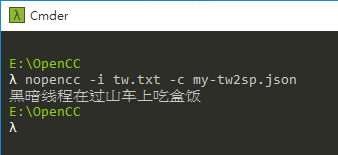
細究原因,是 TWPhrasesRev.ocd 裡定義了將「執行緒」轉為「綫程」。要修正這點可從原始碼中找到 TWPhrasesRev.txt,新增一條專有名詞,指定「黑暗執行緒」還是翻成「黑暗執行緒」,值得注意的是 TWPhrasesRev.txt 每一行前後都是繁體。
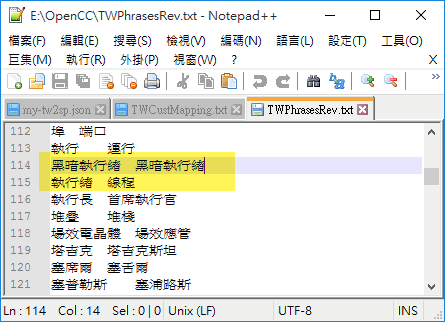
如下圖,我們將 TWPhrasesRev.ocd 換成 TWPhrasesRev.txt,type 則改成 "text":
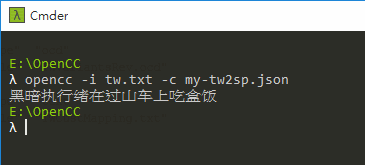
重跑一次,結果就完全符合預期了:
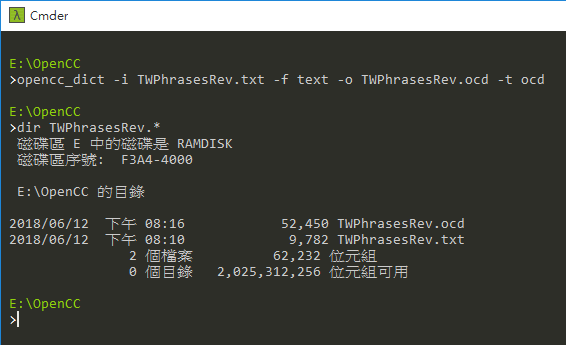
OpenCC 支援 .txt 跟 .ocd 兩種格式的字典檔,修改並改用 TWPhrasesRev.txt 即可自訂轉換詞彙,如希望提高轉換效率,可利用 opencc_dict.exe 工具將修改版 .txt 轉換成 .ocd。(注意:.ocd 檔 32/64 位元有別,請用正確位元版本的 opencc_dict.exe 進行轉換)
掌握以上技巧,我們就能微調轉換結果,符合客戶的各式要求囉~ 祝大家轉換愉快。
Exmaple of customized conversion rules for OpenCC
Comments
# by 布丁布丁吃布丁
很實用的資訊,感謝。
# by hsu
請問新增字庫另存成my_s2twp.json,但會跑出UnicodeDecodeError: 'cp950' codec can't decode byte 0x80 in position 751: illegal multibyte sequence是該如何解決?感謝回答!
# by Jeffrey
to hsu,TWPhrasesRev.txt 每一行前後都必須是繁體,是否在其中有摻雜簡體?若沒有頭緒,有個無敵破案大絕,將字庫分批刪去(或加入),看何時錯誤消失(或發生),縮小範圍抓出兇手。
# by Danny
個人是很支持 OpenCC 的理念,之前也提過不少PR,但是幾位大老維護頻率實在不高,難編譯難安裝的問題一直沒改善,還有個萬年 Bug (https://github.com/BYVoid/OpenCC/issues/475) 一直沒解決,導致本來設計詞典串聯的理念無法確實運作,實在可惜。 我個人已經放棄安裝使用 OpenCC 很久了,後來自己寫了一個 Python 簡繁轉換套件(https://github.com/danny0838/sts-lib),詞典規格和 OpenCC 相容,可以把多個詞典並聯、串聯組合後輸出成單一合併詞典檔,以方便日後載入使用,同時也能解決上述分詞 Bug。此外也增加了一些 OpenCC 未支援的功能,比如一對多轉換輸出,可輸出成 JSON 或 HTML 做後續選詞,另外也有提供線上版,可在轉換後做即時校對。此外還有支援用正規表示式指定不轉換的部分,以及支援 Unicode 組合字等。 唯一缺點大概只剩 Python 速度不夠快了。不過如果真的很在意速度,還有個辦法是把本程式合併後的詞典餵給 OpenCC 編譯使用,這樣也能達到繞過前述Bug的目的。
# by Danny
另外,從詞典架構的角度來看,這篇文章的做法也不是那麼適當。 「雲霄飛車」、「便當」都是地區詞轉換的範疇,與簡繁轉換無關;「黑暗執行緒」雖然不是地區詞,但本來會轉錯也純粹是地區詞轉換的問題(可測試用t2s繁體轉簡體,結果是「黑暗执行绪」,並無錯誤),因此三者其實都是地區詞典的問題,要解決這些問題,最合理的做法應該是修改 TWPhrasesRev.txt (或加入一個同層級的自訂詞典),寫入以下三組轉換: 黑暗執行緒 黑暗執行緒 雲霄飛車 過山車 便當 盒飯 至於簡繁轉換的詞典則不會更動。