SQL筆記:Literal, Variable與Parameter
| | | 0 | |
繼續研究不同SQL寫法對執行計劃的影響。
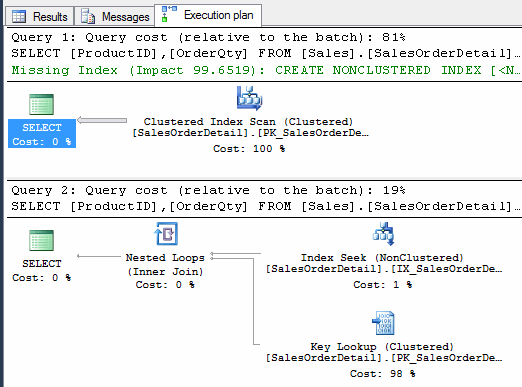
如果大家讀過上一篇筆記,就會知道以下兩則查詢將使用不同的執行計劃,前者走Clustered Index Scan,後者則是Index Seek + Key Lookup。
SELECT ProductID, OrderQty FROM Sales.SalesOrderDetail
WHERE ProductID = 870 --4688筆 SELECT ProductID, OrderQty FROM Sales.SalesOrderDetail
WHERE ProductID = 897 --2筆 經實測,執行計劃正如預期:
那,如果我將SQL改成這樣呢?將原本寫死的WHERE條件,改用變數(Variable)傳入,仍然查詢870跟897:
DECLARE @p INT
SET @p = 870 SELECT ProductID, OrderQty FROM Sales.SalesOrderDetail
WHERE ProductID = @p --4688筆 SET @p = 897 SELECT ProductID, OrderQty FROM Sales.SalesOrderDetail
WHERE ProductID = @p --2筆 查詢結果筆相同,但執行計劃變了,二者都走Index Scan:
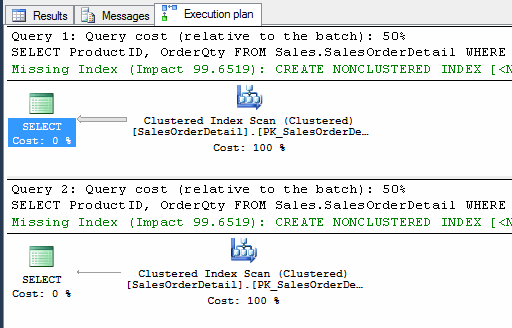
呃,為什麼?上回不是說資料筆數少用Index Seek,筆數多用Index Scan,這回又不照規矩來,SQL Server你搞得我好亂吶~
莫驚慌,SQL這麼做有它的理由,不是故意要把大家搞瘋。要找出最適合的執行計劃,全靠執行前對SQL指令進行分析。當我們使用WHERE ProductID = 897(把比對值直接寫在指令裡,術語稱為Literal),SQL分析時已知搜尋對象為ProductID 897,由統計資料預測結果筆數不多,使用Index Seek效率較佳;而宣告變數(Variable),指定變數值再WHERE ProductID = @p的做法,SQL於執行前無從得知@p的內容(雖然指令中有SET @p = 897,但分析期間不會真的下去跑指令),故只能用平均值進行預測,而266個ProductID大部分用Index Scan效率較佳,SQL押Index Scan贏面大,故遇到WHERE ProductID = 變數的場合一律用Index Scan。
WHERE ProductID = @p裡的@p可能還有另一種意義-Stored Procedure的參數(Parameter)。對SQL而言,Procedure內的邏輯固定,可以預先分析,而參數值在傳入時已知,不像變數到執行期間才確定,故SQL可以依參數值決定最適合的執行計劃(術語為Parameter Sniffing)。
為求簡潔,這裡我用sp_executesql示範,大家如果看不習慣,可以自行改寫成Stored Procedure,結果會一樣。
exec sp_executesql N'SELECT ProductID, OrderQty FROM Sales.SalesOrderDetail WHERE ProductID = @p', N'@p INT', @p = 897 --2筆 exec sp_executesql N'SELECT ProductID, OrderQty FROM Sales.SalesOrderDetail WHERE ProductID = @p', N'@p INT', @p = 870 --4688筆 如上所示,將原本Variable範例改為Parameter,但這回我們先查897(2筆)再查870(4688筆)。果然,Index Seek出現了:
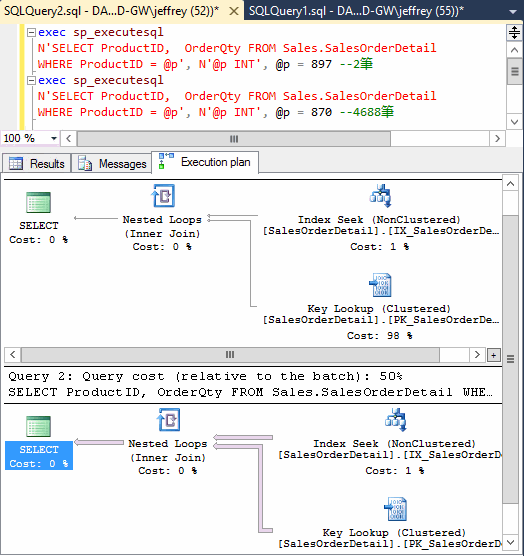
等一下!! 897(2筆)用Index Seek我沒意見,但870(4688筆)怎麼也用Index Seek,啊啊啊啊~
到這裡,我相信已沒人懷疑我想把大家逼瘋的決心了 XD
這與SQL的另一項效能武器有關:分析SQL指令得耗費資源,尤其實務使用的SQL指令,遠比我們寫的Hello World範例複雜數十上百倍,故SQL一般會使用快取保留分析結果,第二次執行相同指令時不用重新分析,直接套用執行計劃即可。
在我們的範例中,由於兩次sp_executesql的SQL指令完全相同,故第一次執行,由參數897決定用Index Seek + Key Lookup並將執行計劃快取起來,第二次執行@p=870,但仍沿用快取的執行計劃,故仍使用Index Seek。
做個實驗,我們重啟SQL Server(強制將快取清空,或使用指令DBCC FREEPROCCACHE就不用重啟)並將指令前後對調,先跑870(4688筆)再跑897(2筆):
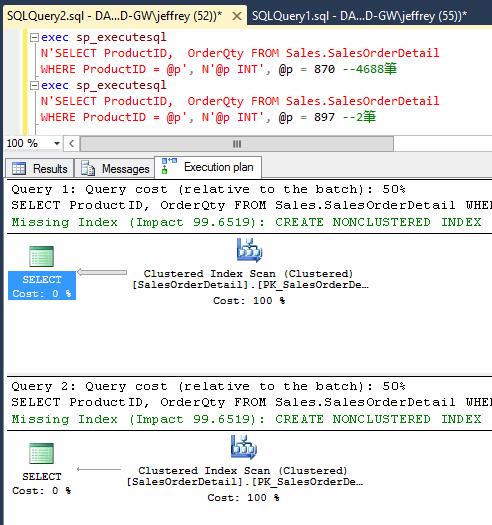
兩次都走Index Scan,證明第一次的執行計劃被快取,第二次沿用。
再來一個實驗,故意在兩次SQL指令加上不同註解:
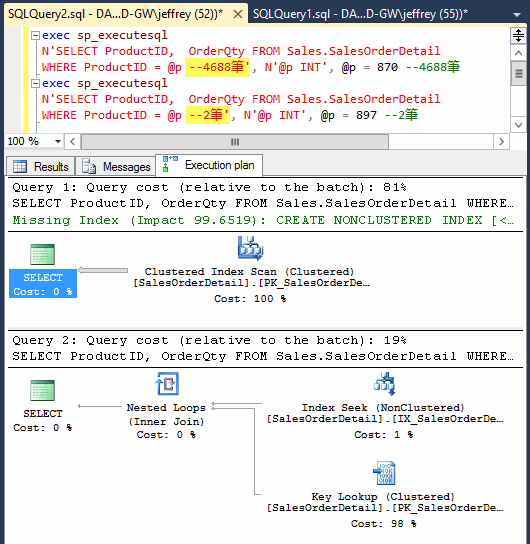
SQL指令有別(黃底註解部分不同),不共享快取,出現兩份執行計劃,各自最佳化。但是,這兩組快取也將被繼續用於各式參數值,未必為最佳化選擇。
由以上實驗,理出三點結論:
- 只有Literal式寫法(WHERE Product=870)才能保證SQL針對該次查詢條件進行最佳化。
- Variable會阻礙SQL分析,只能依統計平均值決定執行計劃。
- SQL會針對第一次的Parameter值執行分析選定執行計劃,並存入快取沿用,不因後續傳入參數值重新分析調整。
留下一個疑問:「Stored Procedure可重覆使用執行計劃,有助提升效能」是常識,但實驗可知Literal寫法才能確保SQL針對當次查詢條件最佳化,如此卻又無法重覆利用執行計劃,二者矛盾?
是的,凡事都有取捨,看起來我們得在「浪費效能重新編譯SQL指令決定執行計劃」與「未依當下條件參數選用最佳執行計劃」間抉擇。前面提過,實務上重新編譯SQL指令耗損的資源比沒選用「最佳」執行計劃的代價高一點,所以「重覆利用執行計劃可提升效能」才會變成常識。當然,凡事總有特例,若你遇到執行計劃快取會讓SQL誤判暴慢的情境,有一些救濟手段,執行Stored Procedure時可以加入WITH RECOMPILE,若使用sp_executesql,則可寫成SELECT … FROM … WHERE … OPTION (RECOMPILE),強迫每次重新編譯重新針對參數選擇執行計劃,但要記住,非常手段自有其副作用,多半只適用於非常狀況,使用前宜謹慎評估。
Comments
Be the first to post a comment