KB-Catch Deadlock Event in SQL 2005
 |  | 1 |  |  |
Transaction (Process ID 60) was deadlocked on lock resources with another process and has been chosen as the deadlock victim. Rerun the transaction.
之前開發的一個糸統,隨著使用負荷逐步增加,開始出現一些Deadlock的狀況。所謂的Deadlock,簡單來說,就是兩個個體分別鎖定了對方下一步要變更的資源,在等待對方讓步釋出資源的過程中形成僵持,此時多半由管理機制強迫其中一方作為犠牲者(Victim),成全另一方。在DBMS裡,被挑中犠牲的Process就會得到如上的Database錯誤訊息。[延伸閱讀: SQL Server 系統效能調校(Part III) by 胡百敬]
在一般的設計準則中,針對可能發生Deadlock的場合,應安排稍後Retry的邏輯。但Deadlock會引發Exception、Rollback及Retry,是相當凶狠的效能殺手,真正的上策還是應設法避免Deadlock的發生。於是一個重要的課題來了--得先知道Deadlock怎麼發生的,才談得上預防!
追蹤Deadlock的發生點以往算是高難度的工作,但SQL 2005 Profiler裡的Deadlock Graph卻把它簡化到像用傻瓜相機拍照一樣簡單。
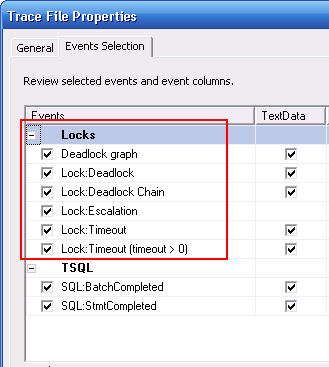
開啟SQL 2005 Profiler,指定要捕捉Lock相關事件,剩下的就是等待或故意製造Deadlock。有一點要注意的是,Lock:Deadlock Chain的LoginName是空白,Deadlock:graph的LoginName是'sa',Lock:Deadlock的LoginName才會是你連線使用的Login身份,在設Filter條件若只限定連線用的Login身份,會錯失Dead Graph等重要線索。搞懂這點之前,我做了幾次虛工。
一旦抓到Deadlock Graph,一切盡在不言中,兩個Process互相挾持了什麼Resource,一目了然。

如上圖,Process 81對PK_WorkList做了RangeS-U Key Lock後準備要新增WorkItem,而Process 60則先對PK_WorkItem放了RangeS-S Key Lock後,打算更新WorkList,二者僵持不下,倒楣的Process 60上的藍色大叉叉代表它在這場衝突中壯烈犠牲了,這就是前述Deadlock Exception的由來。[註: 關於RangeS-S這類Index Range Lock的深入說明,可以看這裡]
由此可以得知,Process 60在Transaction中先讀取WorkItem再更新WorkList,而Process 81則先更新了WorkList,再打算新增WorkItem,如果將二者調成一致,均先WorkItem再WorkList,Deadlock的情況便可大幅改善。
最後補充一點,上圖中Deadlock Graph的Extract Event Data可以產生一個XML檔案,其中包含Deadlock更完整的資訊,甚至有出問題的T-SQL可以看,對於找出Deadlock的精確位置非常有幫助!
Comments
# by KKMAN
感謝黑大這篇文章的解說。 今天利用您早在2007年寫的文章來抓DeadLock依舊好用。 另外,引用您的文章於我的Blog。 感謝您造福我們IT人啊!