SQL筆記:Index Scan vs Index Seek
| | | 3 | |
寫這篇筆記是因為前陣子在實驗SQL查詢效能,發現自己對於「相似的SQL查詢有時使用Index Scan,有時又選擇Index Seek」的行為有些迷惑,決定花點時間重新認識這幾個基本資料庫概念。(對於SQL我只有玩票的水準,內容如有謬誤,敬請指正)
當我們對資料庫下達SELECT … WHERE …指令,資料庫引擎必須對指令進行分析,找出最有效率的方法儘快查到資料算出結果,而這個「找到資料算出結果的方法」就是所謂的執行計劃(Execution Plan)。要從資料表找到指定的資料,有很多做法,最笨的方法就是整個資料表每一筆都翻出來檢查(Scan),或者預先把常查的欄位拉出來排序做成索引(Index),找資料時先查索引,再透過索引指向資料所在位置。(就像查字典時由注音找到字,再翻到指定頁數)
以下是在資料表找資料的幾種做法:
Table Scan
當資料表沒有任何Index,資料庫引擎唯一的選擇是讀取整個資料表逐筆比對。查詢過程耗費時間與結果筆數無關,因為整個資料表要掃一遍,這是最沒效率的做法。
Clustered Index Scan
當資料表有建立Clustered-Index,評估查詢條件無法藉由其他Index加速,資料庫引擎逐筆讀取整個Clustered Index進行比對,由於全部資料要掃一次,查詢耗費時間不受結果筆數影響。
由於Clustered Index順序與資料實際儲存順序一致,不需要額外尋找動作(例如:Key Lookup)就能讀到SELECT要求的欄位。Index Scan
查詢條件包含Index的組成欄位,資料庫引擎逐筆讀取Index(由第一筆到最後一筆),從中找出符合者。若SELECT要求Index未包含的欄位,則還需透過Key Lookup找到資料列讀取資料。不管最後找到幾筆,都得讀完整個Index,尋找過程耗費時間與結果筆數無關(不考慮讀取資料時間)。
Index Seek
當查詢條件包含Index組成的第一個欄位(由此可知,建立多欄位Index時順序很重要),資料庫引擎可透過B Tree演算法較快找到第一筆相符資料,逐筆讀取直到資料不相符為止(如同Index Scan,必要時還需配合Key Lookup),Index Seek時間長短與結果筆數多寡成正比。
一般而言,Index Seek比Index Scan有效率,但當資料表很小,或結果筆數佔全部資料的比例偏高,Index Scan邏輯單純,有可能比Index Seek來得快。資料庫引擎很聰明,有能力依結果筆數佔全部資料比例,決定該用Index Seek還是Index Scan。
我們來用實驗證明看看。以SQL 2014 Express搭配範例資料庫Adventure Works 2008為樣本,挑選有12,1317筆的Sales.SalesOrderDetail,SalesOrderDetail為ProductID欄位建過Index,我們就以ProdcutID當WHERE條件。
開始前先用以下查詢了解各ProductID所佔筆數,整個SalesOrderDetail共出現266種ProductID,不同ProductID的資料筆數從4688到2筆都有。
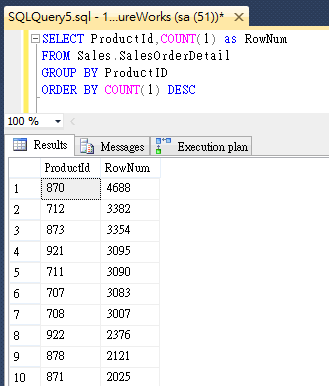
挑了六個不同的ProdcutID值查詢資料表,讀取其ProductID及OrderQty(OrderQty不在Index中)。
SELECT ProductID, OrderQty FROM Sales.SalesOrderDetail WHERE ProductID = 870 --4688筆 SELECT ProductID, OrderQty FROM Sales.SalesOrderDetail WHERE ProductID = 871 --2025筆 SELECT ProductID, OrderQty FROM Sales.SalesOrderDetail WHERE ProductID = 766 --460筆 SELECT ProductID, OrderQty FROM Sales.SalesOrderDetail WHERE ProductID = 972 --380筆 SELECT ProductID, OrderQty FROM Sales.SalesOrderDetail WHERE ProductID = 937 --255筆 SELECT ProductID, OrderQty FROM Sales.SalesOrderDetail WHERE ProductID = 723 --52筆 |
執行查詢並觀察執行計劃:
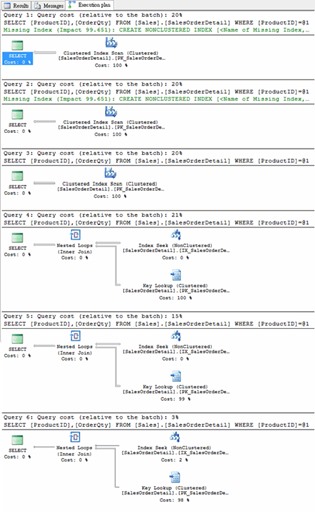
六組查詢的結果筆數分別為4688、2025、460、380、255及52筆,先前的理論獲得兩點印證:
- 結果筆數多時,Index Scan比Index Seek划算
六次查詢的結果筆數由多至少,前三次SQL決定使用Cluster Index Scan,後三次則是Index Seek + Key Lookup。證實結果筆數佔總筆數的比例愈高,SQL愈傾向使用Index Scan而非Index Seek。
至於比例超過多少用Index Scan較好,似乎不是由固定數字決定,猜想SQL或各家資料庫系統自有一套複雜演算法,以達到查詢效能最佳化。
至於前三次為何不用包含ProductID的Index做Index Scan,而是不包含ProductID的Clustered Index Scan?(Clustered Index欄位為SalesOrderID及SalesOrderDetailID)
Clustered Index與實際資料儲存順序一致,可以省去Index Scan完的Key Lookup步驟,SQL應是評估Clustered Index Scan比Index Scan+Key Lookup更有效率而做的決定。 - Index Scan的搜索時間與結果筆數無關
前三次查詢結果分別為4688、2025及460筆,但由其佔時間均為六次查詢總時間的20%,證明使用Index Scan時,不管結果多寡,花費的搜索時間相同。(此處不考慮讀取資料傳回的成本)
【結論】
相同的SELECT … WHERE Col = 'Blah'查詢,會因為'Blah'值不同,有時用Index Scan,有時用Index Seek,這是SQL Server基於執行效率考量的結果。
Comments
# by Billy
這篇文章有矛盾啊。 一般而言,Index Seek比Index Scan有效率,但當資料表很小,或結果筆數佔全部資料的比例偏高,Index Scan邏輯單純,有可能比Index Seek來得快。 Billy: 上面這段說資料筆數少時 Index Scan 較快,但下面這段說資料筆數多時Index Scan 更划算 資料筆數多時,Index Scan比Index Seek划算 ====================== 還有,根據以下文章: http://blog.sqlauthority.com/2007/03/30/sql-server-index-seek-vs-index-scan-table-scan/ Index Scan: the cost is proportional to the total number of rows in the table 但在你的文章裡卻說 Index Scan 尋找過程耗費時間與結果筆數無關。
# by Jeffrey
to Billy, 如你所引用的文章,Index Scan的成本與資料表的「總筆數」(total number of rows in the table)有關,與查詢結果筆數無關。 假設資料表總共有1000筆資料,用Index Scan查出100筆跟查出1筆耗費的時間是相同的(不含讀取欄位內容),所以當資料表總筆數少或結果筆數佔了總筆數一半以上,用Index Scan就可能比Index Seek划算。 「資料筆數多時,Index Scan比Index Seek划算」應修正為「結果筆數多時,Index Scan比Index Seek划算」。 我想文章有些地方表達得不夠清楚,謝謝你的指正。
# by Steve Kwok
是否應該說, 結果筆數對比資料表總筆數比例高時,Index Scan才比Index Seek划算?