GUID 叢集索引測試 3 - 觀察索引重組與索引重建對寫入動作的影響
| | | 4 | |
接連兩篇談完 GUID 叢集索引會造成 INSERT 變慢以及資料表虛胖,簡單有效解決是另建 BIGINT 或 INT 自動跳號欄位當叢集索引,GUID 仍可做為 Primary Key。(參考:GUID Primary Key 資料庫避雷守則)
對上線運轉多年的現有系統來說,Schema 很難說改就改,異動資料表欄位如同飛航過程修改飛機骨架,光用想的就頭皮發麻,尋求可以減緩 GUID 叢集索引負面影響的對策才是較務實的做法。套句廣告詞:先求不傷身體,再講求效果。
要改善 SQL Server 索引碎片化問題,主要可透過索引重建(Rebuild)或索引重組(Reorganize),而索引重建再分為離線作業及線上作業(加上 ONLINE = ON 參數) ,故共有三種選項:
- ALTER INDEX ... ON ... REBUILD
離線執行重建,所需時間最短,但過程需卸除和重新建立索引,期間資料庫無法使用 - ALTER INDEX ... ON ... REBUILD (ONLINE = ON)
線上索引重建,期間資料表可繼續使用,但修改資料時需更新索引的額外副本,影響效能 參考 - ALTER INDEX ... ON ... REORGANIZE
重新組織索引耗費的資源最少,是官方最建議的做法,期間資料表可繼續查詢或更新,但耗費時間較久
延伸閱讀:
離線重建索引是最快的,但營運中的系統也不太可能為了重建索引停用資料表,我試在 INSERT 過程執行 ALTER INDEX ... ON ... REBUILD,不意外地當下那筆作被卡住 15 秒直到重建完成,
1000001: 0ms
1000002: 0ms
1000003: 0ms
1000004: 0ms
1000005: 15596ms
1000006: 0ms
1000007: 0ms
1000008: 0ms
不管是線上索引重建或索引重組,執行同時一定會影響效能,所以我修改了先前的測試程式,計劃完成三組測試:
- 每 10 萬筆觸發索引重組(若前次沒做完就跳過),在 GUID 叢集索引資料表 INSERT 1000 萬筆
- 每 10 萬筆暫停寫入,執行索引重組(想像成離峰時間執行,不影響日間作業)再繼續,在 GUID 叢集索引資料表 INSERT 1000 萬筆 3. 每 10 萬筆觸發線上索引重建(若前次沒做完就跳過),在 GUID 叢集索引資料表 INSERT 1000 萬筆
程式如下,每 10 萬筆觸發另起 Task 同步跑 ALTER INDEX ... ON ... REORGANIZE,用 bool Running 偵測前次若在執行中就略過。
using System.Diagnostics;
using Microsoft.Data.SqlClient;
public class SqlRunner
{
const string cs = "data source=.;initial catalog=FragPerfTest;integrated security=True;encrypt=false";
public enum TableNameEnum
{
GuidClustIdx,
IntClustIdx
}
static int CurrRowIdx = 0;
static int NextReorgIdx = 0;
public static void InsertData(TableNameEnum tableName, long rowCount, int reorgCount)
{
NextReorgIdx = reorgCount;
using var cn = new SqlConnection(cs);
cn.Open();
using var cmd = new SqlCommand($"INSERT INTO {tableName} (PK, LongText) VALUES (@pk, @text)", cn);
cmd.CommandTimeout = 300;
var pPK = cmd.Parameters.Add("@pk", System.Data.SqlDbType.UniqueIdentifier);
var pText = cmd.Parameters.Add("@text", System.Data.SqlDbType.NVarChar, -1);
pText.Value = new string('x', 1000);
var sw = new System.Diagnostics.Stopwatch();
Directory.CreateDirectory("logs");
Func<string> getFileName = () => $"logs\\Test-{DateTime.Now:MMdd-HHmmss}.txt";
StreamWriter logger = new StreamWriter(getFileName());
for (var i = 0; i < rowCount; i++)
{
CurrRowIdx = i;
pPK.Value = Guid.NewGuid();
sw.Restart();
cmd.ExecuteNonQuery();
sw.Stop();
if (i % 100 == 0) Console.WriteLine($"{i:n0} Rows Inserted");
if (i % 500_000 == 0)
{
logger.Flush();
logger.Dispose();
logger = new StreamWriter(getFileName());
}
logger.WriteLine($"{i + 1}: {sw.ElapsedMilliseconds}ms");
if (i > NextReorgIdx)
{
Task.Run(() => ReoraganizeIndex(tableName));
NextReorgIdx += reorgCount;
}
}
logger.Flush();
logger.Dispose();
}
static bool Running = false;
const string logPath = "results\\ReorgIndex.log";
public static void ReoraganizeIndex(TableNameEnum tableName)
{
if (Running) return;
try
{
Running = true;
Console.WriteLine("Reorganizing Index");
int startRowIdx = CurrRowIdx;
var sw = new Stopwatch();
sw.Start();
using var cn = new SqlConnection(cs);
cn.Open();
using var cmd = new SqlCommand($"ALTER INDEX PK_{tableName} ON {tableName} REORGANIZE", cn);
cmd.CommandTimeout = 0; // No Timeout
cmd.ExecuteNonQuery();
int endRowIdx = CurrRowIdx;
sw.Stop();
Console.WriteLine($"Reorganize Index Elapsed: {sw.ElapsedMilliseconds}ms");
File.AppendAllText(logPath, $"{tableName} from {startRowIdx} to {endRowIdx} rows, Elapsed: {sw.ElapsedMilliseconds}ms{Environment.NewLine}");
Running = false;
}
catch (Exception ex)
{
Console.WriteLine(ex.Message);
File.AppendAllText(logPath, ex.Message + Environment.NewLine);
}
}
}
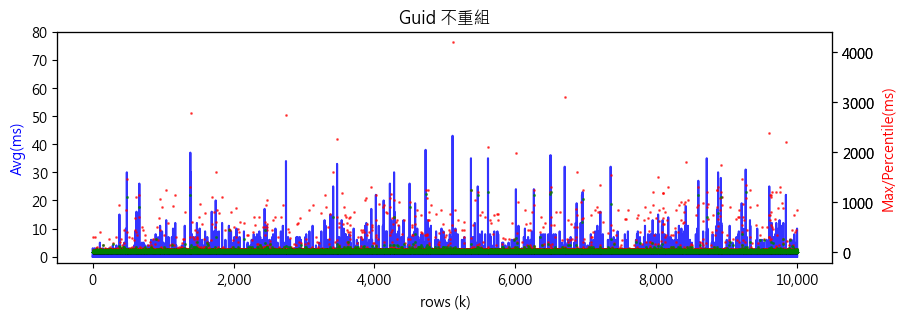
先看沒有索引重組或線上索引重建的數據:
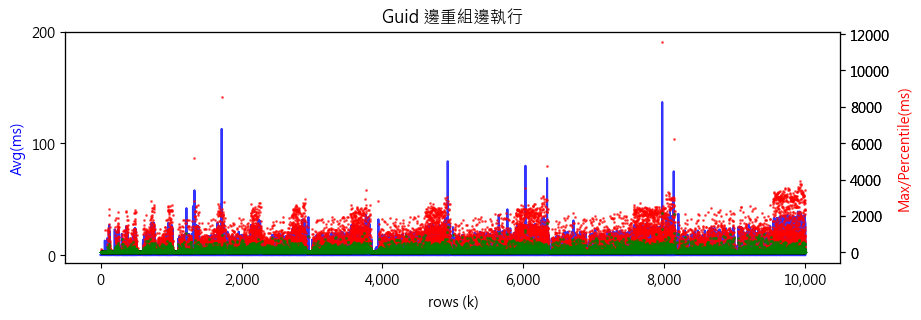
邊索引重組邊 INSERT 的數據如下,最大值不時會拉長到 1 秒以上,但 99% (綠色) 仍壓在 0.5 秒以下,不算太嚴重。1000 萬筆寫入時間變長兩倍多,由兩小時出頭延長到六小時。
將 Task.Run(() => ReoraganizeIndex(tableName)); 改為 ReoraganizeIndex(tableName);,模擬每天離峰索引重組,看看結果比不重組改善多少。有點意外,我沒看出明顯改善:
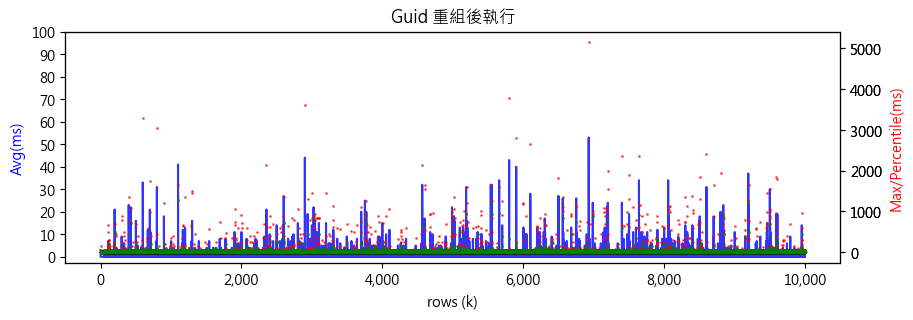
第三組測試比照邊索引重組邊 INSERT,但改成一邊線上索引重建(ALTER INDEX ... ON ... REBUILD (ONLINE = ON) )一邊 INSERT。線上索引重建對寫入效的影響比較明顯,最大值不時突破 10 秒,大部分的寫入還是可以零秒完成,但平均值跟 99 百分位數都拉高了,而 1000 萬筆寫入時間拉長 10 倍跑了 10 小時才完成。

而另一個值得觀察的點是邊 INSERT 邊重組、專心專組、邊 INSERT 邊重建耗費的時間。
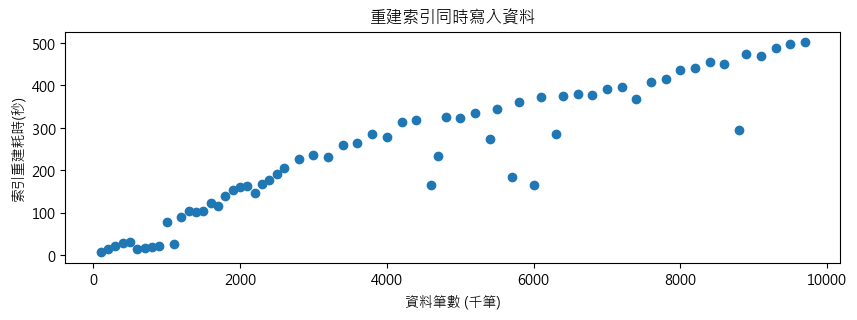
邊 INSERT 邊索引重組與資料筆數大致成線性關係,由於需待前次做完進行下次,執行時機不固定,最後一次發生在 680 萬筆左右,耗時超過一小時 (4472 秒, 1h14m)。
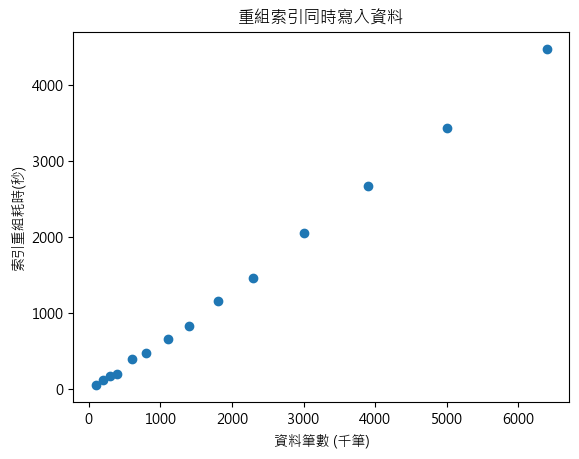
停止 INSERT 專心索引重組耗時與資料筆數也是呈線性關係,但時間大幅縮短一半,1000 萬筆耗時 1352 秒,只要 22 分鐘。
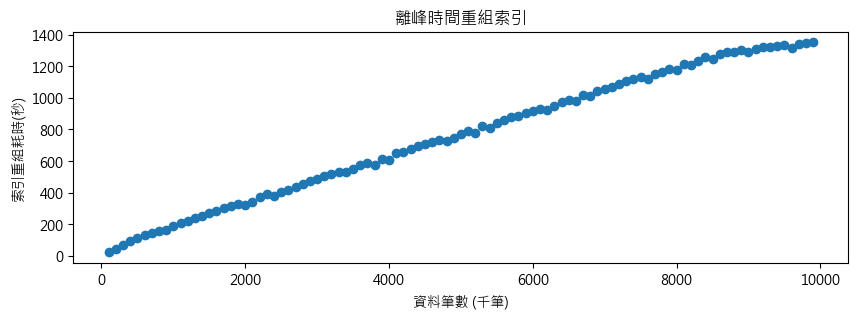
若不考慮執期間影響寫入作業的效能,線上索引重建比線上重組有效率多了,1000 萬也只要 502 秒,八分多鐘,快了 N 倍。
做個結論:
- 索引重組或索引重建對 GUID 叢集索引 INSERT 作業的效能改善不明顯(但原本也不嚴重就是了),但減少資料分頁數量、消除碎片化及節省磁碟空間有益無害。
- 如果系統有明確的離峰時段(當下極少人使用,且能容忍延遲),線上索引重建是最有效率的做法;由測試結果,索引重組對 INSERT 效能的影響比預期小,邊重組邊寫入造成的效能拖累不明顯。
不過,如果可以,避免用 GUID 當叢集索引(當 PK 沒問題,但好像不少把兩件事綁在一起)是更好的解法。
Comments
# by love asp.net core
黑大你好,刚刚搜索到你之前关于动态修改cshtml的文章: https://blog.darkthread.net/blog/razor-runtime-compilation/ 和我的需求一样,也是想像原aspx的模式一样动态修改cshtml文件,测试后成功,对我很有帮助,但遇到一个问题是,如果将asp.net core 发布成单独文件的模式,即PublishSingleFile模式,则访问页面的时候会另程序发送错误: Microsoft.AspNetCore.Diagnostics.ExceptionHandlerMiddleware[1] An unhandled exception has occurred while executing the request. System.ArgumentException: The value cannot be an empty string. (Parameter 'path')... 好像找不到不到pages下的cshtml文件一样而造成无法动态编译的现象。请教黑大这个问题有无遇到过,应该如何解决呢?谢谢!!
# by Jeffrey
to love asp.net core, 我不確定 PublishSingleFile 與獨立 cshtml 檔二者相容,直覺二者的目標是衝突的。Github 上有則 Issue 是你提的嗎? https://github.com/dotnet/aspnetcore/issues/54315 看能不能蒐集到其他高手的看法。
# by love asp.net core
to 黑大,首先感谢能回复我的提问,asp.net github的issue是我提的,我刚接触到asp.net core,感觉razor模式就不应该把所有的cshtml打包,而是应该把cshtml视为外部可编辑页面作呈现用,可随时修改html内容随时生效,如果把它们都编译到整个程序中,本身这种设计就太笨重了。还有就是发现如果不用PublishSingleFile 模式发布,就会自带一堆十分多的dll文件,且不能指定这些附带DLL的路径(至少在googlle上找不到一个完美官方的解决办法),这样发布后的文件夹就会有几十个上百个文件,要找到.exe文件都难,真不理解.net团队是基于何种理由这样设计。
# by love asp.net core
to 黑大, 上面关于 PublishSingleFile模式 下asp.net core razor 动态编译的问题已经解决了,通过分析asp.net core 的源代码得到的信息问题出在PublishSingleFile发布后重新动态加载内嵌式程序集的方式,不能再以外部单独文件方式动态加载了,只能以内嵌方式加载,因此只能修改RuntimeCompilation的源代码重新编译使用,特向你反馈下这个信息,也同时向你对大众有关技术方面的帮助表示感谢!