【茶包射手日記】HtmlDecode 鬼打牆記
| | | 4 | |
好久沒有鬼打牆,PO 文紀念兼反省。
有個網站代理下載功能,要從 HTML 用 Regex 擷取某個下載 URL,經過加密轉交 ASPX,由 ASPX 自其他主機下載內容再轉回瀏覽器。 (資安提醒:設計這類應用請務必確認 URL 不存在被使用者竄改的風險,以免淪為跳板或後門)
處理過程發現 HTML 中的 URL 有被 HtmlEncode 過,& 變成 &,於是我加了 HttpUtility.HtmlDecode 還原。URL 傳給下載程式後出現 HTTP 404。在程式加了 Response.Write 列印接收到的 URL,看起來又沒問題,複製該 URL 用瀏覽器開啟也正常。我陷入瘋狂找蟲模式,從 HTML Regex 解析、加密傳送、接收解密... 等環節逐一清查,但線索彼此矛盾,前後耗了近個把小時也沒能破案。好久沒有這種感覺了,嗯,我鬼打牆了!
由於只能在測試台測試,無法靠 Visual Studio 檢查變數內容,我偵錯的關鍵線索來自以下這段 Response.Write():(註:內含低級錯誤)
<%@Page Language="C#"%>
<script runat="server">
void Page_Load(object sender, EventArgs e)
{
//這段是後來加上的偵錯資訊顯示
Response.ContentType = "text/plain";
var remoteUrl = ParamHelper.GetUrl();
var chk = "http://blah.net/?a=1&b=2";
Response.Write("<li>" + remoteUrl + "\n");
Response.Write("<li>" + chk + "\n");
try
{
Response.ContentType = "application/octet-stream";
Response.AddHeader("Content-Disposition", "attachment;filename=" + fileName);
//取得檔案內容若出錯,跳至 catch 段顯示錯誤訊息
//Response.BinaryWrite(WebClient.DownloadData(remoteUrl));
//模擬下載出錯
throw new ApplicationException();
}
catch (Exception ex)
{
Response.ClearHeaders();
Response.Write(ex.Message);
Response.End();
}
}
</script>
ParamHelper.GetUrl() 取得結果跟比對用的 chk 變數看似相同,複製貼上也能下載,但 WebClient.DownloadData(remoteUrl) 卻會噴 HTTP 404:
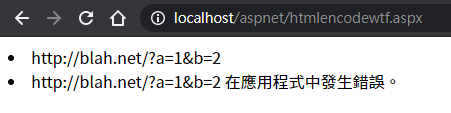
冷靜之後,我試了 WebClient.DownloadData(chk) 發現可以成功,比對 Response.Write(remoteUrl == chk) 傳回 false,這才確認眼見不為憑,remoteUrl 跟我想的不一樣,進一步比對 remoteUrl.Lentgh != chk.Length,動用 BitConverter.ToString(Encoding.UTF8.GetBytes(remoteUrl)) 逐字元檢查,終於真相大白! remoteUrl 中的 & 其實是 &,並沒有被 HtmlDecode() 還原。
且慢,既然是 & 為何已將 ContentType 設成 text/plain 會看不出來,此時發現我犯的低級錯誤。原本程式邏輯會設 ContentType = "application/octet-stream" 並 Response.AddHeader("Content-Disposition", "attachment;filename=" + fileName) 產生檔案下載行為,故在 catch 出錯要顯示訊息時呼叫了 Response.ClearHeaders() 以正確傳回文字,導致結果以 HTML 格式呈現(圖中 <li> 變成清單點點是證明,但當下我不疑有他),在 HTML 模式下,& 與 & 看起來都是 &。
追回源頭,我明明有做了 HttpUtility.HtmlDecode() (其實這裡還有個插曲,最初腦袋不清,HtmlUrlDecode()、HtmlEncode() 傻傻分不清楚),為什麼 & 沒被換掉。這個是我犯的另一個低級錯誤,之前在 IE 檢視 DOM 看到以下內容:
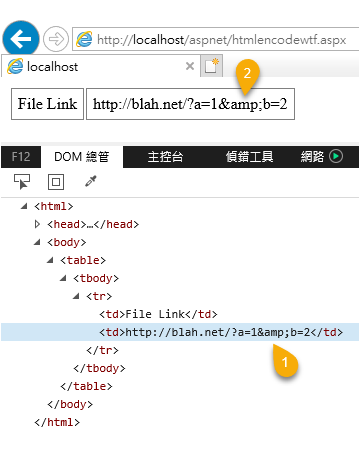
直覺判斷 td 的 InnerHTML 是 http://blah.net/?a=1&b=2,但 DOM 裡的 HTML 是 HtmlDecode() 過的結果,更何況上方網頁也顯示 &,所以它的內容應該是 &amp; 才對,這個 URL 被 HtmlEncode() 了兩次! 檢視原始碼即可證實:
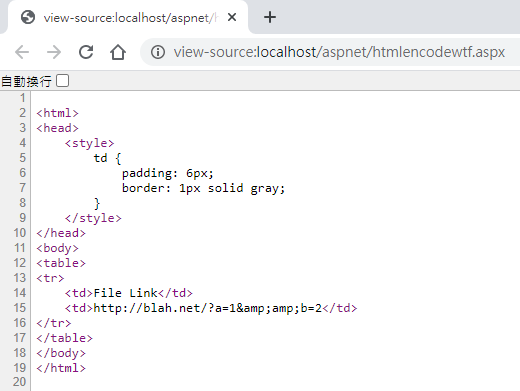
總之,原本是個小問題,HtmlDecode() 兩次就能解決,我卻因連續兩個低級錯誤,鬼打牆大半天。記非受迫性失誤兩次並自我檢討。
Experience of trouble-shooting a double-HtmlEncode() issue.
Comments
# by Ike
低級錯誤是不是「Response.Write("<li>" + chk + ""\n");」多了一個「"」
# by Jeffrey
to lke, 這是 PO 文時犯的低級錯誤,呵。程式若有這問題,會無法編譯看不到執行結果。
# by ByTIM
有時都會這樣,貼上網址列後,它會自己轉新格式,導致這種錯誤,通常有中文或特殊符號,才會有這種狀況。
# by Huang
我的習慣是二個視為一組,接受或發送就做,前端來什麼髒東西永遠不知道,順便永保資安 urldecode, htmldecode urlencode, htmlencode