硬碟故障經驗一則
| | | 5 | |
同事好心提醒,他的硬碟幾天前出現異狀,硬碟健檢程式回報健康度只剩55%,備份搶救已有部分檔案毁損。而最重要的,同一批採購的電腦前幾個月才有另一台也發生硬碟掛點!
依據多年搞電腦的經驗,同廠牌同期硬碟在某一時期集體暴斃時有所聞,不敢怠慢~ 執行Acronis Drive Monitor硬碟健檢程式,報告令人大驚失色,健康指數只剩5%!
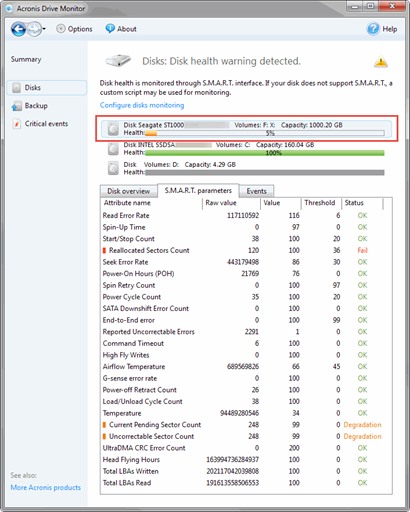
解讀數據,最嚴重的問題出在Reallocated Sectors Count(因硬碟磁區損壞重新分配到備用碟區的數量)。SMART資料有三種值,Raw Value為原始數據,Value為原始數據換算的健康指數,最大值通常為100、200或253,愈高表示愈健康,Threshold則為製造商允許的下限,當Value低於Threshold,代表已達保固條款可更換的門檻。【參考】
我的硬碟SMART 磁區重新配置數Value仍為100(門檻為36),但Raw Value已達120。我把它翻成白話文:硬碟已經有120個磁區損壞換到備用磁區,但廠商說備用磁區還很多不怕你壞,健康指標仍有100頭好壯壯,等低過36就會讓你換新硬碟哦!啾咪~ orz
依照另一份網路文件:
重新配置的磁區計數 (Reallocated Sector Count)
是代表硬碟碟盤上的磁區有壞軌,被分配到備用磁區的數量。
由於硬碟是極為精密的機械裝置,磁頭與高速旋轉中磁盤之間的間隙比灰塵還小上許多,因此硬碟極易受到外在因素(碰撞、溫度…) 的影響而發生壞軌。目前市面上的硬碟,都會預留一部份備用磁區,將壞磁區以重新指派到備用磁區的方式,來達到修復的功能。這個數字並不代表硬碟一定有問題,但如果在正常情況下使用硬碟,數目仍無端增加,那就是硬碟開始老化或快故障的徵兆。一般來說,此數字如果在個位數,並且沒有再增加,都還算在正常範圍。但如果RAID等級是 JBOD、RAID 0或是 NAS 是應用在存放關鍵資料,此數值大於1 時,我們仍建議換一個硬碟,以降低資料損毀的風險。
若要採較謹慎的態度:重配置數大量增加通常是硬碟快掛掉的前兆,對於儲存重要資料的硬碟,建議只要數值大於1就該更換。大於1就該換硬碟,拎杯已經飆到120啦!!
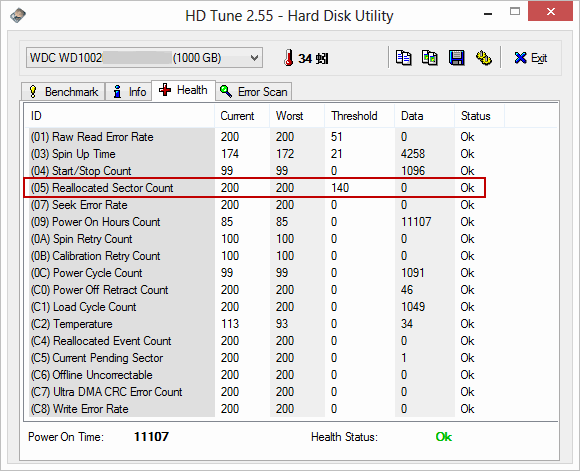
對照另一台用了三年多的機器的HD Tune檢測結果,Reallocated Sectors Count Data(Raw Value)為零,這才是我認為的正常值。
另外,Current Pending Sector Count飆到248代表還有很多不穩定的磁區將來也需要重新配置,另一件大事不妙的象徵。(但Value仍有99,要降到0才破門檻,廠商好有包容力,我可不行啊~)
好心同事們借我備用硬碟跟外接盒(發生硬碟集體暴斃的好處是急救裝備普及化,左右鄰居家就有心臟電擊器跟葉克膜),趕緊備份資料,要跟時間賽跑。
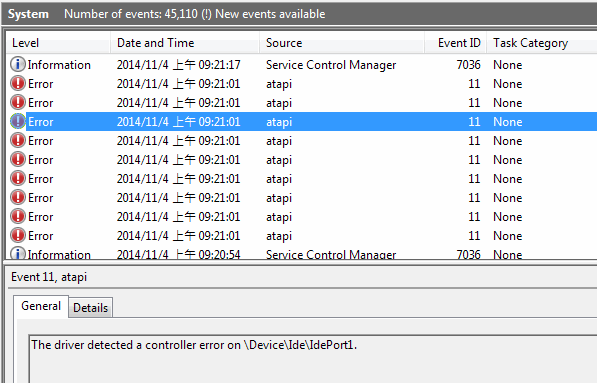
一旦全面複製資料,病入膏肓的硬碟再也瞞不住病情!一複製到特定檔案就會導致操作介面凍結,事件檢視器也可看到atapi嚴重錯誤The driver detected a controller error on \Device\Ide\IdePort1,代表讀檔時發出IO錯誤,硬碟真的病了!
放棄完整備份的希望,只求能搬愈多資料愈好,苦主同事介紹一套複製工具Unstoppable Copier,能忽略壞檔不中斷複製作業,盡可能保全最多檔案(記得要調成Fastest Data Recovery,搶時間救更多檔案)。複製1TB資料要超過6小時,下班放著執行等第二天看結果,未料隔天發現系統已重開機,複製作業只進行一半。好吧!再來一次,而這回我親眼目睹複製到特定檔案,進度停滯桌面凍結(Ctrl-Alt-Del也沒反應),數分鐘後出現Blue Screen… 這應該也是昨夜重開機的原因。
不得已,避開問題資料夾,依重要性排序,一次只複製一個,救多少算多少。最後,只捨棄了四五個資料夾,受損資料在版控伺服器或其他來源也可以找到,損失不算重大。但重新安裝作業系統、軟體及佈置環境是免不了,耗掉寶貴的專案時程。
今天,健檢報告出爐後第七天,發現硬碟已從系統上消失,再也回不來了。感謝同事提醒,躲過一次無預警硬碟掛點災難~
【心得整理】
- 一直以為SSD陣亡率比傳統HD高,所以大家都習慣把重要資料放在傳統HD,但接連三台使用兩年機器都是SSD安裝無羔,傳統HD掛點,令人頗為意外。
(看來,HD不一定比SSD耐操!但SSD故障多是瞬間消失,連說再見的機會都沒有,HD一般在出怪聲,有異狀後,仍有一點時間能搶救資料,相較之下仁慈一點) - 機器因作業需求得24小時開機,而故障HD機型非企業等級,可能是壽命不如預期的原因之一。
註:硬碟可區分為一般級及企業級。企業級硬碟依7x24小時運轉情境要求MTBF(平均使用多少小時才會出現故障),並提供較長年限保固,依理較耐操。一般級硬碟設想情境為5x8小時,當使用量高於此標準,壽命就可能低於其號稱MTBF小時。 - 這回能在HD掛點前提早搶救資料,歸功於同事的警示(感謝!)。問題HD雖然重配置磁區數已達120,但掃瞄不到任何損壞磁區(壞掉部分應該都已改用備份磁區頂替),依廠商標準,它仍算健康不到需保固換新的標準。但依這次經驗,HD早已病入膏肓,只要讀到特定碟區就會有嚴重錯誤,且在七天後就歸西了~ 若非全碟備份讀到問題區域出現桌面凍結及IO錯誤,之前使用完全未察覺任何異狀。
面對這種無形殺手,我想定期檢查SMART指標是唯一手段,文章提到的Acronis Drive Monitor及HD Tune都是可用工具。 - 試用USB 3.0硬碟外接盒寫入資料,極速可達150MB/s,已達HD寫入上限。對單一HD,USB 3.0很夠用,不一定要SATA。
- 備份才為王道
重要專案資料有版控後援,不用太擔心,一些重要資料也會定期備分到其他主機上。 但一些資料如VM的磁碟映象檔(Image)動輒數十GB,除非備妥相同容量或更大容量的儲存媒體,沒什麼較好的解決方案。(NAS是不錯的解決方案,但工作設備購置受限較多,不若家裡自由,只能隨緣)
系統碟裝在SSD,但沒做完整備份,導致無法快速重灌還原,值得改進。未來考慮在HD上保留SSD相同容量空間,定期完整備份,以求加速災難還原速度。
Comments
# by pat liang
我想請問一下行Acronis Drive Monitor硬碟健檢程式好像不支援usb3.0外接raid的小型磁碟機
# by Jeffrey
to pat liang,依官方文件(http://www.acronis.com/zh-tw/personal/hard-drive-health/)它支援大部分的USB外接硬碟。但依我的認知,SMART技術較偏向單一硬碟的狀態數據,RAID包含多顆硬碟,能否適用看RAID Controller。文件提到「編寫指令碼功能可讓您監控並未使用 S.M.A.R.T. 監控技術的 RAID 控制器。」,需要一些額外功夫才可能成功。一些外接RAID自己就內建硬碟狀況監控機制,或許可以從裝置本身著手。
# by 鐵衛
救資料請使用 Raise Data Recovery 這是小弟實驗過數十套軟體以來最好用ㄉ,磁碟機代號消失也可救,資料讀取不出來不會當機在那邊,資料可以盡量救出(即便他是不完整也能把能讀取的部分救回),救援完成會有詳細報告 還有其他很多功能 ... 另外根據小弟的經驗 hitachi 和 wd 的 red 型號故障率最低,Seagate 最高 ...千萬別買
# by Kelu
硬碟無法讀取,還有方法讀取其資料嗎?
# by Jeffrey
to Kelu, 我對資料救援研究不多,你可以Google「資料救援工具」或「資料救援服務」找找,但要有心理準備,不保證資料一定救得回來,只能盡人事聽天命,且代價不斐。