.NET Core .cshtml 及 JSON 之 UnicodeRange 編碼範圍設定
| | | 3 | |
.NET Core 開始,文字編碼處理原則有點改變。在預設情況下,.cshtml 轉換 HTML 時會將「中文」兩字轉成 Hexadecimal Character References -「中文」,需加上 Services.AddSingleton<HtmlEncoder>(HtmlEncoder.Create(allowedRanges: new[] { UnicodeRanges.BasicLatin, UnicodeRanges.CjkUnifiedIdeographs }));避免;而 System.Text.Json 狀況類似,「中文」兩字會被轉成 UCN (Unicode Character Name) - 「\u4e2d\u6587」,可藉由設定序列化 Enoder 參數 JavaScriptEncoder.Create(UnicodeRanges.BasicLatin, UnicodeRanges.CjkUnifiedIdeographs); 解決。
不過,實務運用時會發現只設 BasicLatin 及 CjkUnifiedIdeographs 不太夠,仍有些常用字元會被轉成 \uXXXX 編碼,這篇筆記將介紹如何因應。
首先,Unicode 字元之所以要編碼,目的是防止接收端或處理過程有程式無法正確處理某些 Unicode 字元,若確定資料處理全程均支援 UTF-8,那麼設定 UnicodeRanges.All 是最省事的做法。
當發現某些字元沒被涵蓋到,要怎麼調整?
例如:對 "😎 你知道 0xffff 等於 65535 嗎?" 進行 JSON 轉換,會得到 "\uD83D\uDE0E 你知道 0x\uFB00\uFB00 等於 65535 嗎\uFF1F"。Emoji、相連 f 字元跟全型問號被編碼。
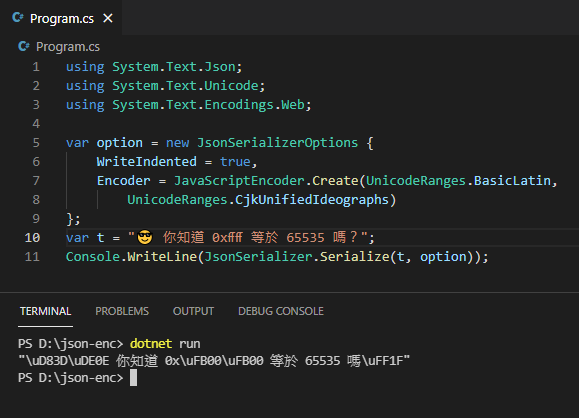
想知道增加哪個 UnicodeRange 可涵蓋 「ff」,可從 \uFB00 得知其 Unicode 碼為 U+FB00,在 Visual Studio 或 VSCode 對 UnicodeRanges 按 F12 檢視定義可查到所有 UnicodeRange 選項,註解很貼心地都有註明編號範圍,U+FB00-U+FB4F 屬於 Alphabetic Presentation Forms Unicode block,全型標點符號為 U+FF00-U+FFEE - Halfwidth and Fullwidth Forms Unicode block:
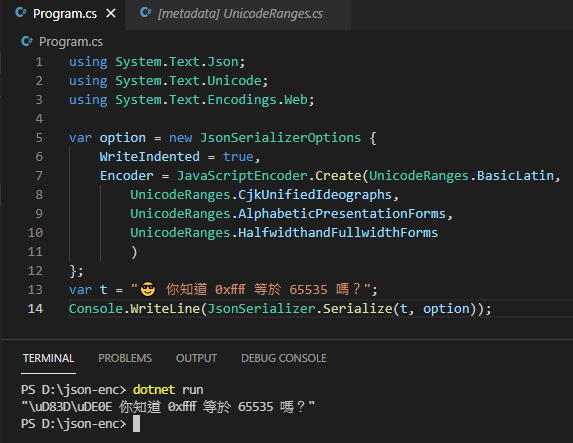
我們加上 AlphabeticPresentationForms、HalfwidthandFullwidthForms 後,只剩墨鏡 Emoji 還沒轉:
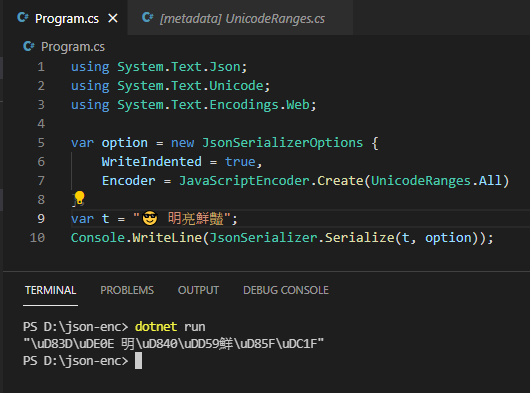
.NET 內建的 UnicodeRange 只涵蓋 BMP (Basic Multilingual Plane 基本多文種平面 U+0000 ~ U+FFFF),而墨鏡 Emoji U+1F60E 落在 SMP(Supplementary Multilingual Plane 多文種補充平面 U+10000 ~ U+1FFFF) (參考:維基百科 Unicode字元平面對映),故無法視為一般文字。事實上,有些冷僻中文字也會有類似狀況(延伸閱讀:Unicode 罕用字冷知識),即使設定 UnicodeRanges.All (整個 BMP,U+0000 to U+FFFF) 也無濟於事:
如果你真的想將它們涵蓋進去,Github 有網友製作可支援 SMP 的 UnicodeRange,我個人是覺得罕用字比率不高,不需花這個功夫。
【延伸閱讀】
- MS Docs: How to customize character encoding with System.Text.Json
- Developer PAPER: Escape and Unicode encoding in JSON serialization
Some tips about using UincodeRange to control encoding behavior of MVC view and System.Text.Json.
Comments
# by Howard
黑大 你好,我在用System.Text.Json遇到emoji會被轉成字元 你有提供網友製作的支援所有的SMP的程式碼 想請問這個要如何使用... 似乎不能直接加到Encoder = JavaScriptEncoder.Create(UnicodeRanges.BasicLatin, UnicodeRanges.CjkUnifiedIdeographs,UnicodeSMP.UnicodeRanges.Emoticons) 會出現無法轉換到system.text.unicode.unicoderange 還是有比較簡單的方法去處理emoji 感謝!!
# by Jeffrey
to Howard,好奇問一下,\uD83D\uDE0E 這種表示法,JSON Deserialize 後可順利還原成 Emoji,用起來應沒什麼不便,想在 JSON 中保持原始字元是有特殊考量?
# by Howard
喔喔 對耶,抱歉確實只要在Deserialize 就正常了 感謝!!