【茶包射手日常】不是眼見為憑,誰都別信
| | | 3 | |
解決了一個蒜皮小茶包,問題本身沒什麼營養,但辦案過程有點意思。
狀況為在 Windows 11 24H2 新電腦上安裝 SharePoint Designer 2013,安裝過程無錯,啟動時彈出以授權對話框:(示意圖如下,First things first 中文翻譯為「首要任務」,實際案例還包含三個下載安裝更新選項)

按下【Accept】同意授權合約,禮成,程式就關掉了關掉了關掉了...
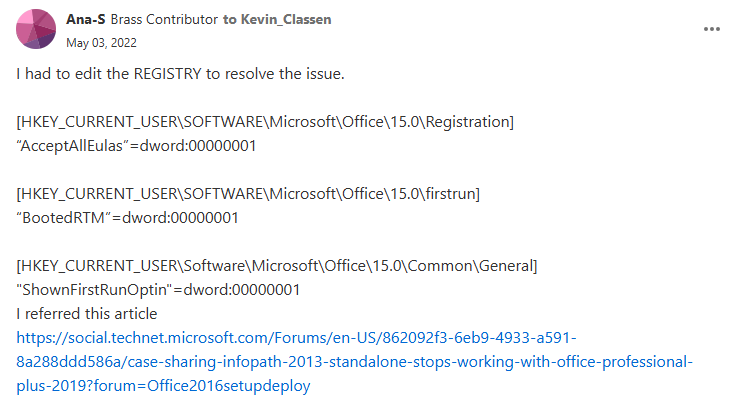
先用關鍵字找到一則討論,2022 起便有相似問題通報,有網友提供解藥一劑,參考 InfoPath 2013 類似問題解法,修改三個 Registry 可藥到病除,該解方經兩位網友留言證實有效。
當事人跟 Windows 交手多年,老經驗的他,想到一招免開 regedit 找機碼的做法 - 新增文字檔貼上三條設定加上標頭另存 .reg,再按右鍵選安裝可瞬間設定完成。
Windows Registry Editor Version 5.00
[HKEY_CURRENT_USER\SOFTWARE\Microsoft\Office\15.0\Registration]
“AcceptAllEulas”=dword:00000001
[HKEY_CURRENT_USER\SOFTWARE\Microsoft\Office\15.0\firstrun]
“BootedRTM”=dword:00000001
[HKEY_CURRENT_USER\Software\Microsoft\Office\15.0\Common\General]
"ShownFirstRunOptin"=dword:00000001
不料,設完 Registry 還是繼續跑出授權同意對話框,唯一差別是三個下載安裝更新消失,但按【Accept】後程式仍會終止。
試過重開機無效,當事人的初步結論是文章時間早在 2022,本案可能狀況不同,需另覓解方。
接獲案件通報,老射手眉頭一皺,直覺藥方應該是對的,理由是:第一,問題主機的 Office 版本同樣是 2019+,與網路文章的狀況吻合;二是若原因不同,Registry 有一條吻合不合理?
依據Hanlon's Razor 漢隆剃刀原理 - 事情若有簡單解釋,先別把它想複雜了。我優先想的:該不會是 Registry 沒設好或設錯?
苦主覺得不可能:他就是怕打錯字,設定直接從網頁複製貼上的,不應該有錯。但依我的習慣,沒有不在場證明前,誰都別想走。Registry 有沒有設好,實際檢查便知,眼見為憑最準。
開啟 regedit 檢查後答案揭曉,三條設定果真只有 ShownFirstRunOptin 設成功,其餘兩個只開了 Registration 跟 firstrun,沒新增 DWORD 值,如此為何下載安裝更新消失但問題依舊便有了合理解釋。
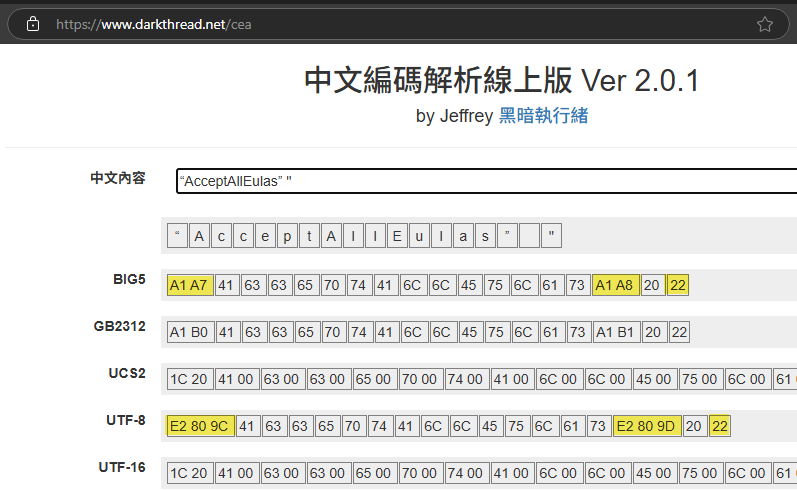
至於為什麼三條只有一條生效,問題就在 .reg 檔,逐字比對用力檢查,很快找到兇手 - AcceptAllEulas 及 BootedRTM 的雙引號被換成 「“」、「”」,推測是 Outlook/Word 智慧引號幹的好事(強烈建議大家關掉它),而在網頁上由於字體的關係,“ 跟 " 頗像,不仔細看很容易忽略。
把文字貼到中文編碼解析工具,妖孽頓時現形。
將引號校正為「"」後重新執行,問題排除。至於為什麼文章的寫法有誤,網友們卻能成功,猜想大家都用 regedit 手動找位置新增值,故不受引號影響。
全案偵結。
心得整理:
- 沒取得不在場證明前,每個都是嫌犯,隨便放人,你可能一輩子破不了案。
- 射茶包時謹記「剃刀原理」:先朝「耍笨」方向查,常有驚喜。(上回有此感慨是九年前)
- 沒看到證據都不算數,什麼都有可能,誰都不能相信。(我辦案有句機車名言:你願意用生命擔保問題不是出在這裡面?XD)
- 別人成功你失敗,有可能是用的方法不同 (開 regedit vs 跑 .reg),留意此一差異將左右偵辦方向。
- 智慧引號真的很雷,請大家關掉它。
Comments
# by Python路過吾好錯過
import tkinter as tk from tkinter import ttk def convert_text(): # 獲取輸入文本 text = entry.get() # 定義編碼格式處理規則 encodings = { 'BIG5': 'big5', 'GB2312': 'gb2312', 'UTF-8': 'utf-8', 'UTF-16': 'utf-16-le', # 小端格式不帶BOM 'UCS2': 'utf-16-le' # 與UTF-16使用相同小端格式 # UTF-16和UCS2的顯示格式為小端字節序(低位字節在前),這與Windows系統常用的表示方式一致。 # 對於包含BOM(字節順序標記)的情況,可以自行修改編碼參數為'utf-16'來自動添加BOM。 } # 清空舊結果 for txt in text_widgets.values(): txt.config(state='normal') txt.delete(1.0, tk.END) # 處理每種編碼格式 for name, encoding in encodings.items(): try: # 轉換字節數據 bytes_data = text.encode(encoding, errors='replace') # 生成十六進制字符串 hex_str = ' '.join(f"{b:02X}" for b in bytes_data) # UCS2需要每兩個字節交換位置(大小端轉換) if name in ['UTF-16', 'UCS2']: hex_pairs = [hex_str[i:i+2] for i in range(0, len(hex_str), 2)] hex_str = ' '.join(f"{p[2:4]} {p[0:2]}" if len(p) == 4 else p for p in hex_pairs) # 更新結果到文本框 text_widgets[name].insert(tk.END, hex_str) text_widgets[name].config(state='disabled') except Exception as e: text_widgets[name].insert(tk.END, f"錯誤: {str(e)}") text_widgets[name].config(state='disabled') # 創建主窗口 root = tk.Tk() root.title("編碼解析工具") root.geometry("800x600") # 輸入區域 input_frame = ttk.Frame(root) input_frame.pack(pady=10, padx=10, fill=tk.X) entry = ttk.Entry(input_frame, width=60) entry.pack(side=tk.LEFT, padx=5) ttk.Button(input_frame, text="轉換", command=convert_text).pack(side=tk.LEFT) # 結果顯示區域 result_frame = ttk.Frame(root) result_frame.pack(padx=10, pady=5, fill=tk.BOTH, expand=True) # 創建帶滾動條的文本框 text_widgets = {} encodings = ['BIG5', 'GB2312', 'UTF-8', 'UTF-16', 'UCS2'] for idx, encoding in enumerate(encodings): row = ttk.Frame(result_frame) row.pack(fill=tk.X, pady=2) ttk.Label(row, text=encoding, width=10).pack(side=tk.LEFT) text = tk.Text(row, height=2, width=70, wrap=tk.NONE) text.pack(side=tk.LEFT, fill=tk.X, expand=True) text.config(state='disabled') # 添加水平滾動條 scroll = ttk.Scrollbar(row, orient=tk.HORIZONTAL, command=text.xview) scroll.pack(side=tk.BOTTOM, fill=tk.X) text.config(xscrollcommand=scroll.set) text_widgets[encoding] = text # 綁定回車鍵事件 entry.bind('<Return>', lambda event: convert_text()) root.mainloop()
# by Ike
為什麼會經過「Outlook/Word 智慧引號」?
# by Jeffrey
to lke, 我遇過蠻多次的,作者使用 Word/Outlook/PowerPoint 撰寫文件時符號被換掉,之後複製轉貼被污染過的版本。