數大便不美
 |  | 6 |  |  |
奈米(nanometer)科技最有趣的一點在於當物質的粒子小到一定程度時,物質的特性會迥異於原本巨觀尺度下的物理、化學及生物特性。以無人不愛的黃金為例,當它被製成金奈米粒子(nanoparticle)時,顏色不再是金黃色而呈紅色,說明了光學性質因尺度的不同而有所變化。又如石墨因質地柔軟而被用來製作鉛筆筆芯,但同樣由碳元素構成、結構相似的碳奈米管,強度竟然遠高於不銹鋼,又具有良好的彈性,因此成為顯微探針及微電極的絕佳材料。
from http://nano.nchc.org.tw/aboutnano.php
同樣的,當資料庫大到一定程度時,許多操作特性也變得與一般"常識"完全不同,這讓平時用慣小資料庫的我大吃一驚。
最近建置了一個財務歷史資料的大型資料庫,資料來源是數萬個XML,壓縮成ZIP的大小超過1G,光解壓縮就要花上15分鐘,匯入資料庫則要花上4小時(其中有1.5個小時是在建Index),最後搞出一個超過11G的超大資料庫。
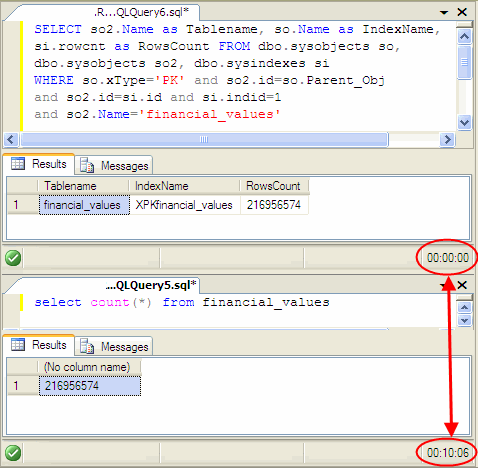
好奇想看一下總共有幾筆資料,小學生也知道用SELECT COUNT(*)查一下立見分曉,卻沒想到這個小小的查詢竟花了我十分鐘,只為了看一個數字---216,956,574(2.1億筆耶~~~ 樂透彩一期也沒這麼多注吧?)。幸好是在開發環境,若是在正式環境,這番惡搞肯定會拖垮SQL的效能,輕則挨頓臭罵,若是影響到一分鐘幾十萬上下的營運系統,搞不好連飯碗都要丟了。
嚴肅的結論是: 在正式環境中,不要隨便褻玩這種超大型的資料庫。但一個好玩的議題是,資料存在SQL Server中,SQL豈有不知Table資料筆數的道理,應該有其他更有效率的方法查資料筆數吧? 憶起當年追隨SQL大師Ryan時,他曾露了一手由PK筆數查總筆數的方法,查詢語法如下:
dbo.sysobjects.name as 'Object Name',
dbo.sysindexes.rowcnt as 'Row Count',
dbo.sysindexes.name as 'Index Name'
FROM dbo.sysobjects INNER JOIN dbo.sysindexes
ON dbo.sysobjects.id = dbo.sysindexes.id
and dbo.sysobjects.name='financial_values' --Change the Table name here
and dbo.sysindexes.indid=1 --(1:for clustered index, 0:for non-clustered index)
實測結果,由PK Index筆數去查總筆數,零秒就有答案,這算是加速了無限大倍嗎? XD
Comments
# by steve
大師 divided by zero 會有error喔.....:P 我曾經幹過類似的事 用QueryAnalyzer給他連續select count(*) 10次 那還是只有1千萬筆 結果居然總共出現了3種結果 那是測試環境,應該是沒有人在用 大師有沒有興趣實驗看看?
# by platstar
有一點不明白,為什麼不是用 select count(PK) from financial_values 效率也是差很多
# by Jeffrey
我認為select count(PK) 跟 select(*) 的速度差別不大。理由是SQL只算筆數,並不涉及處理欄位內容,而且還有一點是PK是由五個欄位組成的,所以沒得select count(PK)。 不過我自己也好奇,還是用select count(col1)只選單一欄位跟select count(*)再比一次,結果是6'50" vs 6'50",完全相同。至於比上次10'06"快,我認為可能是對HD做過Defragment的關係。
# by tai
那請問如果要搜尋符合的條件的資料筆數有無比較快的方法
# by Jeffrey
有WHERE條件時,除了請SQL直的去逐一比對外,應該沒有什麼捷徑可抄。不過,經驗證明,當Table很大時,加對Index,Query速度有可能差上數百倍。 我的建議是,下WHERE條件時儘可能配合現有的Index,或是反過來建立一些Index配合常用的複雜Query,應該是改善查詢速度的有效途徑。
# by tai
其實該做的 Index 都作了 速度還是快不起來 20 幾萬筆 看來如果硬體升級後還是如此 那要考慮適度反正規化了...