程式整合 Azure 文字轉語音服務 - PowerShell / C# 範例
 |  | 2 |  |
上回試玩了 Azure AI 照片分析有些意猶未盡,繼續試試文字轉語音。
文字轉語音(Text-To-Speech, TTS)的功能很早就有了,Windows 從早期版本便已內建 SAPI (Speech API),也有 Balabolka 之類的免費軟體能將中文文字轉成語音,但當年技術還不夠成熟,語音的機械感超重,難登大雅之堂。(想體驗古早味的朋友,我找到一段 YouTube 影片示範)
這幾年人工智慧正夯,它也被應用在合成語音上,神經網路模型(Neural Nework-Based TTS Model)加入後,合成語音品質有了驚人提升(微軟在 2019 年也推出 FastSpeech讓速度跟品質再邁進一大步),時至今日,文字轉語音的流暢與自然程度幾可亂真。而在你抖音、FB 看到的一堆電影解說影片,幾乎清一色都已是用 AI 配音,甚至已經有現成軟體讓你不費吹灰之力搞定。
沒聽過微軟版本的 AI 等級電腦語音品質?其實它近在眼前,在 Edge 瀏覽器按 Ctrl-Shift-U 開啟大聲朗讀,語音選項選 HsiaoChen(曉臻)、YunJhe(雲哲) 或 HsiaoYu(曉雨) 這三個台灣版神經網路語音,Edge 便會用近似真人的語調及聲音為你朗讀網頁內容:
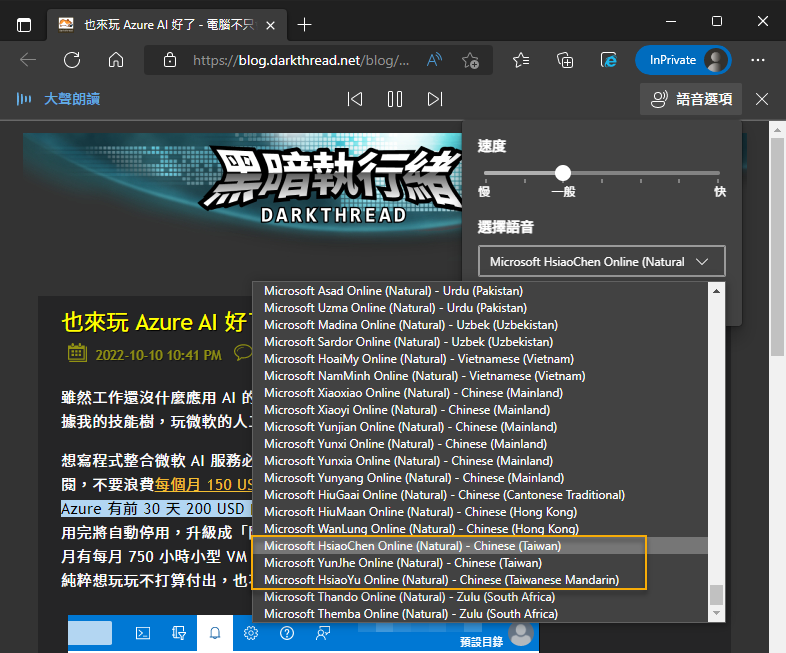
另外 ,Azure 網站有個文字轉換語音線上測試網頁版,則可輸入任意文字用「類神經網路」優化過的合成語音唸出來。要寫程式,這個網頁也是學習及測試 SSML 的好地方:
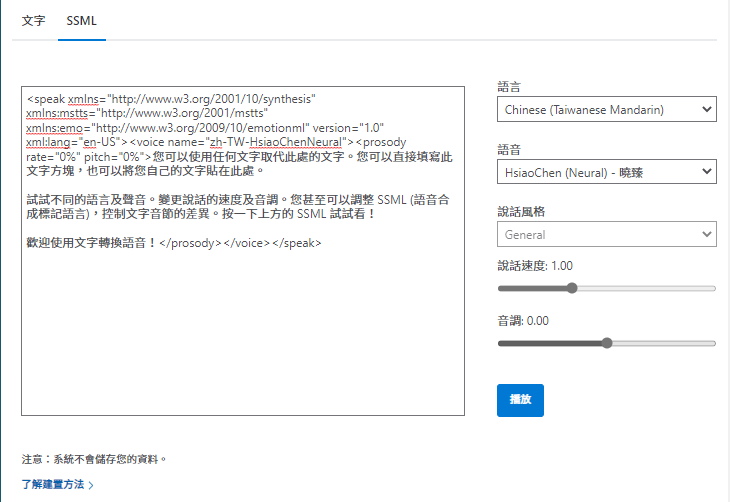
台灣版神經網路語音共有 zh-TW-HsiaoChenNeural (曉臻 女聲)、zh-TW-HsiaoYuNeural (曉雨 女聲)、zh-TW-YunJheNeural (雲哲 男聲) 三種,我自己實測的感覺,曉臻在預設語速 1.0 聽起來就很自然,其餘二者偏慢,曉雨語速調提高到 1.2 雲哲 1.1 會好一些。
補充:所有可用語音清單:Language and voice support for the Speech service
至於 TTS 費用是以字元計費,F0 有每月 50 萬個字的免費額度、S0 (隨用隨付) 為每一百萬個字元 16 美元,超過 10 分鐘的長音訊(Long Audio Creation) 則是每一百萬字元 100 美元。 收費參考
要寫 TTS 程式,官網的快速上手文件是不錯的入門教材,文件還提供了 C#、C++、Go、Java、JavaScript、Objective-C、Python、Swift、CLI、直接呼叫 REST 等多種程式語言範例。另外,推薦 Github 範例專案 - Sample Repository for the Microsoft Cognitive Services Speech SDK,有個完整的功能展示範例,幾乎涵蓋所有應用情境。
(註:想動手玩看看要先註冊 Azure 帳號取得認知服務金鑰,方法可參考前文)
我先試上回 AI 照片分析 Github 下載範例專案包中的 PowerShell 範例,它不需參照任何程式庫,用單純的 HTTP Request 呼叫 REST API,上傳 SSML 後可得到 MP3 檔。依循相同原理,這段程式可以輕易翻寫成其他語言或平台。PowerShell 播放 MP3 部分我借用 .NET Framework PresentationCore.dll 的 MediaPlayer ,播放過程還有加上進度條效果,完整程式範例如下:(實測請看文末影片)
$key = "02***c2"
$region = "southeastasia" # 需填對認知服務帳號的地區,否則無法存取
function shuffle($array) {
$array | Sort-Object { Get-Random }
}
$times = ('上午九點', '下午兩點', '下午五點', '晚上八點')
$people = shuffle ("阿基師", "會計師", "健身教練", "五月天")
$places = shuffle ("菜市場", "總公司", "河濱公園", "KTV")
$actions = shuffle ("買苦瓜", "查帳", "拉單槓", "唱歌")
$schItems = (0..3) | ForEach-Object {
$times[$_] + "跟" + $people[$_] + "去" + $places[$_] + $actions[$_]
}
$text = "您今天有$($schItems.Length)個行程,$($schItems -join '、')"
# Code to call Text to Speech API
$sml = @"
<speak xmlns="http://www.w3.org/2001/10/synthesis" version="1.0" xml:lang="en-US">
<voice name="zh-TW-HsiaoChenNeural">
<prosody rate="0%" pitch="0%">
$text
</prosody>
</voice>
</speak>
"@
$headers = @{}
$headers.Add( "Ocp-Apim-Subscription-Key", $key )
$headers.Add( "Content-Type", "application/ssml+xml; charset=utf-8" )
$headers.Add( "X-Microsoft-OutputFormat", "audio-16khz-128kbitrate-mono-mp3" )
$outputFile = [System.IO.Path]::GetTempFileName() + ".mp3"
$smlData = [System.Text.Encoding]::UTF8.GetBytes($sml)
$result = Invoke-RestMethod -Method Post `
-Uri "https://$region.tts.speech.microsoft.com/cognitiveservices/v1" `
-Headers $headers `
-Body $smlData `
-OutFile $outputFile
# 播放 mp3 檔案
Add-Type -AssemblyName PresentationCore
# 參考:https://github.com/fleschutz/PowerShell/blob/master/Scripts/play-mp3.ps1
$mp = New-Object System.Windows.Media.MediaPlayer
do {
$mp.Open($outputFile)
$ms = $mp.NaturalDuration.TimeSpan.TotalMilliseconds
} until ($ms)
$totalSecs = [Math]::Round($ms / 1000)
$mp.Play()
$delta = 0.2;
# 顯示播放進度
for ($secs = 0; $secs -lt $totalSecs; $secs += $delta) {
Start-Sleep -Milliseconds ($delta * 1000)
Write-Progress -Activity "Playing audio" `
-Status ("{0,3:n1} s / {1:n0} s " -f $secs, $totalSecs) `
-PercentComplete ($secs / $totalSecs * 100)
}
Write-Progress -Activity "Playing audio" -Completed
$mp.Stop()
$mp.Close()
測完 PowerShell,我決定再試試 C#。C# 的話有程式庫可用,呼叫方式比較簡單,但我不幸遇到 KB5018410 安全更新攪局,跟 USP error: timeout waiting for the first audio chunk 及 HttpAPI failed - Failed with error: HTTPAPI_OPEN_REQUEST_FAILED [0x3] 錯誤周旋了好久才發現程式沒寫錯,是自己帶賽,大家如遇到同樣問題,Workaround 是先解除安裝更新,待未來有修補檔或程式庫換版再重新安裝。
用 CLI 建立 .NET 6 Console 專案,加入 Microsoft.CognitiveServices.Speech 程式庫參照:
dotnet new console -o tts-demo
cd tts-demo
dotnet add package Microsoft.CognitiveServices.Speech
照著教學文件的 C# 範例,我試寫了一段測試程式,藉由 SDK 包裝,程式碼簡單清晰不少,並內建支援喇叭播放,不用自己找播放元件。
using Microsoft.CognitiveServices.Speech;
var key = "02***c2";
var region = "southeastasia";
var times = new[] { "上午九點", "下午兩點", "下午五點", "晚上八點" };
var people = shuffle("阿基師,會計師,健身教練,五月天".Split(','));
var places = shuffle("菜市場,總公司,河濱公園,KTV".Split(','));
var actions = shuffle("買苦瓜,查帳,拉單槓,唱歌".Split(','));
var text = $"您今天有{times.Length}個行程,";
for (var i = 0; i < times.Length; i++)
{
text += $"{times[i]}跟{people[i]}去{places[i]}{actions[i]},";
}
var speechConfig = SpeechConfig.FromSubscription(key, region);
speechConfig.SpeechSynthesisVoiceName = "zh-TW-HsiaoChenNeural";
using (var speechSynthesizer = new SpeechSynthesizer(speechConfig))
{
var result = speechSynthesizer.SpeakTextAsync(text).Result;
switch (result.Reason)
{
case ResultReason.SynthesizingAudioCompleted:
Console.WriteLine("Speech synthesized to speaker for text [{0}]", text);
break;
case ResultReason.Canceled:
var cancellation = SpeechSynthesisCancellationDetails.FromResult(result);
Console.WriteLine("CANCELED: Reason={0}", cancellation.Reason);
if (cancellation.Reason == CancellationReason.Error)
{
Console.WriteLine("CANCELED: ErrorCode={0}", cancellation.ErrorCode);
Console.WriteLine("CANCELED: ErrorDetails=[{0}]", cancellation.ErrorDetails);
}
break;
}
}
string[] shuffle(IEnumerable<string> array)
{
var rnd = new Random();
return array.OrderBy(o => rnd.Next()).ToArray();
}
傳內容字串給 SpeakTextAsync() 便會直接轉成語音播放,很方便。
若要下載語音檔內容,做法是建立 SpeechSynthesizer 時 AudioConfig 參數傳 null,再由 SpeechSynthesisResult 取得 AudioDataStream,傳存 .wav 檔或不落地讀入 byte[] 處理:
using (var speechSynthesizer = new SpeechSynthesizer(speechConfig, null as AudioConfig))
{
var result = speechSynthesizer.SpeakTextAsync(text).Result;
switch (result.Reason)
{
case ResultReason.SynthesizingAudioCompleted:
using (var audioDataStream = AudioDataStream.FromResult(result))
{
await audioDataStream.SaveToWaveFileAsync("output.wav");
// 或是可以轉為 byte[] 全程不落地
/*
audioDataStream.SetPosition(0);
byte[] buffer = new byte[16000];
uint totalSize = 0;
uint filledSize = 0;
while ((filledSize = audioDataStream.ReadData(buffer)) > 0)
{
Console.WriteLine($"{filledSize} bytes received.");
totalSize += filledSize;
}
*/
}
Console.WriteLine("Done!");
break;
case ResultReason.Canceled:
var cancellation = SpeechSynthesisCancellationDetails.FromResult(result);
Console.WriteLine("CANCELED: Reason={0}", cancellation.Reason);
if (cancellation.Reason == CancellationReason.Error)
{
Console.WriteLine("CANCELED: ErrorCode={0}", cancellation.ErrorCode);
Console.WriteLine("CANCELED: ErrorDetails=[{0}]", cancellation.ErrorDetails);
}
break;
}
}
Exmaple of using PowerShell and C# to integrate Azure TTS service to convert text to voice.
Comments
# by 小熊子
為什麼是跟阿基師拉單槓? 為什麼五月天是去查帳而不是去ktv唱歌?
# by Jeffrey
to 小熊子,測試過程,還有一次是健身教練跑去KTV吵著要查帳,結果差點跟圍事打起來