GUID 叢集索引測試 1 - 偶發寫入逾時之三千萬筆實測
 |  | 0 |  |  |
我們都知道,資料庫使用 GUID 作為叢集索引易造成索引碎片化影響效能。若要用 GUID 作為 Primary Key,應另設自動跳號數字欄位當叢集索引。(註:不熟悉此議題的同學可先看這篇:GUID Primary Key 資料庫避雷守則)
近期在古蹟專案遇到偶發 INSERT 逾時錯誤(SqlCommand 執行時間上限預設 30 秒),由於該系統使用 SQL Uniqueueidentity (GUID) 欄位當 Primary Key 兼叢集索引,資料表又屬千萬筆等級,令人懷疑與 GUID 叢集索引有關,於是我想在實驗室環境模擬,觀察 GUID 叢集索引造成 INSERT 逾時的機率。
測試環境為 SQL 2022,8 核 CPU,32G RAM,磁碟讀寫速度約 170MB/s。用以下 SQL 指令建立兩個以 GUID 當 Primary Key 的資料表,其中 GuidClustIdx 直接使用 Guid 型別當叢集索引,IntClustIdx 則另設了 BIGINT 型別自動跳號當叢集索引。
CREATE TABLE [dbo].[GuidClustIdx](
[PK] [uniqueidentifier] NOT NULL,
[LongText] [nvarchar](max) NOT NULL,
CONSTRAINT [PK_GuidClustIdx] PRIMARY KEY CLUSTERED
(
[PK] ASC
)
)
GO
CREATE TABLE [dbo].[IntClustIdx](
[SN] [bigint] IDENTITY(1,1) NOT NULL,
[PK] [uniqueidentifier] NOT NULL,
[LongText] [nvarchar](max) NOT NULL,
CONSTRAINT [PK_IntClustIdx] PRIMARY KEY NONCLUSTERED
(
[PK] ASC
),
CONSTRAINT [IX_IntClustIdx] UNIQUE CLUSTERED
(
[SN] ASC
)
)
GO
SQL 伺服器設定簡單復原模式,資料庫檔案預先放大到 320GB,避免寫入過程序自動擴充干擾實驗。我寫了以下程式,可對 GuidClustIdx 或 IntClustIdx INSERT 指定筆數資料,NVARCHAR 欄位寫入 1000 個字元長度,過程記錄每次 INSERT 耗時,每 50 筆記錄切一次檔案。每次測試完用昨天分享的程式解析 Log 檔並繪成圖表。
using Microsoft.Data.SqlClient;
public class SqlRunner
{
const string cs = "data source=.;initial catalog=FragPerfTest;integrated security=True;encrypt=false";
public enum TableNameEnum {
GuidClustIdx,
IntClustIdx
}
public static void InsertData(TableNameEnum tableName, long rowCount)
{
using var cn = new SqlConnection(cs);
cn.Open();
using var cmd = new SqlCommand($"INSERT INTO {tableName} (PK, LongText) VALUES (@pk, @text)", cn);
cmd.CommandTimeout = 300;
var pPK = cmd.Parameters.Add("@pk", System.Data.SqlDbType.UniqueIdentifier);
var pText = cmd.Parameters.Add("@text", System.Data.SqlDbType.NVarChar, -1);
pText.Value = new string('x', 1000);
var sw = new System.Diagnostics.Stopwatch();
Directory.CreateDirectory("logs");
Func<string> getFileName = () => $"logs\\Test-{DateTime.Now:MMdd-HHmmss}.txt";
StreamWriter logger = new StreamWriter(getFileName());
for (var i = 0; i < rowCount; i++)
{
pPK.Value = Guid.NewGuid();
sw.Restart();
cmd.ExecuteNonQuery();
sw.Stop();
if (i % 100 == 0) Console.WriteLine($"{i:n0} Rows Inserted");
if (i % 500_000 == 0)
{
logger.Flush();
logger.Dispose();
logger = new StreamWriter(getFileName());
}
logger.WriteLine($"{i + 1}: {sw.ElapsedMilliseconds}ms");
}
logger.Flush();
logger.Dispose();
}
}
我反覆測了幾次,同樣 INSERT 1000 萬筆,用 GUID 當叢集索引速度慢了一倍,需花約兩個小時,BIGINT 叢集索引則是一個小時出頭做完。若每 100 筆統計一次,繪製平均 INSERT 時間(藍線)、最大時間(紅點)、99 百分位數時間(綠點)圖表如下:

如上圖所示,GUID 雖然平均時間較慢(不時會到 40ms),偶爾會有 2 秒以上的最大值,最糟到 4 秒多;INT 的平均值不超過 20ms,最大值也都在一秒以內,極值約 1.5 秒。但值得注意的是綠色部分,99 百分位數代表有 99% 的 INSERT 都低於這個時間,由於是以 100 筆統計,可視為其中第二慢的時間。GUID 的 99 百分位數值約 3ms,可解讀為 100 筆只有一筆特別高,其他 99 筆都在 3ms 以下。由此推測,GUID 叢集索引雖然效率較差,但與自動跳號叢集索引的差異並不懸殊,且在本實驗未重現 30 秒逾時這類嚴重狀況。
繼續測試寫入到 2000 萬筆及 3000 萬筆:
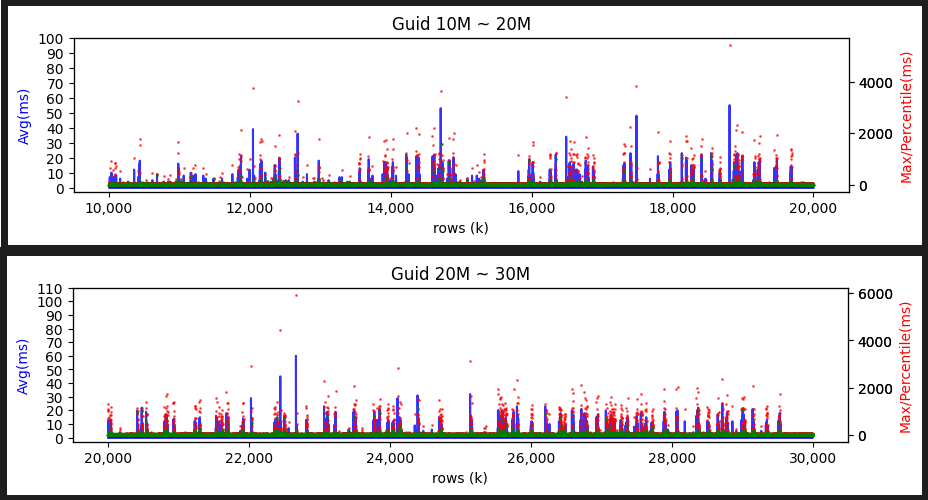
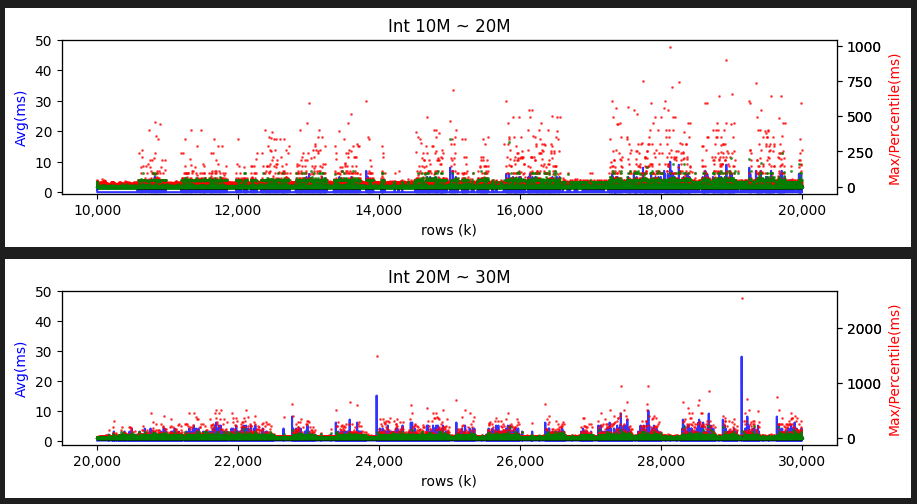
INT 表現穩定,GUID 也維持平均不超過 50ms,99% 低於 10ms,偶發最大值超過 4 秒的水準,時間並未隨著筆數增加拉長。
由以上測試結果,在無其他查詢干擾的單純 INSERT 實驗裡,GUID 雖會造成 INSERT 變慢,100 筆裡可能有一兩筆時間長達 4-6 秒,但不足以直接引發超過 30 秒的逾時錯誤,且偏慢狀況也沒有隨筆數增加出現等比例或雪崩式惡化(因為 B+ Tree 是 O(log n)?) 。但在負載高於硬體效能水準的情境(Disk IO 消化不及應是主因),偶發的偏慢可能被放大 N 倍,超過 30 秒並非不可能。
結論:用 GUID 當叢集索引,雖然偏慢,但並不如想像會在筆數上升後出現崩盤式的惡化。在實驗室環境控制變因測試下,99% INSERT 都能在正常時間內完成,但會偶發慢達數秒的異常速度。若遇到伺服器硬體效能無法勝任負載時(Disk Time 100%、Disk Queue 過長),偶發偏慢到數秒的 INSERT,惡化到超過 30 秒的機率是會比使用循序叢集索引來得高。
This article verifies whether there are serious performance issues with tables using Guid Clustered Index by empirically testing the insertion of 30 million pieces of data.
Comments
Be the first to post a comment