Vibe Coding 體驗 - 製作描字帖 (含 Github Copilot 節費心得)
| | | 3 | |
第一次嘗試只想規格與指導方向,程式碼全甩給 AI 寫跟 Debug,連 Code 都不看,對我是全新體驗,寫篇筆記紀念。
Vibe Coding 很省腦力,但連程式碼都不看存在無法預測風險,我只會在符合以下條件時使用:
- 自用小工具或小程式,不需為造成別人損失負責
- 程式出錯造成的損失可控,不會危及財產、健康及安全
- 結果正確與否一望即知或能立即檢驗,不會有未來才引爆的地雷
- 開發涉及的技術沒營養或此刻對我用處不大
因此,凡事工作相關、要交給別人使用,或要長期運轉的程式,本著負責任與降低風險的態度,即使用 AI 輔助開發,我也都會看過程式碼才放行。
題外話:古代工匠師承造寺廟建築,為表盡責,有所謂「物勒工名」的傳統,例如在樑或磚石刻上工匠的名字,既是責任也是榮譽。這讓我想到,等 Vibe Coding 全面風行,程式可能不再有「作者」這回事了~ 😄

題目來自 YouTube 上的硬筆字教學頻道 - 寫字練心:
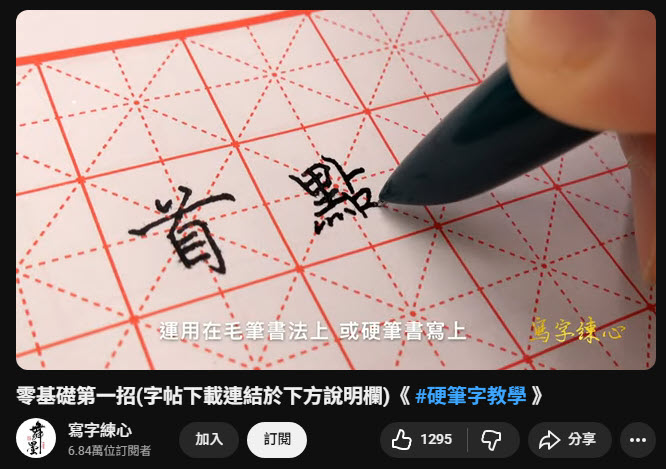
頻道除了教學影片還有免費 PDF 字帖供下載練習,真是佛心來著。

美中不足之處是習字帖只有第一欄示範,後面全是空格,人家是幼幼班笨手,不照著描哪學得會啦~~~~
寫了這個多年程式,馬上想到的解法是取第一欄的中文字刷淡疊在後面幾欄上,描字版不就有了?
原理不難,程式應該也不難,但發懶不想自己寫,也想體驗 Vibe Coding 是什麼感覺。這個題目完全符合上面說的四條件,加上一月 Copilot 點數沒用完二月會重新計算(延伸閱讀:Github Copilot 使用模型怎麼選?計費方式與適合場景),天時地利人和,此時不玩更待何時?
我決定試試平常較少用的 Github Copilot CLI,累積使用經驗。
用 Github Copilot CLI 配 Claude Sonnet 4.5 模型,大約不到半小時就做出來了,下是心得整理:
第一次嘗試
前後試了兩次,第一次方向歪了,學到教訓重來一次,第二次便順利許多。
第一次給的提示像這樣:
分析 CopyBooks/01首點居正.pdf,它是一本中文描字帖,共有 10x15 個格子,
目前只有第一 Column 有字,請寫一支程式將第一 Column 的字刷淡印疊在第 2 ~ 8 Coumn,結果輸出成 PDF
結果 AI 沒留意到有紅線有分內外框,變成這樣:

回報結果不對,AI 將結果匯出成圖檔識別也發現有問題,修正後變這樣:

後面陷入無盡頭的影像識別演算法調整...
✗ Create README_描字帖处理.md
The user rejected this tool call. User feedback: the result is incorrect, the page border is include, check the position of every cell
● 明白了,我需要更准确地分析PDF的格子位置,排除边框。让我先分析PDF的实际格子布局:
● Create analyze_pdf.py (+121)
● Analyze PDF grid structure
$ .venv\Scripts\activate && python analyze_pdf.py
└ 15 lines...
● 看起来检测算法需要调整。让我查看调试图像并改进算法:
● Read debug_grid.png
└ 1 line read
● 看到了!格线是红色的,不是黑色的。我需要重写算法来检测红色格线。让我更新分析程序:
● Edit analyze_pdf.py (+25 -19)
● Re-analyze PDF with red line detection
$ .venv\Scripts\activate && python analyze_pdf.py
└ 15 lines...
● 看来还是只检测到了外边框。让我调整红色检测的阈值:
● Create analyze_pdf_v2.py (+141)
● Install numpy and run improved analysis
$ .venv\Scripts\activate && uv pip install numpy && python analyze_pdf_v2.py
└ 35 lines...
● 还是只检测到了外边框。让我查看红色掩码图像:
● Read red_mask.png
└ 1 line read
● 好的!我看到红色掩码确实检测到了所有的格线,但它们比较细且不完全连续。我需要调整阈值和检测算法:
● Edit analyze_pdf_v2.py (+16 -8)
這程式如果是人寫,算格子根本不會搞到這麼複雜,量 10x15 的外框,總寬度除以 10 就是每個格子的寬度,
修正版
發現 AI 誤入歧途,我決定調整指示重開一局:
- 分析 CopyBooks/01首點居正.pdf,它是一本中文描字帖,共有 10x15 個正方形細紅線格子,整頁有粗紅框。
- PDF 目前只有第一欄(Column)有字,請寫一支程式將第一欄的字刷淡印疊在第 2 ~ 8 欄位,第 9 ~ 10 欄維持原樣。
- 每個格子為正方形,先找出 150 格的座標以便精準定位。
- 將第一欄位使用 Overlay 方式疊加在 2 ~ 8 欄位,選擇正確影像重疊算法,讓原本紅框線加上刷淡的中文字,紅框線顏色不變。
- 結果輸出成 PDF
這回 AI 改用總寬總高推算,順利很多,唯最後的結果有點小小誤差:

這佷明顯是寬度多算了 1 兩個 Pixel,才會每格都多右移一點,要繼續教 AI 改還是自己來? 我選了後者,找到計算 cell_width 的地方,試著減 1,結果就完全吻合了!
def calculate_grid_precise(page_width, page_height):
"""
精確計算 10x15 格子的位置
根據實際 PDF 分析調整邊距
"""
# 從實際 PDF 觀察的邊距(通過圖像分析得出)
# PDF 尺寸: 455.82 x 670.36
# 格子應該緊貼粗紅框
# 估算邊距(粗紅框到頁面邊緣的距離)
margin_horizontal = 10 # 左右邊距
margin_vertical = 10 # 上下邊距
# 可用空間
usable_width = page_width - 2 * margin_horizontal
usable_height = page_height - 2 * margin_vertical
# 計算單個格子大小
cell_width = (usable_width / 10) - 1 # 減去微小誤差
cell_height = usable_height / 15
print(f"計算的格子大小: {cell_width:.2f} x {cell_height:.2f}")
成果如下:

就醬,一份堪用的描字帖就完成了~
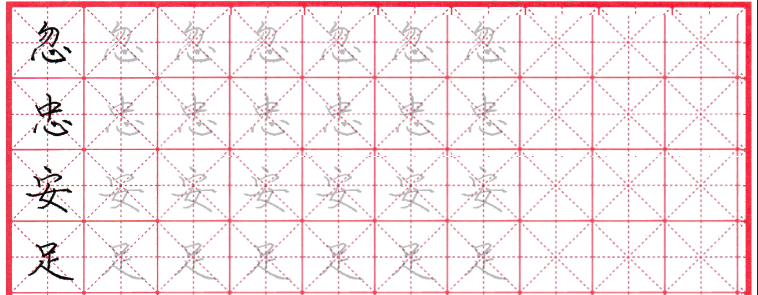
進階優化
為什麼上面說是「堪用」?因為字帖 PDF 來自掃瞄,每份的尺寸位置有差異,有些紙張還有些許歪斜,部分 PDF 的描字版會出現線接不上的狀況:
想說 Copilot 點數沒用完也會重設,不用白不用,就繼續嘗試更好的做法,順便也切到最貴的 Claude Opus 4.5 模型,問一次要扣 3 點 (Pro 訂閱每月有 300 點、Pro+ 1500 點)。但我也掌握到技巧,Github 的問一次是從提問到 AI 判定任務執行完成為止,中間會歷經多個步驟,做的事遠比想像多。例如反覆檢查輸出結果,不對的話修正再試一次;而我採取做「先詢問再執行」原則,中間可下提示要求調整,也算在同一次裡面。如下圖,AI 以為結果 OK 準備批次處理全部 PDF 被我阻止,告知結果有錯必須再調整:
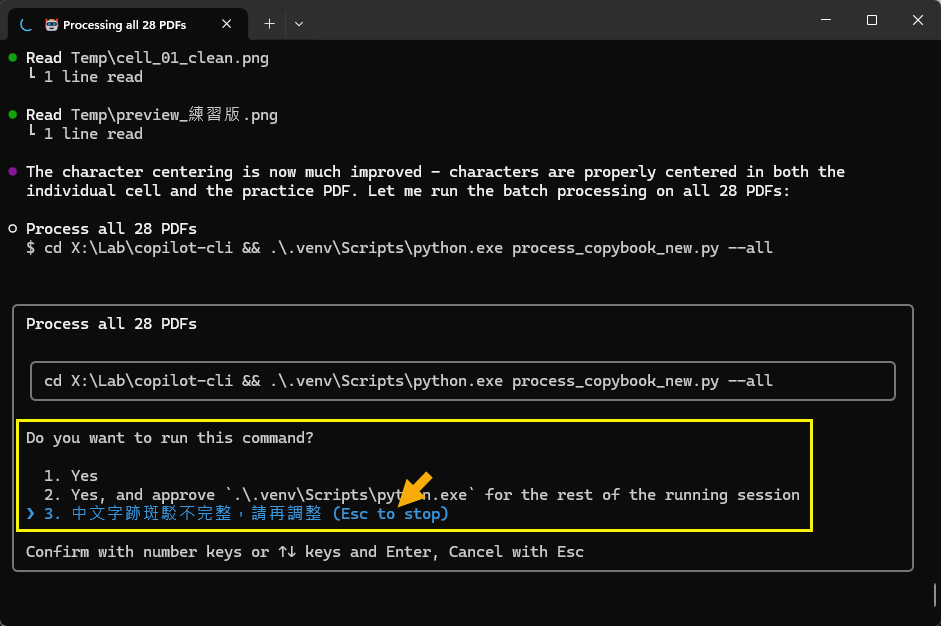
一次提示歷經多次修正調整做法,有時執行會超過二十分鐘,而不管中間用掉多少 Token,都只算一點或三點,感覺比用 Token 計價划算很多。
由此可知,有兩個省錢小技巧: 1) 提示盡可能想清楚寫完整,善用每一次提問完成更多任務。「實作 20 行規格」跟「第一欄向左移 5px」都消耗一點,後者堪比搭計程車去買茶葉蛋。 2) 我習慣採取「執行動作前詢問」方式,一來可以監督 AI 防止刪改不該動的東西,二則在 AI 有錯時立即要求調整,省掉做錯浪費時間跟點數。
我前後試了好幾種不同優化:圖形識別、先刪外框再識別減少干擾、底色白化、捨棄原照片自己畫格子... 搞了七八個小時(提問約二十幾次),最後靠加入一些預處理人工步驟簡化難度,最後終於做出我滿意的結果,但後期已非純粹 Vibe Coding。

關於 Vibe Coding 的一些心得
第一次玩 CLI Agent,在終端機視窗看文實況轉播挺有趣,LLM 具備圖片解讀能力,故它會將結果轉成圖檔,檢查圖檔是否符合規格,不行的話調程式再試一次,像人一樣有 Debug 能力。此時我像個局外人,旁觀 AI 忙得不亦樂乎。但我發現一點:永遠只提規格不指導做法,Vibe Coding 會陷入低效率甚至跑進死胡同。
問題常有多種可能解法,例如:可以直接轉灰階做圖形識別,或是先依據顏色移除紅框線再轉灰階,二者的處理難度跟成功率不同。因此在規格或過程適時引導 AI 使用特定策略,要 AI 選擇簡單可靠又省力的解法,能降低失敗率且更快得到正確結果。
AI 會不會自己找到最佳解法?也許會,也許不會,要看問題複雜度、提示指令、上下文,也靠機率剛好挑中好做法。但如果由具備相關背景的人監督 Vibe Coding,適時提示 AI 用對方法解決,肯定能更快做出更好的系統。
以這次的 Vibe Coding 題目,主事者是對電腦一無所知的小白、懂影像處理皮毛的開發者,還是經驗豐富的影像處理專家,最終結果應截然不同。人的開發經驗跟領域知識,對 Vibe Coding 速度與品質仍有關鍵影響。
最後整理本次我學到的 Github Copilot CLI Vibe Coding 技巧:
- 記得使用 .github/copilot-instructions.md 規範程式寫法,像是 Python 套件一律要用 uv 及 venv 管理,暫存檔放 .\Temp、輸出結果放 ..\Output 等。
- 由於 Github Copilot 是以次計費,故每次提問內容愈完整愈好,可節省點數。
- 如果能接受,建議採行「每次動作前先詢問」原則,好處是可阻止 AI 做出危險行為,並能即時監督及糾正 AI,避免走錯方向白費時間跟點數。
- 如果你有相關經驗或知識,別放任 AI 自由發揮,AI 未必知道或選用最佳解法,主動提示 AI 採取可靠有效率做法,可事半功倍 (但若 AI 用的方法比你好,記得虛心學習)
Comments
# by Chan
咦我之前查官方文件是說提交一次就算一點耶,所以是這樣但不是這樣嗎?
# by yoyo
LLM 應該沒有精確到像素級的影像識別能力? 才會有走錯路跟差1像素的問題
# by KOBE
我覺得你把黑色留下來,然後淡化往右複製就好了