無獨顯 i5 也能順跑的迷你語言模型 - Gemma 2 2B 體驗
| | | 0 | |
之前試玩過台灣在地版 13B LLaMA 2 地端模型,我這台沒有獨顯立顯卡的迷你工作機,12 代 i5 CPU 跑起來大約一秒一個字,效能勉強可接受。
Google 在 7 月底釋出了開源模型 Gemma 2 的最迷你版本,參數量只有 2B,號稱在 LMSYS 聊天機器人競技場表現亮眼,打敗 GPT-3.5。
2B 參數只佔 2GB 多記憶體,不需刻意量化瘦身就能在顯存有限或純 CPU 環境跑,聽來很有吸引力,我決定試玩一下。
我選擇先用 Ollama 跑,看看速度如何,不夠力再試 Ollama.cpp。
從 Ollama 官網下載 OllamaSetup.exe:
下一步下一步無腦裝完:
說明:先前測試時誤輸參數,使用 Gemma 模型測試,效果不甚理想。Gemma 2 2B 表現有好一點點,已補上對照。
開 CMD,輸入 ollama run gemma:2b 等 Ollama 下載啟動模型,幾分鐘後便可開始跟 Gemma 2B 聊天,而 Gemma 2B 耗用記憶體約 2.4G:
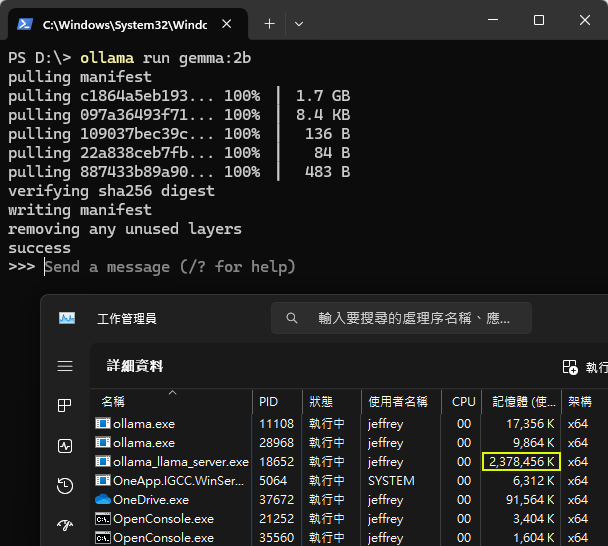
隨手胡亂測試,速度讓人驚豔,但正確性不如預期,可能因為 2B 參數有限,知識量不能與 ChatGPT 這類 175B 大模型相提並論,尤其是中文方面差距更大:
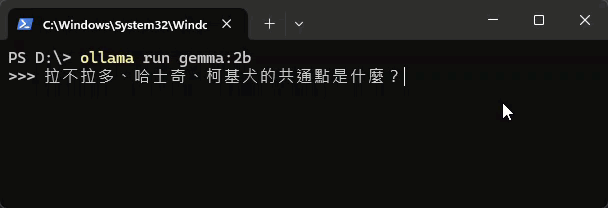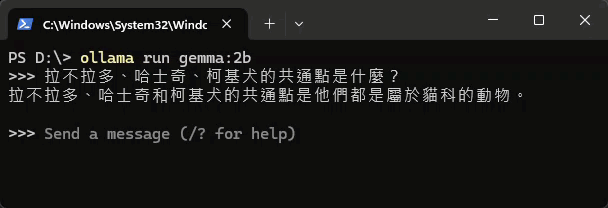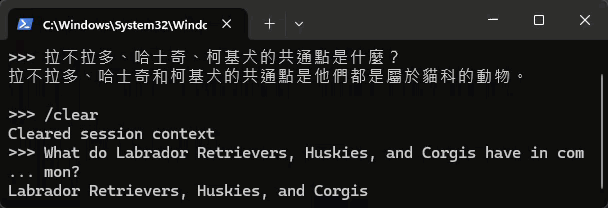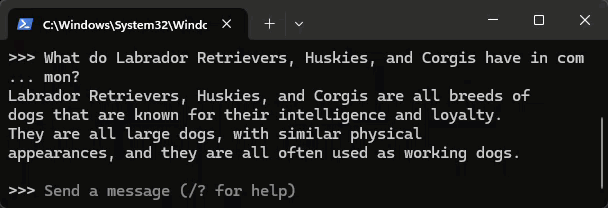
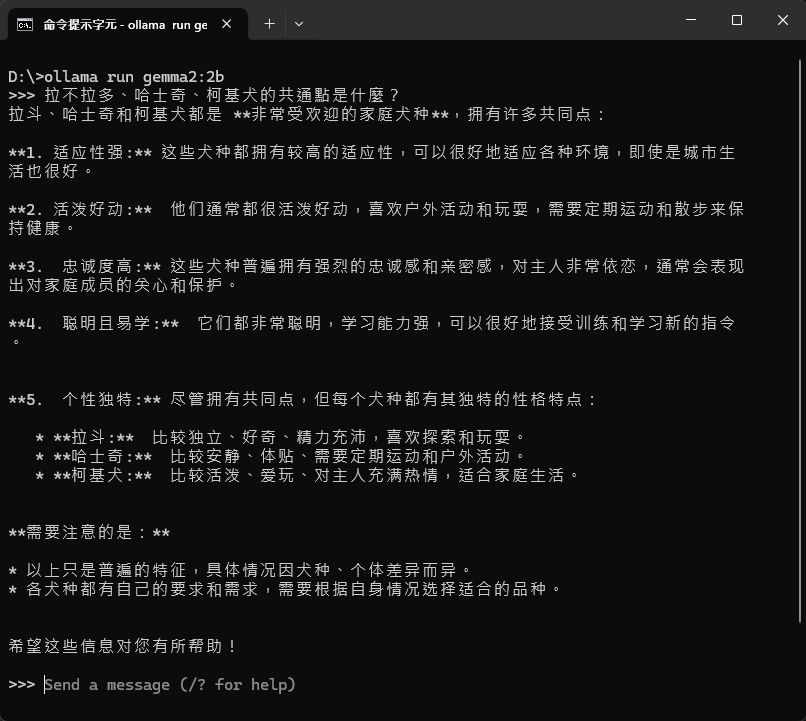
另使用 ollama run gemma2:2b 測試 Gemma 2 2B,佔用記憶體約 3G,回答品質感覺好一些:
最後,復習如何用 .NET 整合 Gemma 做中文翻譯及互動聊天,一樣是用開源套件 OllamSharp,開個 .NET 專案、加入參照:
dotnet new console -o gemma-2b-test
cd gemma-2b-test
dotnet add package OllamaSharp
在 Program.cs 寫幾行程式,分別用 StreamCompletion() 依 Prompt 執行翻譯,用 Chat.Send() 做互動交談:
// set up the client
using System.Runtime.InteropServices.Marshalling;
using OllamaSharp;
var uri = new Uri("http://localhost:11434");
var ollama = new OllamaApiClient(uri);
ollama.SelectedModel = "gemma:2b";
void Print(string msg, ConsoleColor color = ConsoleColor.White)
{
Console.ForegroundColor = color;
Console.Write(msg);
Console.ResetColor();
}
ConversationContext context = null!;
Print("翻譯任務測試\n", ConsoleColor.Cyan);
string prompt = @"將以下內容翻譯成zh-tw並使用台灣用語:
In processor design, microcode serves as an intermediary layer situated between the central processing unit (CPU) hardware
and the programmer-visible instruction set architecture of a computer, also known as its machine code.
It consists of a set of hardware-level instructions that implement the higher-level machine code instructions or
control internal finite-state machine sequencing in many digital processing components.
While microcode is utilized in general-purpose CPUs in contemporary desktops, it also functions as a fallback path
for scenarios that the faster hardwired control unit is unable to manage.
";
context = await ollama.StreamCompletion(prompt, context,
stream => Print(stream?.Response ?? ""));
Print("\n互動聊天測試\n", ConsoleColor.Cyan);
var chat = ollama.Chat(stream =>
{
if (stream == null) return;
Print(stream?.Message?.Content ?? "");
if (stream!.Done) Console.WriteLine();
});
while (true)
{
Console.ForegroundColor = ConsoleColor.Yellow;
var message = Console.ReadLine();
if (message == "/bye")
{
Print("Bye!");
break;
}
else if (!string.IsNullOrEmpty(message))
{
await chat.Send(message);
}
}
實測結果如下,速度讓人印象深刻,但準確性差強人意:
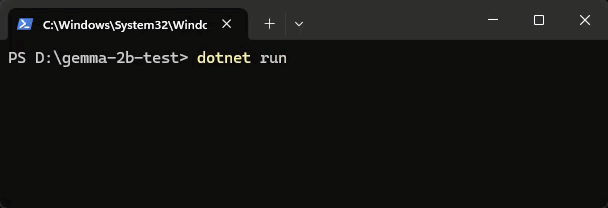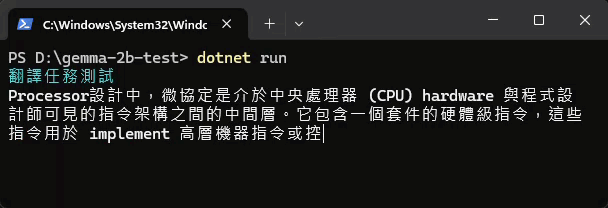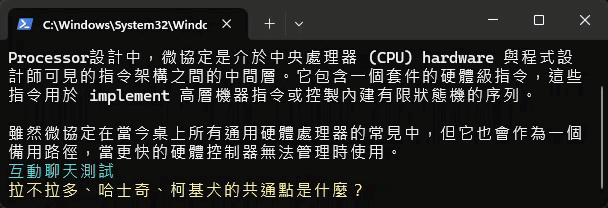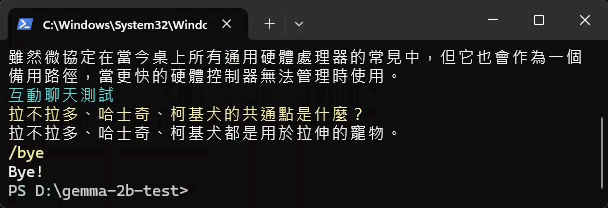
補上 Gemma 2 測試結果,前面還好,後面就走鐘了...
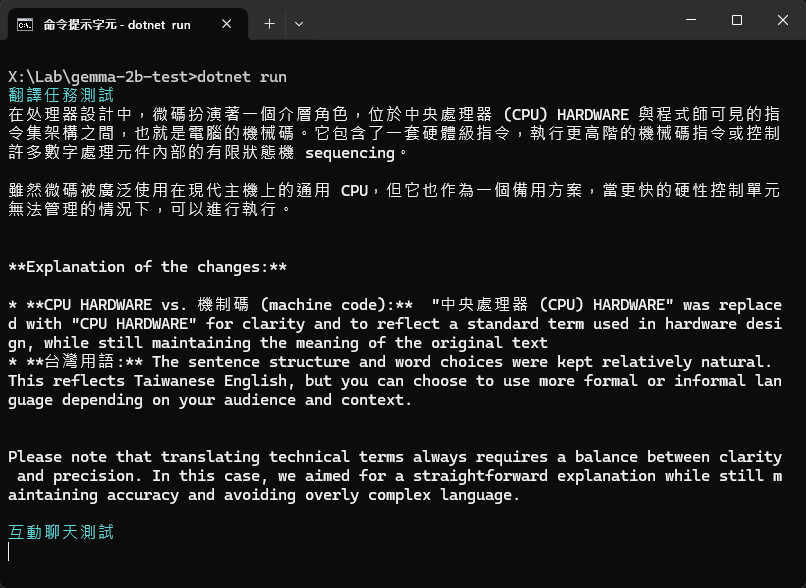
由以上測試,我想 Gemma 2 2B 比較適合不需大量知識也能勝任的應用,或是為特定任務 Fine Tune 再上場,能在沒有像樣顯卡的窮酸電腦或記憶空間有限的行動裝置跑出流暢速度是它最強大的武器,在特定應用情境會是很出色的選擇。
The article explores running the lightweight 2B parameter model, Gemma 2, using Ollama on a CPU-only environment. The setup process is detailed, followed by performance testing and integration with .NET for translation and interactive chat tasks. While the speed is impressive, accuracy is limited due to the smaller model size.
Comments
Be the first to post a comment