Coding4Fun - VB Strings.StrConv 簡繁轉換撞字清單
| | | 0 | |
前幾天分享的 Oracle 改 MSSQL 出中文亂碼問題,我想出 VB.NET Strings.StrConv 做簡繁轉換的解法,進一步實測踩到一枚小地雷。
我原以為 Strings.StrConv 只會轉換簡體中文字元,所以放心地把繁體中文內容也丟給它處理,沒想有卻有繁體字元被換掉了 - 「台」被換成了「臺」!
推敲了一下,應是因為簡體跟繁體都有台字,而我呼叫 StrConv 時傳入 CodePage 2052,讓繁體的「台」字被解讀成簡體的「台」,因而被對映成「臺」。面對這個狀況,我想到兩個 Workaround,第一是先用 big5.GetString(big5.GetBytes(raw)) != raw 檢測字串存在 BIG5 不相容字元時再轉換,但遇到繁體「台」字與其他簡體中文字元並存仍會有問題,所幸我的案例不致發生,可以忽略;第二個做法是事後將「臺」再置換回「台」,但風險是可能還存在其他類似情境的字元。最後我選擇了第一種做法搞定,但好奇心已被喚醒 - 多少字元有類似的繁體簡體「撞字」狀況呢?這是個一口吃完簡單有趣的 Coding4Fun 題材,就來伸展一下好了。
我先在網路上找到 BIG5 字元表:
再寫一小段程式,File.ReadAllLines() 讀入解析,逐一測試每個字元是否 Strings.StrConv(raw, VbStrConv.TraditionalChinese, 2052) 之後會變成另一個字元:
void Main()
{
Encoding big5 = Encoding.GetEncoding("big5");
Action<string> check = (raw) =>
{
var conv = Strings.StrConv(raw,
VbStrConv.TraditionalChinese, 2052);
if (conv != raw)
Console.WriteLine($"{raw} -> {conv}");
};
//Source: http://ash.jp/code/cn/big5tbl.htm
foreach (var line in File.ReadAllLines(
"d:\\all-big5-chars.txt", big5).Take(100))
{
if (Regex.IsMatch(line, "^[A-F0-9]{4}"))
line.Substring(6).Split(' ').ToList().ForEach(check);
}
}
答案出爐。
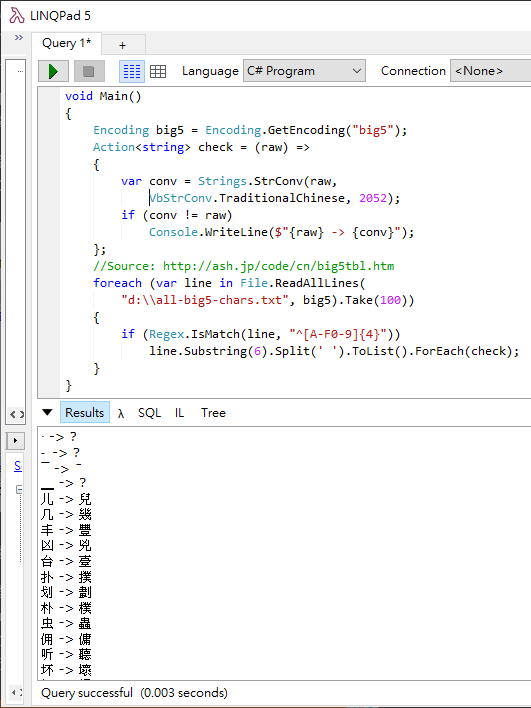
‧ → ?
╴ → ?
¯ → ˉ
ˍ → ?
儿 → 兒
几 → 幾
丰 → 豐
凶 → 兇
台 → 臺
扑 → 撲
划 → 劃
朴 → 樸
虫 → 蟲
佣 → 傭
听 → 聽
坏 → 壞
杆 → 桿
數量沒想像多,但問題較大的應該是「几」、「凶」、「划」幾個常用字被換成意義不同的用字,因此,確認來源是簡體時再轉換是較佳的解法。
Case of some Chinese chars could be converted to wrong chars in CHS/CHT conversion.
Comments
Be the first to post a comment