超高還原度的 PDF 轉 HTML 工具 - pdf2htmlEX
| | | 0 | |
介紹我最近常用的一個 PDF 轉 HTML 開源工具 - pdf2htmlEX。
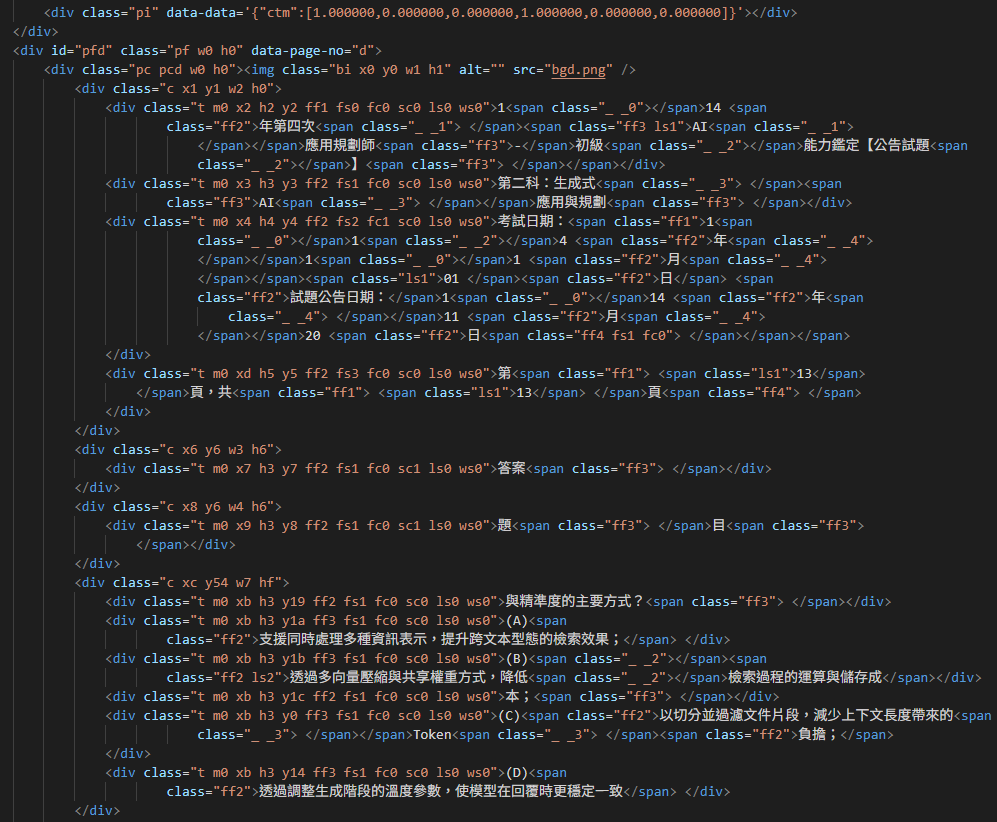
與一般 PDF 轉 HTML 工具以文字內容為重不同,pdf2htmlEX 的最大特色一望便知,它能超高度還原重現 PDF 的原始樣貌。如下圖,左邊是原始 PDF,右邊是 pdf2htmlEX 轉換成的 HTML,二者幾乎一模一樣。

不過,追求高逼真度讓 pdf2htmlEX 的 HTML 結構不那麼友善,畢竟要以排版優先,DOM 會像 Word 或 PDF 文件一樣被切得零散瑣碎,並充斥大量排版用的樣式設定與樣式標籤。為了保持文件的可攜性,pdf2htmlEX 將所有樣式、JavaScript、CSS、圖檔、woff 字型全部以內嵌方式塞進單一 HTML 裡,一個檔案就能把文件帶著走。缺點是 HTML 內容會變得很臃腫肥大,可讀性不佳,如想看一下其 HTML 有多可怕,這裡有範例,裡面的大量 Base64 編碼內容是 woff 字型及圖檔。若要看乾淨一點的 DOM 結構,這個是將 .css、.js 及圖檔抽離成外部檔案後的版本。(如下圖)
pdf2htmlEX 之所以能還原與原始 PDF 幾乎相同的排版,一大原因是它會將 PDF 使用的字體提取並轉換為 Web 字體(.woff 格式),確保即便使用者電腦沒安裝該字體,也能在網頁上看到正確的文字外觀。但依上回的實測經驗,這種做法遇到細明體、標楷體等字體,在 Mac 平台會出現中文字大量崩壞變形。
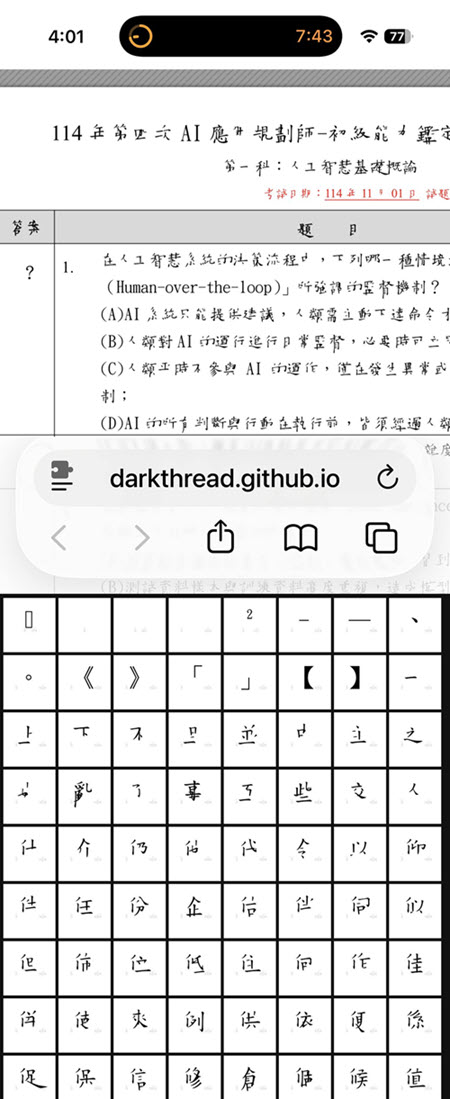
原因是標楷體等 ttf 檔案為了節省儲存空間,其向量圖形會將每個漢字的筆劃(如橫、豎、點、勾等)分別勾勒,但出廠時並未把筆劃疊合。遇到 Adobe Acrobat、Illustrator 或 Corel Draw 等軟體,標楷體的文字被轉成曲線後會有漢字筆畫被逐筆分拆解(如「化」字,可分為「丿」、「丨」、「一」和「乚」四個筆畫)導致位置大小錯亂的問題。這個問題較好的解法是從源頭避用這類古老字體(選用它們其實也埋了 Unicode 支援地雷),再不然就是修改 HTML 換掉字型。
另外,pdf2htmlEX 轉換的文件元素結構以頁為單位,為忠實還原原始排版,大量使用絕對座標,轉換後很難當成正常 HTML 使用。
但,如果你的需求是轉出來的網頁看起來要跟原本的 PDF 一模一樣,則 pdf2htmlEX 是很好的選擇。
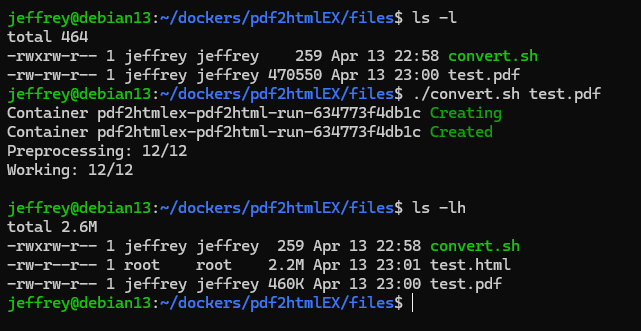
最後,介紹一下怎麼使用。建議用 Docker 跑最省事,我的做法是用以下 docker-compose.yml 建立容器:
services:
pdf2html:
image: pdf2htmlex/pdf2htmlex:0.18.8.rc2-master-20200820-ubuntu-20.04-x86_64
working_dir: /pdf
volumes:
- ./files:/pdf
- ./fonts:/usr/share/fonts/local
在 files 下寫個 convert.sh:
#!/bin/bash
if [ -z "$1" ]; then
echo "./convert.sh <pdf-filename>"
exit 1
fi
FILENAME=$(basename "$1") # get only filename
if [ ! -f "$FILENAME" ]; then
echo "File not found: $FILENAME"
exit 1
fi
docker compose run --rm pdf2html "$FILENAME"
將要轉換的 PDF 放在 files 資料夾,執行 ./convert.sh <pdf-name> 即可得到同名 .html 檔囉~
Comments
Be the first to post a comment