【茶包射手日記】變種茶包之又見 Oracle 中文亂碼問題
| | | 0 | |
接獲問題通報,某轉擋排程寫入 Oracle NVARCHAR2 欄位時中文難字變成亂碼。查看原始碼,其使用 ODP.NET 讀取來源資料表內容後,轉換成 INSERT 或 UPDATE 指令,以 N'...' 傳值寫入 NVARCHAR2,依據十年前的研究心得,只要搭配 ORA_NCHAR_LITERAL_REPLACE = TRUE 環境變數,寫入 Unicode 難字不是問題。(註:此招僅限 ODP.NET,不適用 Managed ODP.NET 及 System.Data.OracleClient)
而問題程式在執行 INSERT 及 UPDATE 前,確實有呼叫 System.Environment.SetEnvironmentVariable("ORA_NCHAR_LITERAL_REPLACE", "TRUE");,但寫入中文難字仍然變成亂碼。
莫非,茶包也會基因突變,又產生 Oracle 中文亂碼問題又出現新的變種茶包?
苦思了一會兒,福至心靈,想到一種可能:ORA_NCHAR_LITERAL_REPLACE 是在建立連線時就決定了,並非在 OracleCommand 執行時。排程程式在執行 INSERT/UPDATE 前,有用相同連線字串連線資料查資料,依據前陣子研究 Connection Pooling 的心得,SQL/Oracle 預設都會啟用 Connection Pooling,所以狀況是在還沒設定 ORA_NCHAR_LITERAL_REPLACE 前建立的連線,查完資料表後被放回 Connection Pool,之後設好 ORA_NCHAR_LITERAL_REPLACE 要建立連線跑 INSERT/UPDATE 時,用的卻是先前查資料用的那條處理中文會有問題的連線, 轟!
假設歸假設,要如何證明呢?於是我設計了以下實驗:
class Program
{
const string cs1 = "data source=MyOraSvr;user id=USER;password=****;connection timeout=30";
static string cs2 = "data source=MyOraSvr;user id=USER;password=****;connection timeout=30;pooling=false";
static string cs3 = "data source=MyOraSvr;user id=USER;password=****;connection timeout=31";
static void Main(string[] args)
{
ClearTable(cs1);
RunTest(cs1, 1); //寫入第 1 筆,使用 cs1
RunTest(cs2, 2); //寫入第 2 筆,使用 cs2
System.Environment.SetEnvironmentVariable("ORA_NCHAR_LITERAL_REPLACE", "TRUE");
RunTest(cs1, 1); //寫入第 3 筆,使用 cs1
RunTest(cs3, 3); //寫入第 4 筆,使用 cs3
RunTest(cs2, 2); //寫入第 5 筆,使用 cs2
}
static void ClearTable(string cs)
{
using (var cn = new OracleConnection(cs))
{
cn.Open();
var cmd = cn.CreateCommand();
cmd.CommandText = "delete from jefftest";
cmd.ExecuteNonQuery();
}
}
static int idx = 1;
static void RunTest(string cs, int csNo)
{
using (var cn = new OracleConnection(cs))
{
cn.Open();
var cmd = cn.CreateCommand();
//警告:** 串接 SQL 指令會隱含 SQL Injection 風險,情節嚴重時可致身敗名裂家破人亡 ***
//本範例因示範需要,參數非外界輸入且為數字,已排除 SQL Injection 風險,故採串接 SQL 指令方式執行
//若寫入值來自外界輸入,若無不可抗力因素,應一律使用 Parameter
cmd.CommandText =
$"insert into jefftest values ({idx},'CS{csNo}',N'犇珉', {DateTime.Now:fff})";
cmd.ExecuteNonQuery();
idx++;
}
}
}
我設了三條連線字串 cs1, cs2 及 cs3。分別用 cs1、cs2 寫入兩筆資料,之後設定 System.Environment.SetEnvironmentVariable("ORA_NCHAR_LITERAL_REPLACE", "TRUE"),接著再分別用 cs1, cs3, cs2 寫入三筆資料,結果如下, 1、2、3 筆為亂碼,4、5 筆正確:
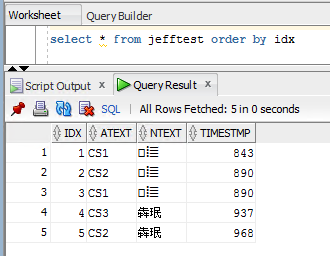
1、2 筆在 ORA_NCHAR_LITERAL_REPLACE 設定前執行,變成亂碼在意料之內。設定 ORA_NCHAR_LITERAL_REPLACE 後,第 3 筆用連線字串 cs1 建立連線,但因為預設會啟用 Connetion Pooling,故實際使用的是寫入第 1 筆時建立的舊連線(當時還沒設定 ORA_NCHAR_LITERAL_REPLACE),故寫入結果為亂碼。第 4 筆使用 cs3,連線字串跟 cs1 不同,差異點雖無關痛癢(connection timeout=30 vs connection timeout=31),但 Connection Pool 的原則是連線字串不同就不共用,故用 cs3 會新建連線,寫入結果正確。第 5 筆跟第 2 筆一樣是用 cs2,但連線字串加了 pooling=false 停用 Connection Pooling,故寫入第 5 筆時需新建連線,故寫入結果也是正確的。
找出問題根源,解決只在彈指之間,程式啟動前或還沒建立任何連線前先設定好 ORA_NCHAR_LITERAL_REPLACE 環境變數,即可避免問題。
10 年前發現,ODP.NET 執行 INSERT INTO ... VALUES (N'犇'...) 想正確寫入中文,必須設定 ORA_NCHAR_LITERAL_REPLACE = TRUE;上個月,我則是對 SQL Connection Pooling 有較深刻的體認,結合相距十年學到的兩項知識是今天順利解決茶包的關鍵,感覺挺奇妙的。
A nvarchar unicode issue caused by ODP.NET connection pooling behavior.
Comments
Be the first to post a comment