固若金湯的 Linux 也會當機?BSOD 藍色當機畫面不全是 Windows 的錯?
| | | 1 | |
前幾個月為了將家用迷你伺服器從 CentOS 7 升級到 Debian 12,我從閒置筆電挖了出一顆閒置 240GB SATA SSD 裝機。升級後陸續發生幾次,跑沒幾天便會因不明原因死機但重開機又 OK。這幾次當機事件非同小可,因為我心中「Linux 系統超穩,兩三年不重開都沒問題」的信念已開始動搖。
家用伺服器平日沒接螢幕鍵盤,當機後再接螢幕鍵盤已無任何反應,但伺服器上網站還在跑還能連,但無法 ssh 也沒法本機登入,只剩關機重開一條路。重開機後用 journalctl -b -1 查詢上次系統開機到關機期間的所有日誌,很快發現這件事不是 Linux 的鍋,是 SSD 硬體故障造成!
請 AI 協助判讀,問題出在這顆 240GB SSD 發生了 interface fatal error,主機與硬碟間的訊號握手失敗,喚醒通訊時發生錯誤,傳輸過程發生無法復原的資料錯誤。Linux 核心自我保護機制將連線速度由 6.0 Gbps (SATA 3) 降到 3.0 Gbps (SATA 2) 以求穩定,但降速後仍持續發生相同錯誤。
11月 24 19:32:09 debian12 kernel: ata2: SATA max UDMA/133 abar m2048@0x81315000 port 0x81315180 irq 119
11月 24 19:32:09 debian12 kernel: ata2: SATA link up 6.0 Gbps (SStatus 133 SControl 300)
11月 24 19:32:09 debian12 kernel: ata2.00: ATA-9: WDC WDS240G2G0A-00JH30, UF450000, max UDMA/133
...
11月 24 19:32:09 debian12 kernel: ata2: hard resetting link
11月 24 19:32:09 debian12 kernel: ata2: SATA link up 6.0 Gbps (SStatus 133 SControl 300)
11月 24 19:32:09 debian12 kernel: ata2.00: configured for UDMA/133
11月 24 19:32:09 debian12 kernel: ata2: EH complete
11月 24 19:32:09 debian12 kernel: ata2.00: exception Emask 0x10 SAct 0x41 SErr 0x840000 action 0x6 frozen
11月 24 19:32:09 debian12 kernel: ata2.00: irq_stat 0x08000000, interface fatal error
11月 24 19:32:09 debian12 kernel: ata2: SError: { CommWake LinkSeq }
11月 24 19:32:09 debian12 kernel: ata2.00: failed command: READ FPDMA QUEUED
...
11月 24 19:32:10 debian12 kernel: ata2: limiting SATA link speed to 3.0 Gbps
11月 24 19:32:10 debian12 kernel: ata2.00: exception Emask 0x10 SAct 0x3bbfbcc SErr 0x440100 action 0x6 frozen
11月 24 19:32:10 debian12 kernel: ata2.00: irq_stat 0x08000000, interface fatal error
11月 24 19:32:10 debian12 kernel: ata2: SError: { UnrecovData CommWake Handshk }
11月 24 19:32:10 debian12 kernel: ata2.00: failed command: WRITE FPDMA QUEUED
使用 sudo smartctl -a /dev/sda 檢查 SSD 沒什麼損壞區塊,健康度挺好,但資料傳輸嚴重出錯是不爭事實,換了條 SATA 排線,跑不到一天還是冒出相同錯誤,看來是主板 SATA 埠或 SSD 硬體有問題。爬文發現這塊拾荒來的 SSD 型號被傳出品質有瑕疵,網路已有不少鬼故事,我看到的訊息類似網友分享 SSD 即將暴斃的前兆,愈看愈毛,當下決定塊陶!!

搬出原本 CentOS 用的 M.2 64GB SSD,再重裝一次 Debian 12,趁 240GB SSD 資料連能讀把東西搬出來。幸好上回安裝筆記寫得夠詳細(寫部落格最大的受益者是自己啊),快手快腳裝好 Docker 服務,把 網路品質監控、Prometheus + Grafana 豪華全家桶跟智慧插座耗電量監控等容器掛回去,服務依舊,其實已換過 SSD 重裝過 OS。哦,Docker 我要為你輕輕唱首歌~~
所以,當機不全然都是作業系統不穩,婁子有時是硬體捅的。
講到這個議題,剛好 Linus Tech Tips 頻道上星期有支 Linus 大神親自動手組 PC 的影片(希望他有買到便宜的 DDR RAM):「Building the PERFECT Linux PC with Linus Torvalds」(目前已超過 300 萬次觀看),在 9'37" 時 Linus 天外飛來一筆為 Windows 常被嘲笑不穩定抱屈,認為當機不盡然全軟體的錯:
I mean, it's a big thing. And I'm convinced that all the jokes about unstable Windows is and blue screening. A big percentage of those were not actually software bugs. A big percentage of those are hardware being not reliable.
我的意思是,ECC 與硬體可靠性其實很關鍵。而且我很確定,大家拿 Windows 不穩定跟藍色當機畫面開玩笑,其中很大一部分其實不是軟體 bug,而是硬體本身不可靠。
他認為關於 Windows 不穩及 BSOD 藍白當機畫面的笑話很多並不是軟體 Bug,而源自硬體不穩定或不可靠,因此 ECC 記憶體等硬體品質對穩定性很關鍵。
【同場加映】
重裝後我還打了一個小副本,發現 cAdvisor 無法偵測到容器 CPU、記憶體等資訊數據,錯誤訊息是 failed to get docker info: Error response from daemon: client version 1.41 is too old. Minimum supported API version is 1.44, please upgrade your client to a newer version。爬文發現這是 5.29 版 docker-ce API 包含 Breaking Change 導致不相容,試了改 /etc/docker/daemon.json等解法,也沒搞定。最後使出降版大法,先用 apt list -a docker-ce | head 查可用版號:
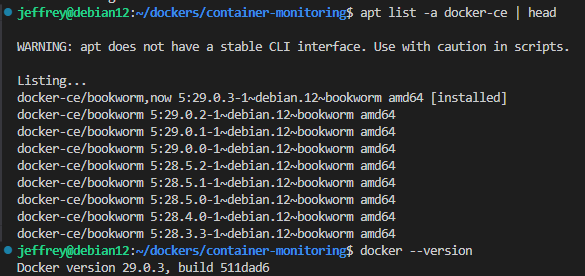
用以下指令裝回 5.28.5.2.1 docker-ce 成功解決問題:
sudo apt remove docker-ce docker-ce-cli containerd.io
sudo apt install -y \
docker-ce=5:28.5.2-1~debian.12~bookworm \
docker-ce-cli=5:28.5.2-1~debian.12~bookworm \
containerd.io
sudo systemctl restart docker
docker version
註:前兩天 cAdvisor 釋出新版似乎已能相容 5.29,但我已賴得再試。
Comments
# by Mason
ECC 記憶體蠻重要的,需要長時間運作的機器有ECC還有機會透過作業系統得知異常重啟,沒有就真的隨機靈異事件。