【茶包射手日記】連字變亂碼
| | | 0 | |
收到一封 Email 內含奇怪內容 - stac.microso,依常理推測是 ti、ft 被轉成不明字元。行走江湖多年,我馬上意識到這應該跟字型的連字 Ligature 功能 有關。
所謂連字是指歐語系文字為求美觀,會為 ct、st、fb、fh、fj、fk、ff、fi、fl、ffi、ffl 這些組合另外創造多個字母連在一起的專屬字型,如此可改善字距不合理、多一個墨點看起來髒髒的... 等問題。但,連字字型是渲染階段的事,搞到原文都被改了是怎麼一回事?想想,若隨便把程式或報告裡 static int offsetX、1000 ft 的 ti、ff、ft 給換了,能不天下大亂嗎?
做了解析,用 JavaScript decodeURI() 轉換這段文字可以得到 'sta%F4%80%86%9Fc.microso%F4%80%85%8C',由此可知 ti 被轉成 UTF8 0xf480869f、ft 則是 0xf480858c,它們落在 U+100000~U+10FFFF,屬於 Plane 16 私用區(Private Use Area, PUA-B),類似 BIG5 的造字區。有些字型如 Fira Code、Cascadia Code 會用 PUA-B 的字元碼對映連字字型。

查了一下,得知實務上常發生這類問題的情境是 - 從 PDF 複製文字貼上。
問題出在 PDF 文件的「視覺呈現(Glyphs)」與「語義編碼(Semantics)」脫節,PDF 是為了列印排版所設計的格式,內部儲存的是 Glyph ID, 當選取包含 ti 或 ft 這類連字內容時,PDF 閱讀器會依據內嵌的 ToUnicode 對映表 (CMap) 將合字圖形轉換成標準 t、i 或 f、t 字元。
若製作 PDF 時未正確寫入 CMap,或者使用了 Identity-H 等特殊編碼卻未提供對應的 Unicode 值,PDF 閱讀器在複製時就無法轉換成正確字元,只能直接抓取該字型檔內部的原始索引值。而這些連字通常沒有標準的 Unicode 編碼,字型廠商或轉檔軟體常將其對映到 PUA 私用區,甚至是更高位元的 PUA-B (第 16 平面) 以免與標準字元衝突,導致複製出來的是專屬該原始字型的內部代碼,貼到別處便成了亂碼。
信件被輾轉轉寄多次,不好殺去源頭追查,也很難重現確認,但以上的推測頗為合理,先行簽結,待有新事證或線索再重啟調查。
【同場加映】Word 要設連字,可先選擇支援連字的字體,例如:Calibri、Constantia、Cambria、Corbel、Gabriola、Palatino Linotype 等,再使用「字型/進階/OpenType 功能/連字」下拉選單設定:(切換後下方可直接看效果)
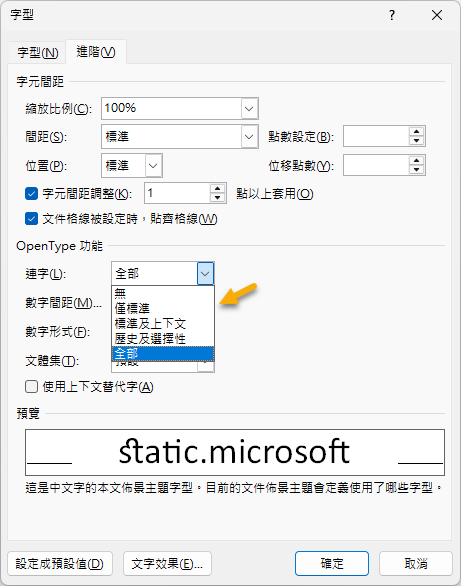
選項說明:
- 標準(Standard Only):以提高可讀性為目的的連字,例如:fi、fl、ff、ffi、ffl
- 標準及上下文(Standard and Contextual):根據上下文判斷,主要針對手寫體或斜體字,例如,a 接在 o 後面時模擬一筆書寫的效果
- 歷史及選擇性(Historical and Discretionary):包含純裝飾用或古代風格連字,如 hist 顯示為 hiſt,為了花俏把 ct、st、sp、ti、ft 連在一起。
- 全部(All):全都要
Comments
Be the first to post a comment