使用 Headless Chrome 擷圖、轉存PDF、爬資料
| | | 6 | |
Chrome 自 59 版起內建了 Headless 模式,允許透過命令列啟動 Chrome 以無 GUI 方式執行,具備與正常開啟完全相同的網頁渲染及 JavaScript 引擎,還可透過網路連線遙控。這個功能可以用於不少有趣應用,這裡列舉幾種實用情境。
註:Headless Chrome 的完整參數可參考 List of Chromium Command Line Switches « Peter Beverloo
網頁擷圖
將網頁存成圖檔或 PDF,過去我是用 PhantomJs。Headless Google 的出現,能取代 PhantomJS 功能且更快更穩,讓 PhantomJS 作者決定停止辛苦的獨力維護工作,PhantomJS 的Github 專案也已封存,故改用 Headless Chrome 已成定局。
要使用 Headless Chrome 擷圖很簡單,在命令列工具輸入:
"c:\Program Files (x86)\Google\Chrome\Application\chrome.exe" --headless --screenshot=E:\Chrome\test.png --disable-gpu --window-size=320,568 https://www.microsoft.com
即可取得圖檔如下:
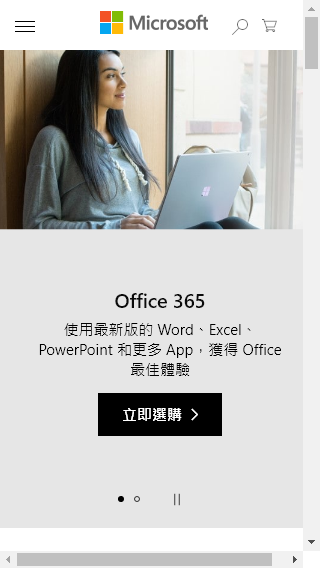
很簡單吧?
如要模擬行動裝置,則可加入--user-agent="…" 指定User-Agent。例如 Google 網站預設是以桌上電腦解析度呈現,遇直式小螢幕解析度不會自動切換:
"c:\Program Files (x86)\Google\Chrome\Application\chrome.exe" --headless --screenshot=E:\Chrome\test.png --disable-gpu --window-size=320,568 https://www.google.com.tw
擷圖時只能看到部分內容:

遇此狀況,可加上--user-agent="" 傳入 iPhone 5/SE 的 User-Agent 字串克服:
"c:\Program Files (x86)\Google\Chrome\Application\chrome.exe" --headless --screenshot=E:\Chrome\test.png --disable-gpu --window-size=320,568 --user-agent="Mozilla/5.0 (iPhone; CPU iPhone OS 10_3_1 like Mac OS X) AppleWebKit/603.1.30 (KHTML, like Gecko) Version/10.0 Mobile/14E304 Safari/602.1" https://www.google.com.tw
加上 User-Agent 後,Google 網站改回傳行動裝置專屬排版(底下還有 App 安裝提示):
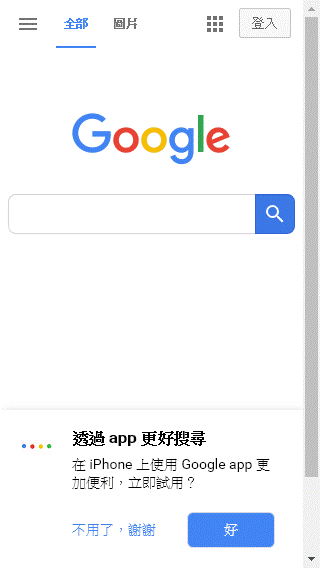
網頁另存PDF
使用參數--print-to-pdf 可模擬瀏覽器列印功能,將網頁存成PDF,例如:
"c:\Program Files (x86)\Google\Chrome\Application\chrome.exe" --headless --print-to-pdf=E:\Chrome\test.pdf --disable-gpu http://www.microsoft.com
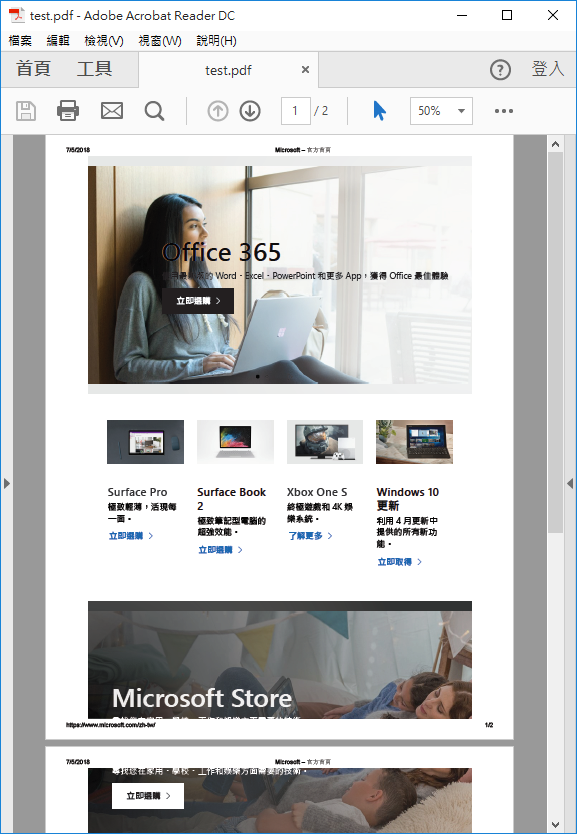
線上偵錯
遇到 Headless Chrome 行為未如預期時,一樣可用 F12 開發者工具偵錯,做法是透過--remote-debugging-port=xxxx 參數開啟線上偵錯功能:
"c:\Program Files (x86)\Google\Chrome\Application\chrome.exe" --headless --remote-debugging-port=9222 --disable-gpu http://www.microsoft.com
啟動 Headless Chrome 後,再另開一個 Chrome 連上 localhost:9222,可得到已開啟網頁清單:
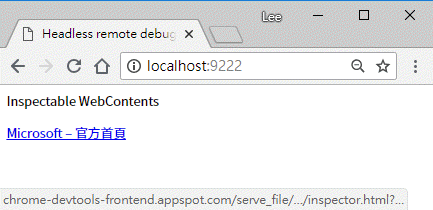
點選後即可比照一般網頁使用 F12 開發者工具偵錯:
網頁爬蟲、自動測試
除了擷圖跟存 PDF,我們也可以寫 JavaScript 程式操作 Headless Chrome 執行較複雜的動作,很適合用來執行自動測試或擷取網頁內容。要透過 JavaScript 操作 Headless Chrome,需借助一個 Node.js 程式庫 - Puppeteer。 開始之前需先安裝 Node.js,再使用 npm 安裝 Puppeteer。(註:安裝 Puppeteer 預設將一併安裝 Chromium 執行檔,如想直接使用 Chrome 不額外下載,可使用指令 env PUPPETEER_SKIP_CHROMIUM_DOWNLOAD=true npm i --save puppeteer 參考)
Node.js 支援 ECMAScript 6,跟我平常網頁在寫的 JavaScript 寫法大異其趣。但我爬了幾篇文章,倒是也能寫出 Google 查詢關鍵字並抓回搜尋結果的簡單程式。(補充:Puppeteer API 文件 https://github.com/GoogleChrome/puppeteer/blob/master/docs/api.md )
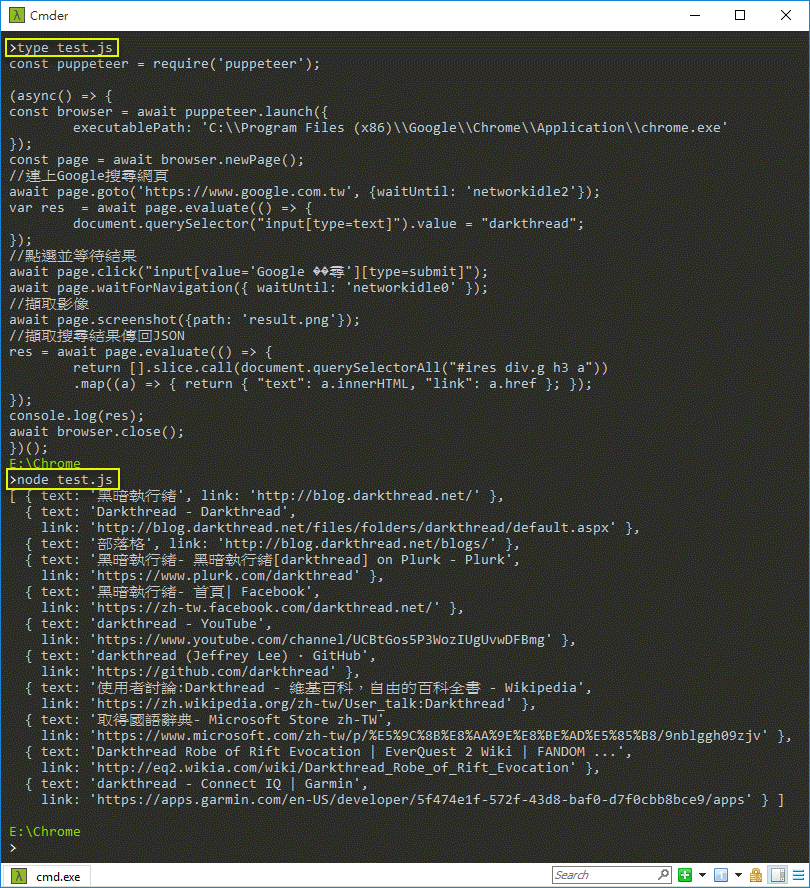
程式範例如下:
const puppeteer = require('puppeteer');
(async() => {
const browser = await puppeteer.launch({
executablePath: 'C:\\Program Files (x86)\\Google\\Chrome\\Application\\chrome.exe'
});
const page = await browser.newPage();
//連上Google搜尋網頁
await page.goto('https://www.google.com.tw', {waitUntil: 'networkidle2'});
var res = await page.evaluate(() => {
document.querySelector("input[type=text]").value = "darkthread";
});
//點選並等待結果
await page.click("input[value='Google 搜尋'][type=submit]");
await page.waitForNavigation({ waitUntil: 'networkidle0' });
//擷取影像
await page.screenshot({path: 'result.png'});
//擷取搜尋結果傳回JSON
res = await page.evaluate(() => {
return [].slice.call(document.querySelectorAll("#ires div.g h3 a"))
.map((a) => { return { "text": a.innerHTML, "link": a.href }; });
});
console.log(res);
await browser.close();
})();
實測如下:
工具箱再添新武器一件。
Tutorial of using headless Chrome to capture web page or export as pdf. With Puppeteer you can even use it to make a crawler or web page tester.
Comments
# by paicheng
感謝黑暗大的這篇文章。 我過去都在Python用Selenium + PhantomJS,如今可以試著轉到selenium + headless Chrome
# by Joy
感謝大大! 如果想把pdf改橫向怎麼改呀?
# by Jeffrey
to Joy, 依據網友的研究心得 https://superuser.com/a/1281535/264724 ,不太可行。
# by Joy
OK! 感謝Jeffrey! 只好另尋他路 利用 Puppeteer不知是否可行
# by 陳瑋棋
1.略過安裝Chromium 最新方式 npm config set puppeteer_skip_chromium_download true -g 2.然後您的code最後要catch 不然會報UnhandledPromiseRejectionWarning 參考 1. https://github.com/GoogleChrome/puppeteer/issues/2262#issuecomment-407405037 2. https://objcer.com/2017/12/27/unhandled-promise-rejections-in-node-js/
# by Jeffrey
to 陳瑋棋, 感謝分享。