我為何改觀?GPT-4 強勢登場後,離 AI 取代人類只剩多遠?
| | | 9 | |
【前情提要】幾天前,從一支影片與一篇文章出發,我分享了閱讀心得 - ChatGPT 離 AI 取代人類還有多遠?,「當時」我將 ChatGPT 定調為 - 大型語言模型(LLM)依靠消化海量資料加上人工巧妙調教,練就一身「不管問他什麼,總能說得頭頭是道煞有其事」的好本領,但 ChatGPT 不懂得判斷對錯,不會算數學,沒有邏輯推理能力,全憑數學演算法拼湊人類最容易買單的字句組合,屬於弱人工智慧。真要取代人類,需融入因果網路 (Causality Network) 再利用融合式系統 (Hybrid) 設計以實現強人工智慧。
這個觀點搭配實測 ChatGPT 3.5 不時得到的傻氣回答,讓我們對其正確性還頗有信心的。文章發表後,在臉書專頁引發不少迴響(感謝參與討論的大家,這裡就不一一致謝了),歷經一連串回饋與新資訊洗禮,才短短幾天,不得不承認:我已對 GPT 徹底改觀了!
(臉書討論串網友 Han Han 有則辛辣回饋:「你過兩年再來看看你這篇文章。」,我當時的回覆是:只要有新的輸入,我的想法肯定不會一樣,過程也會有新的心得,這是不被取代的要件。事實證明,我的想法真的會隨新輸入改變,還只花了兩天,噗! 那未來還會不會變?當然! 不然咧?)
先說最重大的發現 - 「GPT-4 與 ChatGPT 3.5 非同一個等級的東西」,放在一起討論並不恰當,是交流時認知分歧雞同鴨講的主因。GPT-4 的回答在正確性上有驚人的改善,故用 ChatGPT 3.5 的使用經驗去評論 GPT-4 肯定失真。(前篇心得基於 ChapGPT 3.5,這也是必須修正更新的理由)
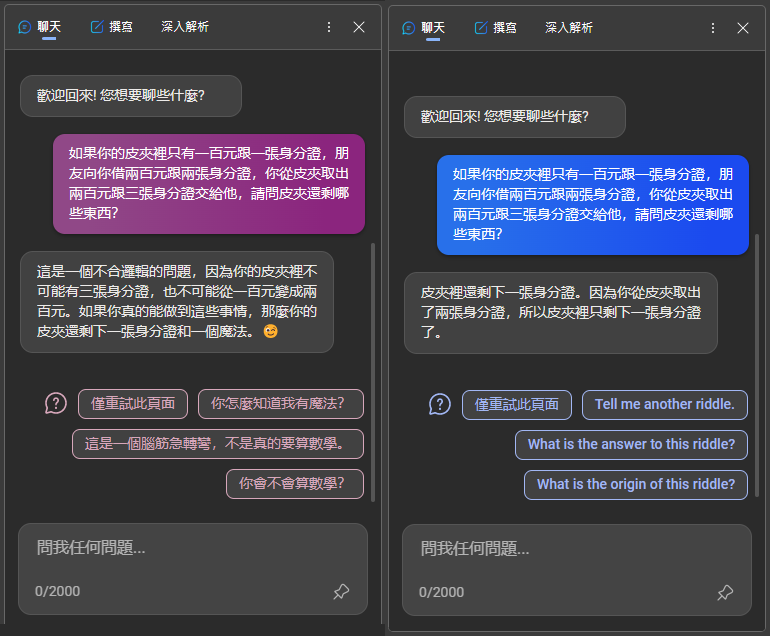
例如,且讓我們用「反事實測試」來羞辱 ChatGPT-3.5:
如果你的皮夾裡只有一百元跟一張身分證,朋友向你借兩百元跟兩張身分證,你從皮夾取出兩百元跟三張身分證交給他,請問皮夾還剩哪些東西?
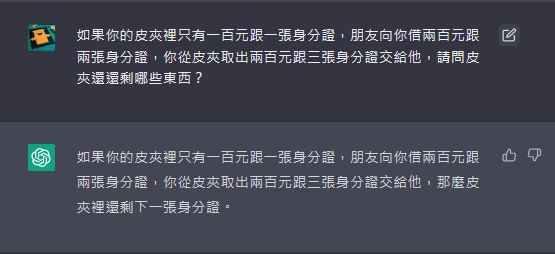
哈哈哈哈,你看看你,去哪生出不存在的一百元跟兩張身分證給別人啦?一張身分證給完三張還剩一張是什麼鬼?
但同樣的問題拿去問 ChatGPT-4,猜猜 ChatGPT-4 會怎麼回答的?(註:我沒有 ChatGPT-4,以下為模擬畫面)
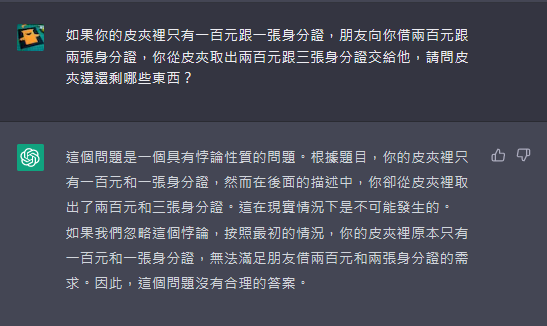
幹... 怎麼有點強?
另外幾種答案:(感謝 Cheney、曾永裕、程凱大 提供)
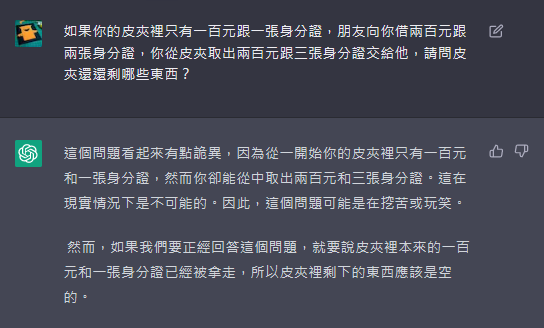
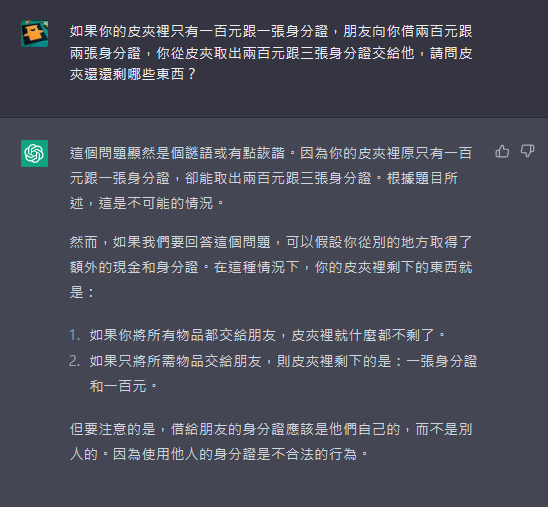
是不是有點毛骨悚然?
註:號稱使用 GPT-4 的 Bing Chat 也能正確回答,但模式要切到「富有創意」(左),「平衡」模式的答案(右)接近 3.5:
不是說語言模型沒有推理能力,不懂因果推理?但 ChatGPT-4 的回答超越我對語言模型的認知,怎麼都不像一個由資料驅動,只會玩文字接龍的生成型語言模型?
以下整理臉書討論中我學到的新觀點:(討論過程有幸認識一位 AI 領域專家 - 香港一間 AI 技術公司(Apoidea)的 CEO,Cheney,透過討論及訊息交流,提供我許多具體剖析及專業見解,特此感謝)
- 前篇心得參考影片與文章的作者是小型語言模型廠商,會不會其對 ChatGPT/LLM 的觀點也存在立場呢?但如同文章所說,就算要廢其言終究得回歸科學分析,不然我們不也在依據立場判斷?(感謝 YaJing Liu 分享的犀利觀點)
- 語言模型有可能莫名冒出因果推理能力嗎?
有可能。所謂 Emerge 湧現/突現 意指許多小實體交互作用後產生了大實體,而這個大實體展現了組成它的小實體所不具有的特性。複雜系統中在自我組織的過程中,所產生的各種新奇且清晰的結構、圖案、和特性。
當語言模型參數大到一定程度,就會有可能出現湧現。(感謝 Jui Nan Chen、房懷安 分享) - ChatGPT 3.5 使用者跟 ChatGPT Plus (ChatGPT-4) 使用者心中的 ChatGPT 根本不能算是同一個東西,能力存在明顯差異,故溝通時常造成巨大的認知分歧,未來討論時應先確立前題
- ChatGPT 也足以被視為 AI 演進史的重大突破 - 原本被認為行不通的大型模型,在 RLHF (Reinforcement Learning from Human Feedback 人類回饋增強學習) 加持下變成人類可用的工具 (by Cheney)
- GPT-4 的三篇論文指出,大型語言模型產生了推理能力(強人工智慧的特徵),雖然還沒有辦法用科學解釋機制,但由對訓練數據不存在資訊也能做出正確推理,可以得到證明。(by Cheney)
- 目前語言模型並非一味追求靠更多參數提高精準度,也在朝縮小模型但維持推理能力努力,以及發展外接 Semantic Embedding 資料庫的做法(前篇心得說的 Hybrid AI),Bing Chat 跟 ChatGPT Plugin 便是朝此方向前進。(by Cheney)
後面我也整理了一些資訊,說明我為什麼改觀?是怎麼被說服的?分享給大家。
有幾篇值得一讀的文章:(有些偏學術論文性質,小心噎到)
論文:GPT-4 Technical Report by OpenAI
YouTube 影片(大推):GPT-4论文精读【论文精读·53】 (感謝 Airlian Her 分享)
- 經典案例:事後諸葛測試,依據一連險中求勝成功實例,問 LLM,事後看某次勝率微小但嬴錢的賭博,當初該不該賭一把?只有 GPT-4 答對,貌似有推理能力。(23'12")
- 去除訓練數據包含資料的考試題目,GPT-4 仍能取得高分
- GPT 產生的文字沒有中心思想跟想傳達理念,以作文寫作觀點拿不到高分
- CodeForce 考試:有人實測 2021 高分,2022 很差,推論 GPT-4 是基於數據;但有人用不同 Prompt 對 2022 題目得到好結果,無定論
- 多語系測試,連沒訓練過語言的表現都不差 (例如 Welsh 只有 60 萬人,但因相近英文,表現出奇地好)
- GPT-4 產出結果仍存在少樣錯誤,需要人工潤飾
- 識別圖片找笑點:手機接 VGA 接頭、排的像地球的炸雞塊
- 給 GPT-4 論文做總結,效果比預期好
- System Message - 特殊提示訊息(社群發現的),原本是用繞開限制的巧門。但 OpenAI 改用在好的方向:扮演蘇格拉底,堅持不給答案引導學生解題
- 限制 - 不完全可靠,有時會錯,應用在高風險領域要注意、數學仍然不好,但比以前版本好、缺少 2021/09 後的知識、有時會犯低級推理錯誤
- 安全性 - 去年 8 月就完成,後面都在做 Alignment,確保其安全性,拒絕不合法不道德的要求。(如何做炸彈?)
全球這麼多人玩,還是常被找出漏洞,路還很長。
批評:只展示結果,沒解釋訓練方法、數據細節、調校方式
中文導讀:GPT-4原论文详细解读(GPT-4 Technical Report)
論文:Sparks of Artificial General Intelligence: Early experiments with GPT-4
摘要:這篇來自微軟的論文旨在證明除了掌握語言之外,GPT-4 無需任何特殊提示便能解決涉及數學、編碼、視覺、醫學、法律、心理學等方面的新穎和困難任務。此外,在所有這些任務中,GPT-4 的表現與人類水平的表現非常接近,並且往往遠遠超過 ChatGPT 等先前模型。鑒於 GPT-4 的廣度和深度,微軟研究人員認為它可以合理地被看作是通用人工智慧/強人工智慧(AGI)系統的早期(但仍不完整)版本。
報導:微軟154頁研究,GPT-4 已具備進階心智能力!可以推斷他人情緒 by 商業週刊 (上篇論文的中文摘要報導,大推!)
論文指出,所謂強人工智慧(AGI)意指具有推理、規劃、解決問題、抽象思維、理解複雜思想、快速學習和經驗學習能力。GPT-4 有一兆個參數,是 GPT-3(1750億個參數)的六倍,在許多測試上展現近似 AGI 的能力。 文章列舉了一些令人吃驚的 GPT-4 應用案例:
- 生成 JavaScript 代碼,以產生畫家 Kandinsky 風格的隨機圖示
- 以莎士比亞的文學風格證明質數是無窮多的
- 撰寫一封支持 Electron 競選美國總統的信
- 替一個程式生成 Python 程式碼,只要在該程式輸入患者的年齡、性別、體重、身高和血液檢查結果,就能指出患者的糖尿病風險是否增加
- 使用可縮放向量圖形(SVG)生成物體圖像,如貓、卡車或字母時
- 模型透過字母Y、O和H的形狀,畫出一個人
- 結合並運用 Stable Diffusion 的能力,完成 3D 城市建模
- 用ABC記譜法,生成編碼和修改曲調
- 在零樣本的情況下,生成了一個滿足所有要求的 3D 遊戲
- 讀懂一段 C/C++ 程式,並預測程式的輸出結果
- 回答國際數學奧林匹克競賽(IMO)的問題(簡化版)
- 利用搜索引擎或 API 等外部工具回答問題
- 在複雜情境下,推斷他人情緒的原因
紐約大學心理學和神經科學名譽教授馬庫斯不認同 GPT-4 已達到強人工智慧的標準,基於 GPT-4 還無法處理複雜任務且相關資料、方法與架構均未公開,質疑論文的科學性。
論文:Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
這篇提到思維鏈(Chain of Thought 的 Prompting 技巧),藉由一系列中間推理步驟,如何顯著提高大型語言模型執行複雜推理的能力。研究對三個大型語言模型進行實驗,證明思維鏈提示可以提高算術、常識和符號推理任務的效率,驗證極好的投資報酬率。例如,用八個思維鏈示例提示挑戰 GSM8K 數學單詞問題基準測試,讓 540B 參數的語言模型打敗帶有驗證器的 Finetuned GPT-3。(Cheney 實測心得 - 非常有效)
Podcast:AI狂飙的时代,人还有价值吗? (感謝 Cheney 推薦)
這是木遙老師(UCLA 應用數學博士、曾任 Google 紐約工程師,參考)的一支 Podcast ,梳理我看到的重點:
- 截至 GPT-3.0,確實像個統計模型,3.5 產生了一次躍進 - 因果連結能力。AI 研究學者無法解釋它是怎麼做到的,但真的發生了,於是乎在 GPT-3.5 時,語言模型一下成熟起來了。
- 高等生物存在快思考與慢思考:傳統神經網路參數再多,過程再複雜,仍不脫輸入、計算、輸出的快思考模式;思維鏈(Chain-Of-Thought, COT)則是完全不同的做法,模仿人類思考,分成多個步驟一步一步推演,當今的 AI 已有能力實現。
- 訓練模型做好一件事比較簡單,過去也有許多成功案例(例如 AlphaGO),而強人工智慧,不只能做一件事,需要了解世界是怎麼運作的,你可以過透過語言指揮它完成沒被訓練過的動作。
- AI 100% 取代人類這件事不存在,但當它能取代你 50% 的工作能力,你便會受到衝擊。實例:文科背景害怕軟體的律師,但透過語言溝通的 ChatGPT 正符合其專長,還沒有辭退員工,但不打算再找實習生了。
所謂 AI 取代人,不一定是資遺員工,改用 AI 做人原本的工作,當兩個人可以做三個人的事,少了一個職缺,也是一種潛在的取代。 - 白領生活有 50% 是在處理瑣事,交給 AI 處理無需承擔心理壓力。
- GPT 本質是以對話為介面的服務,過去 Siri/OK Google 是假的有其侷限性,GPT 真正做到通用性,問什麼都可以回答(註:胡扯瞎回這件事到 GPT-4 已有明顯改善)
- ChatGPT 並不是一個最終產品,更像一個 Demo,評價它時應區分哪些是早期還來不及做好的?哪些是本質上的限制?GPT 是基於訓練資料的封閉模型,但串接真實世界資料庫在技術上沒有任何困難,不是限制。
- 工業革命時,人類的體力被取代,但腦力存在優勢。當 AI 革命來襲,我們要開始問自己,優勢還剩什麼?(註:或許要再回到肢體、勞動能力,直到機器人革命來臨)
- 近代人經歷過兩次革命 - Internet、行動裝置;都遠不及這次 AI 革命,它觸及了 - 人的存在價值是什麼?工業革命後人能以腦力自傲,未來呢?
GPT 能取代白領工作,還不能洗衣煮飯,與家庭勞動相比,誰比較沒價值? - 涉及人與人交流,需通曉人情世故、交際手腕、喬事情、打動人心... 等涉及人類微妙情緒反應的任務,AI 還無力取代。
- 有趣觀點:科舉花了 60 年才廢除。人類身為生物的慣性,捍衛自己及下一世代的世界觀,直到死亡世代交替才會徹底擁抱 AI 新時代。
- GPT 比你想像更能攻克創造性活動:在海量資料中找出連結,產生人類不會想到的組合。
- 吸收資訊建議:少看中文社交媒體、直接看英文源頭資料、第一線人員的討論比德高望重大神的觀點更有價值(他們易受成見所困,不易被扭轉)。
【結語】
說說我的不專業心得:
- 當大家討論起 AI 對 ChatGPT 能力看法分歧時,先確定要講 ChatGPT 3.5 還是 4?兩者是不一樣的東西。
- GPT-4 有多強?大力推薦去看看上面的微軟論文或商週報導。
- 身為語言模型的 GPT-4,貌似產生了弱人工智慧不該有的推理能力,目前沒有科學解釋,或許真的發生湧現(Emerge)了。我以前都要知道原理才願意接受事實,但或者現在得練習用「看到蘋果掉下來,以後牛頓才會提出解釋」的心態去面對它。
- GPT-4 算不算 AGI (強人工智慧) 我沒有能下結論的專業,但由其行為可視為有相當的推理能力,不管從而來,容我引用鴨子測試 - 如果它看起來像鴨子、游泳像鴨子、叫聲像鴨子,那麼它可能就是隻鴨子。Yes,GPT-4 具有一定的推理能力 - 這是強人工智慧的特徵之一。而且有一點事實不容忽視,即便 GPT-4 不算強人工智慧,無法完成取代人類,但它對你我的工作造成衝擊已成定局。
- 我現在已不太糾結 ChatGPT 回答開放性問題偶爾仍會胡言亂語,反正它給的答案仍需要人來把關。GPT-4 能理解問題,進行推理及執行動作這點,能改變的事情大多了。
- 所謂 AI 取代人,不一定是資遺員工改用 AI 做他們原本的工作。當兩個人可以做三個人的事,減少一個職缺,也是一種潛在的取代。
- 當 AI 隨時都在,可以回答你任何蠢問題、完成各種瑣碎小事,又不必承受請活人幫助的實際成本及心理壓力。想想這對工作方式可以帶來多大的改變?反過來想,只處理瑣事不負決策責任的角色最容易被 GPT 取代。
- GPT 以自然語言做為輸入輸出介面,使它不限於專業人員,而是普羅大普都能使用的生活工具。故要當心原本跟你不在同一個競爭水平上的人,能力瞬間提升,原本競爭優勢盡失。
- 至於人類會不會被 AI 取代?看看上面列舉 GPT-4 能做的事,在未來它們可能很快可改由機器代勞,而對 AI 產出成品再加工優化提升品質永遠是條活路,需要技能可能不同,但職位較少,只要技能頂尖的人。(有些老闆不講究,機器產出的直接用... )
再不然就要轉戰 GPT-4 無法勝任的領域,跟機器硬拼猶如與汽車賽跑,改鑽窄巷切換戰場。 - 依目前觀察到的發展,幾可預見 GPT 一定會改變我們的工作改變我們的生活改變世界運轉的方式,與其焦慮,不如保持開放心態,學習新工具接受新工具,提早做好準備吧!
- 我自己近期會格外關注 Office Copilot 與 Github Copilot X,作為開發老兵的
垂死掙扎終局之戰,希望在這波 AI 革命中仍保有優勢,潮水退去時還穿著褲子。
我想把這波 AI 革命想像成當年網際網路普及、搜尋引擎問市,雖然衝擊程度難以相比,身為人類的優勢都被威脅,但我打算用相似的過來人心態面對。遙想當年,當資訊彈指可得,靠資訊不對等謀利的生意一定因此凋零,這跟未來部分工作機會將被 AI 取代類似;但靠著瞬間得到所需資訊,我們學得更快、能解決原本無頭緒的難題,具備更強的能力,也會出現新的商機,同樣的想法也可能套用在 AI 革命上,不要花時間在 AI 能快速完成的瑣碎工作上(前題是要先學會靈活使用它),把省下來的時間拿來做 AI 做不到的事,產生價值,維護身為人類的尊嚴(哈!)。
很俗氣還是那句老生常談:保持開放心態,學習新工具,適應新時代,才不會被淘汰。共勉之。
Comments
# by Will
錯字: 「何」顯著提高大型語言模型執行複雜推理的能力
# by Jeffrey
to Will, 感謝指正。
# by San
可以分享一些關於『AI 做不到的事,產生價值』嗎?這問題值得關注:)
# by Winston
感謝分享!
# by ChrisTorng
提供意見。過去我一直努力精進英文能力,但我知道機器翻譯的進步速度遠高過自己英文的進步速度。現在我已經放棄精進自己的英文能力,大量看 AI 相關英文文章ーー的翻譯。知識能力的進步速度更快,這點比英文的進步更加重要更有意義。善用 AI 能力,不用再堅持一切靠自己做。
# by ChrisTorng
前面忘了要說重點。文中引的「湧現」是中文維基連結,說明非常少。若直接讀英文版 https://en.wikipedia.org/wiki/Emergence 的翻譯,會學到更多更多東西...我只用 Edge 內建的翻譯,它還不是使用 ChatGPT (因為速度飛快),但閱讀理解幾乎沒什麼太大問題了。我就是注意到這個所以才發上篇留言。再接著推論下來,中文版維基已經沒有什麼存在意義,全部都看英文版的翻譯就可以了...
# by Ike
錯字回饋: 還沒有辭退員工,但不再算再找實習生了 還沒有辭退員工,但不[打]算再找實習生了 評價它時應區分哪些是早期還來不做好的? 評價它時應區分哪些是早期還來不[及]做好的?
# by Jeffrey
to lke, 感謝,已修正。錯字是讓本站文章更有溫度跟人味的關鍵呢~ (謎:你再鬼扯沒關係)
# by Jeffrey
to ChrisTorng,感謝分享,有試了一下 Edge 翻譯,速度頗快操作也算方便。但我覺得它翻譯新聞、故事類還行,專業文章常會遇到術語專用名詞被誤翻,逼得我切回原文對照。這類文章要翻得好,程式必須能讀懂專業文件,通曉前後文,不能只處理字詞對映,這塊應該就是 GPT 或 AGI 在追求的方向。