Coding4Fun - 比較兩張照片的相似度
| | | 2 | |
上週提過將影片每一秒畫面存成照片的技巧,被我拿來找英聽影片例句說明的時間點。
如下圖所示,某個 100 句英聽練習影片有個規律,每個句子無字幕播兩遍,配中文字幕再播兩遍,無字幕播放時畫面都是相似的,中央有大大的 Listen 字樣配上旋轉星空背景,我想靠由這個規律挑出所有例句的字幕畫面。

這個問題有好幾種解法,最最最簡單的做法 - 用眼睛看,點 100 次滑鼠把例句畫面挑出來。重複手工學不到東西,白白浪費程式練習機會。2026 年,大家馬上想到的另一條路應該是直接丟給 GPT、Gemini,多模態大型語言模型能理解和生成文字、圖像、音訊、影片,識別畫面任務是小菜一碟,但丟給 AI 厲害的是 AI,對於影像處理我繼續當白紙。我決定把這個題目當作影像處理或電腦視覺練習,試試自己寫程式解決,找樂子兼學新東西。
OpenCV 的影像識別能力強大,絕對能搞定這等小事,但有點殺雞用牛刀。理論上只需用相似性找出星空 Listen 畫面,餘下的便是例句字幕。找出近乎完全相同的圖片,應用不到深度學習、大模型,靠簡單演算法就能求解。
請 AI 當家教惡補,整理影像相似度比對的可能做法:
影像雜湊類 (Image Hashing)
將圖片轉化為一串「指紋(Fingerprint)」,透過比較指紋的**漢明距離(Hamming Distance)**判斷相似度,著名演算法有:- Average Hash (aHash):將圖片縮小並轉為灰度圖,計算像素平均值。大於平均值為 1,小於為 0。速度最快,但對亮度變化敏感。
- Perceptual Hash (pHash):使用**離散餘弦變換(DCT)**捕捉圖片的低頻資訊。是最健壯的雜湊算法,能抵抗一定程度的旋轉、縮放與亮度調整。
- Difference Hash (dHash):基於相鄰像素的差異來生成雜湊值。速度極快,且在辨識縮放圖片上效果極佳。
- Wavelet Hash (wHash):使用小波變換代替 DCT,在處理某些頻譜特徵時更為精確。
代表程式庫:Python ImageHash、C# CoenM.ImageHash
統計與結構指標類(Pixel-level & Structural Metrics)
直接在像素層次或局部區域進行數學統計,著名演算法有:- MSE (Mean Squared Error):計算兩張圖每個像素點的均方誤差。缺點是完全不符合人類視覺感知,例如平移一個像素 MSE 就會爆增。
- SSIM (Structural Similarity Index):從亮度、對比度、結構三個維度評估相似度,是目前公認最接近人類肉眼感受的傳統指標。
- Histogram Comparison:比較兩張圖的顏色分佈(直方圖),適用於顏色相近但內容不同的初篩。
代表框架:Python Scikit-image, OpenCV, MATLAB ssim
特徵點匹配類 (Feature-based Matching)
尋找圖片中的「關鍵點」(如角落、邊緣),並提取描述子(Descriptors),適合處理有旋轉、平移、遮擋或角度偏移的場景。- SIFT (Scale-Invariant Feature Transform):經典中的經典,對縮放與旋轉具有極強的抗性,但運算較慢且曾有專利限制。
- SURF (Speeded Up Robust Features):SIFT 的加速版。
- ORB (Oriented FAST and Rotated BRIEF):由 OpenCV 開發,目的在替代 SIFT,速度極快,非常適合行動裝置或即時偵測。
代表框架:OpenCV (支援 Python、C++,C# 有 EmguCV)
深度學習特徵向量類 (Deep Learning Embeddings)
現代主流技術,將圖片丟入神經網絡中提取高維度的特徵向量(Embedding),再計算兩向量間的餘弦相似度(Cosine Similarity)。- Pre-trained CNNs:使用 ResNet, VGG 或 EfficientNet 的倒數第二層輸出作為特徵。
- Siamese Networks:專門為了「比較」而設計的網絡結構,常用於人臉辨識,如 FaceNet。
- Vision Transformers (ViT) / CLIP:OpenAI 的 CLIP 模型可以將影像與文字映射到同一個空間,對於語義層級的相似度(例如:兩張都是「在草地上的狗」,但動作不同)辨識力極強。
常用框架:PyTorch/TensorFlow、Hugging Face Transformers (CLIP/ViT)、Milvus/Faiss。
| 類別 | 速度 | 強韌性(抗干擾) | 適用場景 | 推薦框架 |
|---|---|---|---|---|
| 影像雜湊 (pHash) | 極快 | 中(抗縮放/輕微變色) | 圖片去重、找出盜圖 | ImageHash |
| 結構指標 (SSIM) | 快 | 低(抗平移能力差) | 影像壓縮品質檢測 | Scikit-image |
| 特徵點 (ORB/SIFT) | 中 | 高(抗旋轉/遮擋) | 物體識別、全景拼接 | OpenCV |
| 深度學習 (CNN/CLIP) | 較慢 | 極高(理解圖片含義) | 以圖搜圖、複雜場景辨識 | PyTorch, Faiss |
我的這個超簡單應用,用影像雜湊就夠了,aHash、pHash、dHash 應該都行。延伸閱讀:Content Blockchain 的這篇 Testing different image hash functions 對各種影像雜湊有深入介紹與效能比較,有興趣深入者可參考。
.NET 做影像雜湊首推 Coenm.ImageHash,簡單幾行程式便能完成相似度比對:
var hashAlgorithm = new AverageHash();
// or one of the other available algorithms:
// var hashAlgorithm = new DifferenceHash();
// var hashAlgorithm = new PerceptualHash();
string filename = "image-file-path";
using var stream = File.OpenRead(filename);
// ....
ulong imageHash = hashAlgorithm.Hash(stream);
// calculate the two image hashes
ulong hash1 = hashAlgorithm.Hash(imageStream1);
ulong hash2 = hashAlgorithm.Hash(imageStream2);
double percentageImageSimilarity = CompareHash.Similarity(hash1, hash2);
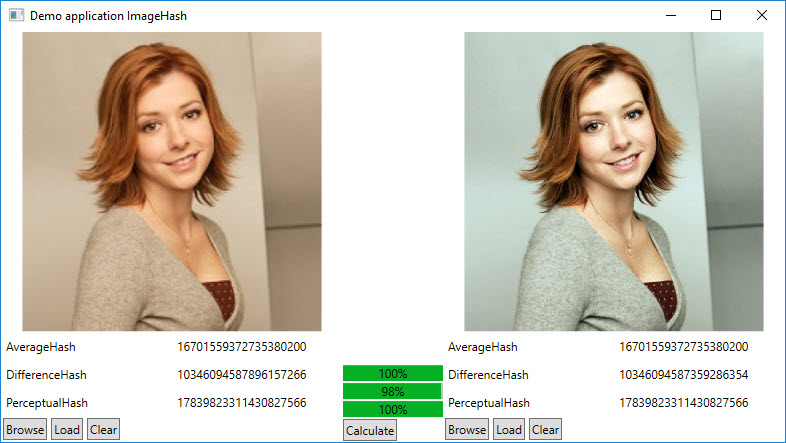
使用 Coenm.ImageHash 透過每秒畫面是否為 Listen 畫面,不難找到每次由 Listen 轉為非 List 畫面的時間點,下一張即為例句畫面(如文章第一張圖中的 [1], [2], [3])。為測試不同演算法,程式設計成可由參數決定使用 DifferenceHash、PerceptualHash 或是 AverageHash。
using System.Diagnostics;
using System.Security.Cryptography;
using CoenM.ImageHash;
using CoenM.ImageHash.HashAlgorithms;
var hashType = args.Length > 0 ? args[0] : "aHash";
var dHash = new DifferenceHash();
var pHash = new PerceptualHash();
var aHash = new AverageHash();
Func<string, System.IO.Stream> loadImage = path =>
{
return System.IO.File.OpenRead(path);
};
Func<Stream, ulong> hashAlgorithm = hashType switch
{
"dHash" => stream => dHash.Hash(stream),
"pHash" => stream => pHash.Hash(stream),
"aHash" => stream => aHash.Hash(stream),
_ => throw new ArgumentException("未知的 hash 類型"),
};
Func<ulong, Stream, double> compareImage = (baseHash, stream2) => CompareHash.Similarity(baseHash, hashAlgorithm(stream2));
// matchThreshold 可調整相似度靈敏度
const double matchThreshold = 90.0;
// 取星空 Listen 圖當比較基準
ulong baseHash = hashAlgorithm(loadImage("snapshots\\00:00:15.png"));
string cardsDir = "cards";
if (Directory.Exists(cardsDir)) Directory.Delete(cardsDir, recursive: true);
Directory.CreateDirectory(cardsDir);
var similarNames = new List<string>();
Console.WriteLine($"影像雜湊類型: {hashType}");
var results = new List<(string fileName, double similarity)>();
var sw = new Stopwatch();
sw.Start();
bool lastMatchResult = false;
foreach (var file in System.IO.Directory.GetFiles("snapshots")) // 2857 張
{
using var stream = loadImage(file);
double similarity = compareImage(baseHash, stream);
bool match = similarity >= matchThreshold;
if (lastMatchResult && !match ) // 上一張相同下一張不同,判定為字卡
{
File.Copy(file, Path.Combine(cardsDir, Path.GetFileName(file)), overwrite: true);
}
lastMatchResult = match;
results.Add((System.IO.Path.GetFileName(file), similarity));
}
sw.Stop();
Console.WriteLine($"執行時間: {sw.ElapsedMilliseconds:n0} ms");
var similarPics = results.Where(o => o.similarity > matchThreshold).ToArray();
Console.WriteLine($"相似圖片張數: {similarPics.Length}");
Func<IEnumerable<string>, string> computeMd5 = items =>
{
var list = string.Join("\t", items);
using var md5 = MD5.Create();
var hash = md5.ComputeHash(System.Text.Encoding.UTF8.GetBytes(list));
return BitConverter.ToString(hash).Replace("-", "").ToLowerInvariant();
};
Console.WriteLine("相似圖片列表 MD5: " + computeMd5(similarPics.Select(r => r.fileName)));
File.WriteAllLines($"{hashType}.csv", results.Select(r => $"{r.fileName},{r.similarity:f2}"));
var cardFileList = Directory.GetFiles("cards").Select(f => System.IO.Path.GetFileName(f));
Console.WriteLine("卡片圖片列表 MD5: " + computeMd5(cardFileList));
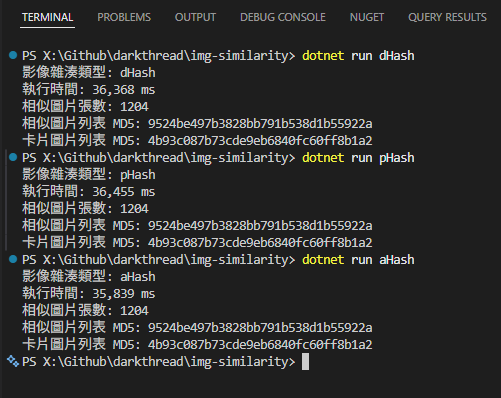
實測使用 DifferenceHash、PerceptualHash 或 AverageHash 都能正確識別所有 Listen 畫面並挑出 100 張例句卡片,這個案例中看不出三種演算法的速度差距,猜測是因為圖片偏大(超過 1MB),瓶頸出現在資料 IO,而在相關研究中,pHash 速度明顯較慢。
就醬,我也會用 .NET 比較圖片相似度囉~
Uses image hashing in .NET to automatically detect subtitle frames in a listening video by comparing frame similarity, avoiding manual work and heavy AI models while practicing classic image processing techniques.
Comments
# by JK.Wen
等下來試試應用到AI生成圖片的辨識, 兩張AI生成圖在不同背景與姿勢下的臉部比較, 不知是否可行?
# by Jeffrey
to JK. Wen, 這種複雜比對,很難從畫素相似性下手,非雜湊法可解法,建議走深度學習模型的路。