Docker 定期健康監測與自動重啟
| | | 0 | |
搞了幾個月的智慧插座監測程式吃 CPU Bug 問題,迎來一個壞消息和一個好消息。
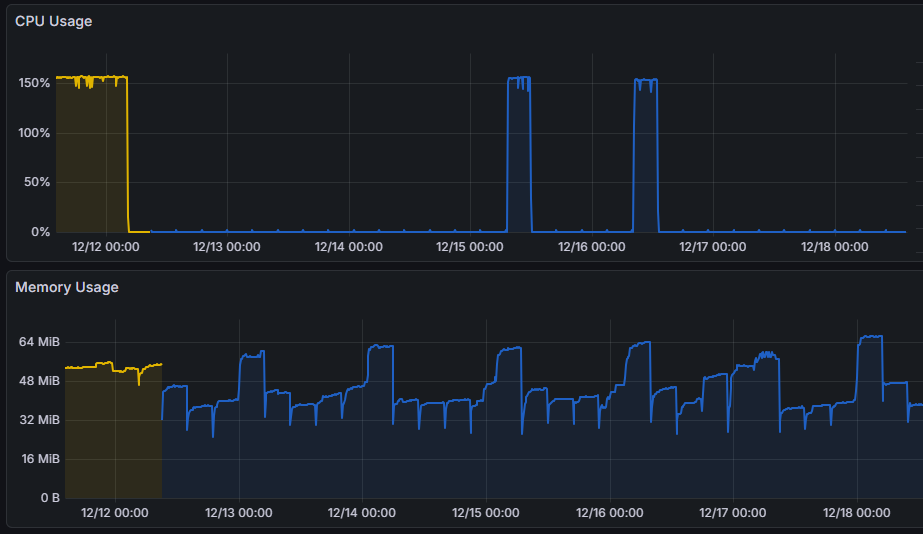
壞消息是上回定期自動重啟 Docker 容器鋸箭解決程式庫抓狂吃 CPU 的計劃失敗了!
如圖表所示,在 12/13 啟動每五小時自動重啟後,還是出現兩次 CPU 飆到 150%+ 的記錄,推測 TPLinkSmartDevice 程式庫比想像中還不穩定,有時重啟後沒多久便開始吃 CPU,如此 CPU 將一路飆高數小時直到下回重啟。
好消息是,是時侯來練習優雅的正統解法 - 用 Docker 的 HEALTHCHECK 機制監控 CPU 使用率,偵測到飆高時將容器狀態切換成 Unhealthy 並觸發強制重啟。
以下是在 docker-compose.yaml 設定 HEALTHCHECK 的簡單範例:
services:
my-web:
image: my-web:latest
container_name: my-web
restart: always
ports:
- "5678:3000"
environment:
- TZ=Asia/Taipei
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:3000/"] # -f 參數讓 curl 出錯時 ExitCode = 22
# 替代寫法,用 Shell 檢查,失敗時傳回 1
# test: ["CMD-SHELL", "curl -f http://localhost:3000/ || exit 1"]
interval: 10s # 多久檢查一次
timeout: 5s # 多久沒跑完算失敗
retries: 3 # 連續失敗幾次標示為不健康
在 healthcheck 區指定用 curl 測試,加上 -f 參數可在非 HTTP 200 時傳回非 0 Exit Code,協助 Docker 健康檢查機制判定系統是否健康,至於判斷標準有幾個參數可以調整,interval 是多久檢查一次(預設 30s)、timeout 是多久沒跑完算失敗(預設 30s)、retries 是連續失敗幾次標示為不健康(預設為 3)。
依據上述設定,代表當連續三次 curl 檢測失敗時,my-web 容器會被標示為 Unhealthy。但這只是標示,系統並不會自動重啟,一般常見做法是另外建一個 docker-autoheal 容器在容器不健康時觸發重啟。
如果不想多跑一個容器,有一種簡單粗暴的做法:既然 healthcheck 會定期執行我們的自訂 Shell 或程式,我們可以在特定條件下強制重啟程序,再靠 Docker 的自動重啟機制 (restart: unless-stopped 或 always) 原地復活。這有點把「健康檢查」搞成「自動監控與重啟腳本」,有失本意。另外也可能有一些後遺症,像是若程式有問題,每次一啟動就 CPU 破錶,容器將陷入無限重啟循環,第二則是這招會讓 Nginx/Traefik 等負載平衡機制自動下架 unhealthy 容器功能失效。總之,明白利弊得失,要不要用就看大家的評估。
services:
hs300-exporter:
image: hs300-exporter:latest
container_name: hs300-exporter
restart: unless-stopped
ports:
- "9300:9999"
environment:
- TZ=Asia/Taipei
- HS300_DeviceIP=192.168.50.80
healthcheck:
test:
- "CMD-SHELL"
- |
usage=$$(top -b -n 1 -p 1 | tail -1 | awk '$1 == "1" {print $$9}')
if [ -n "$$usage" ] && [ $$(awk -v u="$$usage" 'BEGIN {print (u > 90 ? 1 : 0)}') -eq 1 ]; then
echo "CPU Usage high: $$usage%. Sending SIGTERM..." > /proc/1/fd/1
kill -15 1
else
echo "CPU Usage: $$usage%" > /proc/1/fd/1
exit 0
fi
interval: 60s
以上這個版本包含一段咒語般的 Bash 腳本是 AI 提供的,前後反覆修正了幾次才成功。(小技巧是用 docker inspect --format='{{json .State.Health.Log}}' <container-name> | jq 可以查 test 腳本錯誤,得到 bash: -c: line 1: unexpected EOF while looking for matching ``''\n 或 "/bin/sh: 2: bc: not found\n/bin/sh: 2: [: -eq: unexpected operator\n" 之類的錯誤訊息)
中間還有一段小插曲:AI 最早給我的版本是用 ps aux 指令去抓 dotnet 所在 Process 的 %CPU,但這裡有個陷阱:ps 抓的 %CPU 是執行至今的平均 CPU 使用率,用 top 抓的才是即時數據。所以說,只靠 AI 不動腦有時沒法真的解決問題。延伸閱讀:【笨問題】Linux 查程序 CPU 使用率 - ps 與 top 的差異
這段腳本的原理如下:
第一行的 top -b -n 1 -p 1 可以以批次模式執行一次,並只查詢 PID 1 程序;tail -1 取顯示的最後一列,即 PID 1 的數值資料;awk '$1 == "1" { pring $9 }' 則是比對第一欄 PID == 1 時抓取第 9 欄 (%CPU) 數字。三者串在一起,即能抓到目前 Docker 核心程序的 CPU 使用率。
(若原本 Docker 映像檔未安裝 ps, top,可考慮為 Docker 映像檔加裝 CLI 工具)
if [ -n "$$usage" ] && [ $$(awk -v u="$$usage" 'BEGIN {print (u > 90 ? 1 : 0)}') -eq 1 ]; 檢查變數有值且用 awk 協助比較 $usage 變數是否大於 80 (註:Bash 只能處理整數,CPU% 可能為浮點數,借助 awk 解析)
若 u > 90 成立,echo 可在 docker inspect 的 Output 留下記錄,但只能看到最近五次,若要確保 docker compose logs 能查到完整記錄,需加上 > /proc/1/fd/1 將訊息導向 PID 1 的 stdout,kill -15 1 以 SIGTERM(15) 請程序優雅地自盡(註:-15 比 -9 (SIGKILL) 溫和,會給予 dotnet 程序存檔或關閉連線的時間),在容器內,PID 1 通常為主程式,殺掉 PID 1 會導致容器停止。
如果 CPU 正常,則 exit 0 回傳 0,對 Docker 而言,exit 0 代表「健康(Healthy)」。
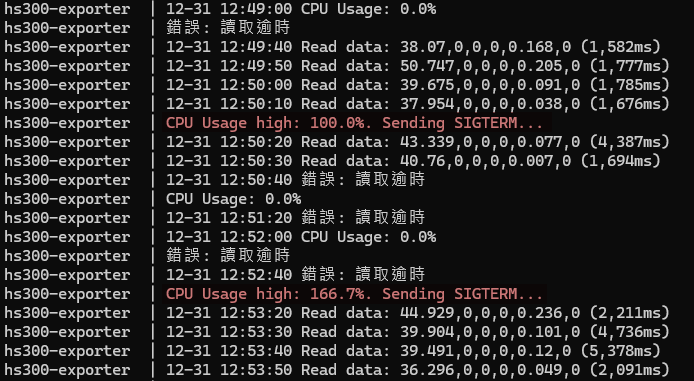
很幸運,從 12/30 晚上啟用至今,就出現多次 CPU 飆高完成重啟。
用 docker compose logs 有截錄到偵測 CPU 超過 90% 的記錄:
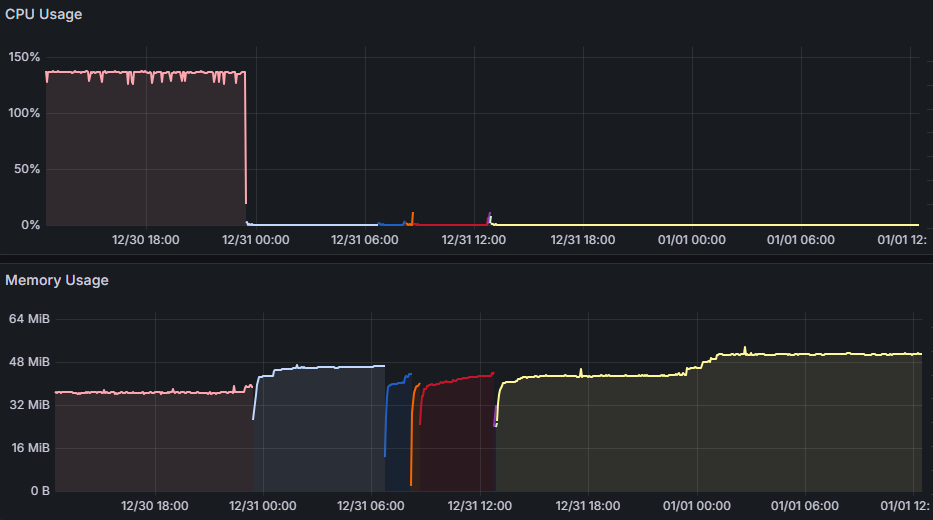
由 Grafana 圖表,健康檢查版在 12/30 午夜上線,之後出現多次 CPU 微幅突起、Memory 曲線換色且不連續,可驗證 CPU 衝高觸發的容器重啟確實有效。歷時兩個月的努力,終於磨出一套令人滿意的解決方案,也對 Docker 健康檢查機制有了基本認識,滿足。
Comments
Be the first to post a comment