使用 C# 呼叫 Chrome 批次產生網頁快照
 |  | 3 |  |
寫了一個依據 URL 清單連網頁存快照的小程式,感覺挺實用,稍加修改可衍生有趣的批次作業或自動化應用。放上 Github,方便將來有類似需求 clone 下來當起手式。
程式本身沒什麼了不起,網頁轉圖片靠 Headless Chrome,C# 操作 Chrome 是透過 Puppeteer Sharp,但程式裡夾雜一些實戰經驗,加減有參考價值。
- 教學範例常見的
await new BrowserFetcher().DownloadAsync(BrowserFetcher.DefaultRevision);寫法,在新位置第一次執行會從網路下載新版 Chromium,大小約 320MB,重新下載浪費頻寬與時間,遇到管制環境無法上網則要自己搬 .local-chromium 資料夾。既然手邊大部分電腦(包含管制環境主機)都會安裝 Chrome,我習慣讓 PuppeteerSharp 借已安裝的 Chrome,做法是在 LaunchAsync() 時指定 ExecutePath:
(註: Headless 建議設成 false 方便在執行期間觀察畫面或掌握進度。)browser = Puppeteer.LaunchAsync(new LaunchOptions { Headless = false, ExecutablePath = chromePath }).Result;
Chrome 執行檔路徑則可由 Registry 取得,例如:// get Chrome installed path from registry (Windows only) var path = Microsoft.Win32.Registry.GetValue( @"HKEY_CLASSES_ROOT\ChromeHTML\shell\open\command", null, null) as string; if (string.IsNullOrEmpty(path)) throw new ApplicationException("Chrome not installed"); var m = Regex.Match(path, "\"(?<p>.+?)\""); if (!m.Success) throw new ApplicationException($"Invalid Chrome path - {path}"); var chromePath = m.Groups["p"].Value; - 若無特殊需求,我傾向批次作業期間共用 Page 物件(對映到 Chrome 頁籤)連上不同 URL,重複利用資源。
- 範例程式裡取用 Page 常會寫成
var page = await browser.NewPageAsync();,其實 Chrome 啟動時已自帶一個空白頁,沒必要一定得開新的,所以我習慣用page = browser.PagesAsync().Result.First();取已開好的頁籤。 - 擷圖時機需等網頁載入完成,畫面才會完整。Puppeteer 提供 DOMContentLoaded、Load、Networkidle0、Networkidle2 四種事件 參考,DOMContentLoaded 發生在 HTML 載入解析後,Load 涵蓋靜態 CSS 及相依資源(圖片、字型... 等)載入,Networkidle 會等網路傳輸活動停止後 0.5 秒,可再涵蓋 Lazy Load 圖片、Video 等內容,Networkidle0 會等全部網路傳輸結束,Networkidle2 允許兩條連線仍在活動,可容忍網頁有一兩條 Long Polling 的設計。網頁百百種,偵測載入完成沒有一體適用的完美做法,要 100% 精準,最好的方法是檢查網頁特定元素,但如此需為每個網頁客製規則。若要取一個約略的通用規則,我選了常被採用的 Load + Networkidle2 組合 參考1、參考2,要求兩個事件都觸發過才算完成,程式可寫成:
var response = page.GoToAsync(job.Url, 30000, waitUntil: new WaitUntilNavigation[] { WaitUntilNavigation.Load, WaitUntilNavigation.Networkidle2, WaitUntilNavigation. }).GetAwaiter().GetResult(); - GoToAsync() 的結果有可能是 HTTP 401、404 也可能是 500,可檢查其傳回的 Response 物件,由 Status 屬性判斷狀態,從 TextAsync() 取得 HTML 內容(其中包含細節資訊)
- 儲存擷圖時,我想抓取整張網頁(包含完整捲軸長度),這部分我用 Math.max() 從 html, body 的 scrollHeight 取最大值。參考
綜合以上,我寫了一個類別封裝 Puppeteer Browser,提供兩個方法 Navigate() 及 TakeSnapshot():
using System;
using System.Collections.Generic;
using System.Linq;
using System.Threading.Tasks;
using PuppeteerSharp;
namespace UrlSnapshot
{
public class Job
{
public string Title;
public string Url;
public bool Pass;
public string Message;
}
public class Chrome : IDisposable
{
Browser browser = null;
Page page = null;
int width, height;
public Chrome(string chromePath, int width = 1024, int height = 768)
{
browser = Puppeteer.LaunchAsync(new LaunchOptions
{
Headless = false,
ExecutablePath = chromePath
}).Result;
page = browser.PagesAsync().Result.First();
this.width = width;
this.height = height;
}
public void Navigate(Job job)
{
try
{
page.SetViewportAsync(new ViewPortOptions
{
Width = width,
Height = height
}).Wait();
var response = page.GoToAsync(job.Url, 30000,
waitUntil: new WaitUntilNavigation[] {
WaitUntilNavigation.Load,
WaitUntilNavigation.Networkidle2
}).GetAwaiter().GetResult();
job.Pass = response.Status == System.Net.HttpStatusCode.OK;
if (!job.Pass)
{
job.Message = $"** {response.StatusText} **\n{response.TextAsync().Result}";
}
}
catch (Exception ex)
{
job.Pass = false;
job.Message = ex.Message;
}
}
public void TakeSnapshot(string path)
{
var h = Convert.ToInt32((float)page.EvaluateExpressionAsync(
@"Math.max(document.body.scrollHeight, document.documentElement.scrollHeight)").Result);
var w = Convert.ToInt32((float)page.EvaluateExpressionAsync(
@"document.body.getBoundingClientRect().width").Result);
page.SetViewportAsync(new ViewPortOptions
{
Width = w,
Height = h
}).Wait();
page.ScreenshotAsync(path).GetAwaiter().GetResult();
}
public void Dispose()
{
if (page != null) page.Dispose();
if (browser != null) browser.Dispose();
}
}
}
主程式部分則簡單讀入以逗號分隔名稱跟 URL 的文字清單,逐一連到各 URL,若成功則擷取畫面存檔,失敗則將錯誤訊息存成文字檔:
using System.Text.RegularExpressions;
using UrlSnapshot;
try
{
if (!args.Any()) throw new ApplicationException("url list filepath required");
var urlList = File.ReadAllLines(args[0])
.Where(line => !string.IsNullOrEmpty(line))
.Select(line =>
{
if (line.StartsWith('#')) return null;
var p = line.Split(',', '\t');
if (p.Length != 2)
throw new ApplicationException($"invalid data: {line} {p.Length}");
return new Job { Title = p[0], Url = p[1] };
}).Where(o => o != null).ToArray();
// get Chrome installed path from registry (Windows only)
var path = Microsoft.Win32.Registry.GetValue(
@"HKEY_CLASSES_ROOT\ChromeHTML\shell\open\command", null, null) as string;
if (string.IsNullOrEmpty(path))
throw new ApplicationException("Chrome not installed");
var m = Regex.Match(path, "\"(?<p>.+?)\"");
if (!m.Success)
throw new ApplicationException($"Invalid Chrome path - {path}");
var chromePath = m.Groups["p"].Value;
// prepare result folder, use date time as folder name
var resultFolder = Path.Combine(".", "Results", DateTime.Now.ToString("MMdd-HHmm"));
Directory.CreateDirectory(resultFolder);
using (var browser = new Chrome(chromePath))
{
foreach (var job in urlList)
{
browser.Navigate(job);
if (job.Pass)
browser.TakeSnapshot(Path.Combine(resultFolder, job.Title + ".png"));
else
File.WriteAllText(Path.Combine(resultFolder, job.Title + ".txt"), job.Message);
Console.WriteLine($"{(job.Pass ? "SUCC" : "FAIL")} {job.Url}");
}
}
}
catch (Exception ex)
{
Console.ForegroundColor = ConsoleColor.Red;
Console.WriteLine($"ERROR - {ex.Message}");
Console.ForegroundColor = ConsoleColor.Magenta;
Console.WriteLine(ex.ToString());
Console.ResetColor();
return;
}
我準備了一個簡單的範例,測試兩個正常網頁、一個不存在網站、404、401、500 案例:
.NET 6,https://docs.microsoft.com/en-us/dotnet/core/whats-new/dotnet-6
Puppeteer Sharp,https://www.puppeteersharp.com/
NoServer,http://8.8.8.8
Example404,http://localhost/aspnet/examples/no-such-page.aspx
Example401,http://localhost/aspnet/examples/401.aspx
Example500,http://localhost/aspnet/examples/500.aspx
擷取結果如下,.NET 6 抓到完整捲軸的超長圖檔、Puppeteer Sharp 網頁長度較正常,8.8.8.8 / 401 / 404 / 500 則得到訊息文字檔:
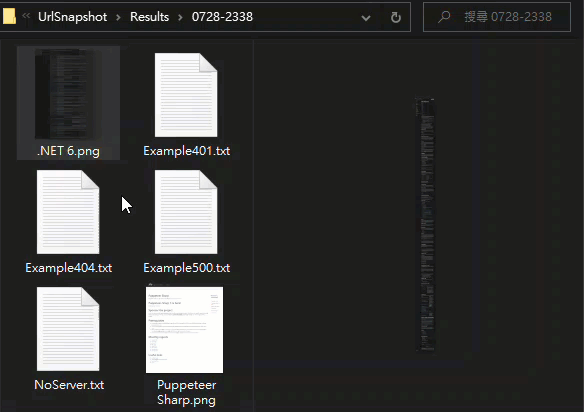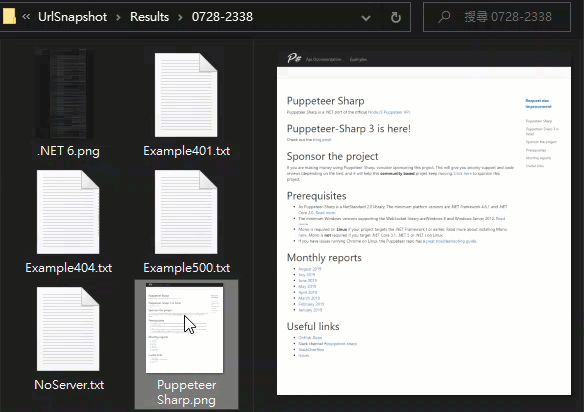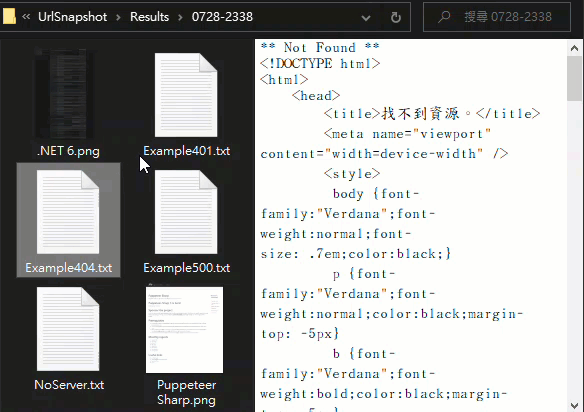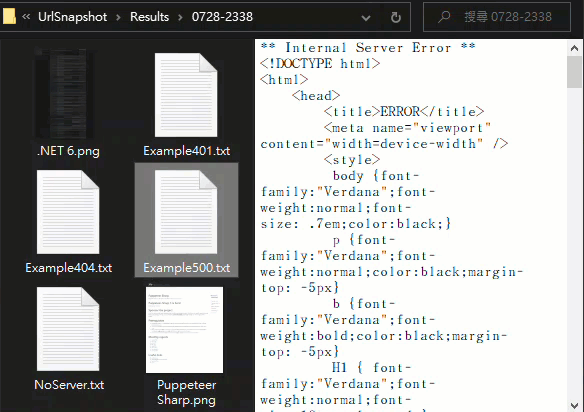
範例專案已上傳 Github,有需要的同學請自取。
Example of using PuppeteerSharp to take snapshots for web pages according to text list.
Comments
# by Rong
前陣子剛好有此需求參考了黑大的範例 後來發現Puppeteer Sharp作者Blog有提到Playwright 上網查詢評估後改用後者實作 黑大有興趣也可以參考看看 基本上語法相近畢竟開發團隊高度相關
# by Jeffrey
to Rong, 感謝分享,來找機會學習一下。
# by 羽山
感謝,ExecutablePath = chromePath 這段幫到忙^^