Unicode 罕用字冷知識
 |  | 3 |  |
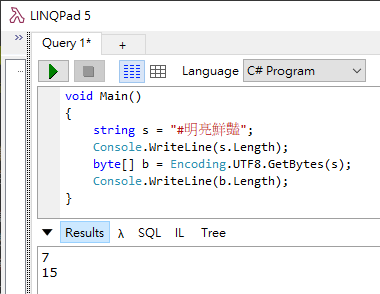
來個小測驗。請用大腦執行以下 C# ,說出 s.Legnth 及 b.Length 分別是多少?

void Main()
{
string s = "#明𠅙鮮𧰟";
Console.WriteLine(s.Length);
byte[] b = Encoding.UTF8.GetBytes(s);
Console.WriteLine(b.Length);
}
.NET 老鳥:簡單! s 有 5 個字元,所以 s.Length 是 5;UTF8 的話,英數字長度 1,中文 3,所以 b.Length = 1 + 3*4 = 13。
錯! 正確答案是 7 跟 15。
題目裡有陷阱 - s 包含了兩個 Unicode 罕用字 (Surrogate Pairs) - 「𠅙」、「𧰟」,Unicode 罕用字由兩個 char 組成(類似 BIG5 編碼用個 ANSI 字元組成一個中文字的概念),所以 "𠅙".Length == 2,而 Unicode 罕用字轉成 UTF-8 編碼時,會使用 4 個 Byte 表示。
這類問題用線上中文編碼解析工具看更清楚:

Surrogate Pairs 的特徵是在 UTF-16(UCS-2) 會以兩個雙位元組字元表示(共 4 Bytes),第一個字元介於 U+D800 ~ U+DBFF、第二個字元介於 U+DC00 ~ U+DFFF。觀察上圖的 (1) & (2),我們可以看到「𠅙」轉換成 UCS2 為 40 D8 59 DD,相當於 %uD840%uDD59、「𧰟」轉換成 5F D8 1F DC,相當於 %uD85F%udDC1F,符合上述的字元區間,確定是 Unicode 罕用字無誤。
因此 s.Length 原本為 5,因為𠅙𧰟是 Unicode 罕用字,長度再加 2 變成 7。至於𠅙𧰟二字的 UTF-8 編碼為 F0 A0 85 99 以及 F0 A7 B0 9F (上圖(3)),各為 4 Bytes 比正常中文字 3 Bytes 多一個,故 b.Length 也加 2 變成 15 。
另外一個值得注意的點是,Unicode 罕用字由兩個字元組成,轉成 BIG5 時會變成兩個問號 ASCII 3F (上圖(4)),也可當成實務上判斷 Unicode 罕用字的參考。
最後做個小結:
- Unicode 罕用字 (Surrogate Pairs) 由兩個字元組成,若出現在字串裡,長度要算 2。
- 一般中文字轉成 UTF-8 會佔三個 Bytes,但 Unicode 罕用字是四個 Bytes。
- Unicode 罕用字轉 BIG5 會變成 ?? (兩個問號)
【延伸閱讀】
Tips of calculate the length of strings containing Unicode surrogate pairs.
Comments
# by Huang
記得是微軟源自VB6時期的設計延用至今。
# by ChrisTorng
看了畫面,提個建議。您需要用黃底標示出各個字元,是否能直接看出每個字元對應的編碼,而不用再標示呢? 比如說每個字的編碼之間加上分隔符號,或者用表格模式,最上面的一個中文字元對齊下面所有編碼的位置。不清楚整串中文轉出來的編碼,跟各別中文字轉出來的各種編碼是否都一模一樣?
# by Jeffrey
to ChrisTorng, 很棒的建議! 找個時間來改版。