Oracle 自訂函式查詢加速密技–Scalar Subquery Caching
| | | 1 | |
在 SELECT 指令對欄位執行自訂函式行運算通常很傷效能,但實務上無法完全避免。查詢一萬筆資料代表要呼叫自訂函式一萬次,若函式包含資料表查詢,如同在迴圈裡跑 SQL,是典型的效能殺手,經驗裡也是許多複雜查詢逾時的主因。
見識到同事露了一手,簡單加幾個字元一口氣將內含自訂函式的 Oracle SELECT 加速數十倍! 瞠目結舌之餘,立馬實驗證明效果驚人,特筆記並分享如下。
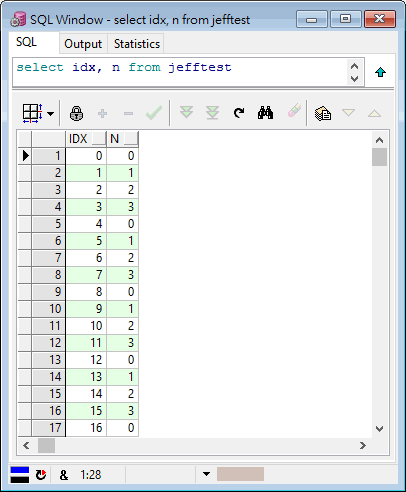
以下為實驗環境,JeffTest 資料表有 IDX, N 兩個 NUMBER 欄位,先塞入 256 筆資料,IDX 由 0 - 255,N 則是 IDX 除 4 的餘數,依序為 0, 1, 2, 3, 0, 1, 2, 3, ...。
我寫了一個無聊的自訂函式 FN_SQR 計算傳入數值的平方,為了讓效能差異明顯一點,還加了一個 dbms_lock.sleep(0.01) 延遲 0.01 秒,順便加上 dbms_output.put_line(n) 方便觀察執行次數:
create or replace function FN_SQR(n number) return number is
FunctionResult number;
begin FunctionResult := n * n;
dbms_lock.sleep(0.01);
dbms_output.put_line(n);
return(FunctionResult); end FN_SQR; 以下是兩個結果相同的查詢,第一個查詢是最直覺的寫法,SELECT 256 筆資料的 IDX 及 FN_SQR(N);第二個查詢動點手腳,將 FN_SQR(N) 改成子查詢 (SELECT FN_SQR(N) FROM DUAL),猜猜二者效能差多少?
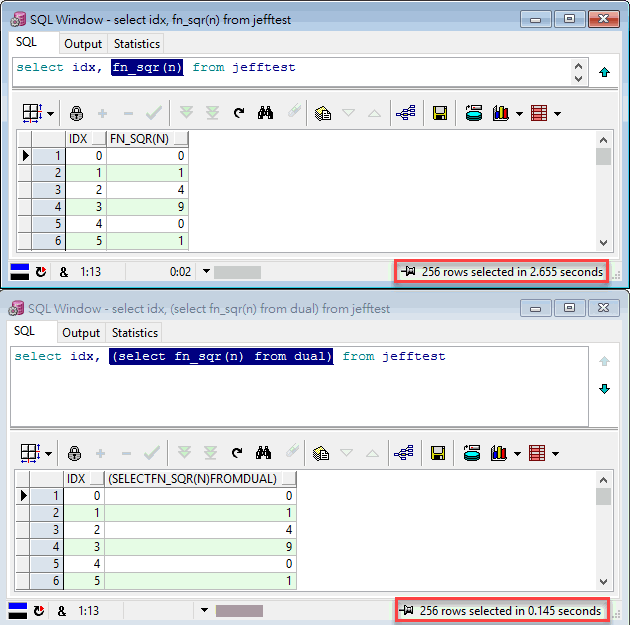
2.655 秒 vs 0.145 秒! 快了近 20 倍,為什麼?
看一下 dbms_output.put_line() 的輸出結果就知道差異何在,SELECT IDX, FN_SQR(N) 呼叫了 FN_SQR() 256 次,而 SELECT IDX, (SELECT FN_SQR(N) FROM DUAL) 只執行了四次,0,1,2,3 各一次,參數相同的函式呼叫可使用 Cache 結果,不必重複執行。
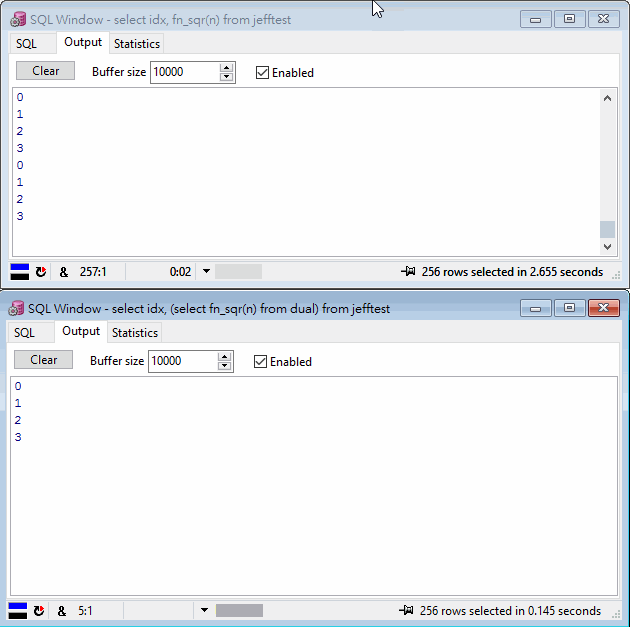
這裡的效能提升來自 Scalar Subquery Caching – Oracle 會為 SELECT 出現的 Scalar Subquery (只傳回單一值的子查詢) 在記憶體建立一個 Hashtable,整理不同參數與查詢結果的對應表。若參數欄位值先前出現過,即可直接由 Hashtable 取值不用重新計算。在這個案例中,N 欄位只有 0,1,2,3 四種變化,故只有前四筆資料需要計算,之後的 252 筆全由 Hashtable 取值。
換句話說,使用 SELECT 自訂函數(參數欄位) FROM DUAL 技巧將自訂函式呼叫包成子查詢,就可享受 Oracle Scalar Subquery Caching 的加速效果,資料筆數愈多、參數欄位值重複性愈高、自訂函式運算愈耗時,就愈能感受到明顯的效能提升。使用 Oracle 的同學們別錯過這招加速技。
Comments
# by binhu
原來是這樣子應用的啊,多謝分享