閒聊 - 用來跑 AI 模型的「八卡機」長什麼樣子?
 |  | 5 |  |
看了一些 AI 課程跟學術影片,常聽到幾個關鍵字:「八卡機」、A100...

我們都知道,機器學習仰賴大量 GPU 同步運算,像 ChatGPT 使用的 GPT-3.5 模型參數量便高達 1750 億個,每一回合運算次數都是千億等級,更別提所謂的訓練模型得嘗試成千上萬次尋找最佳參數組合,過程還得不斷調超參數(Hyperparameter)或改方法從頭再來一次,磨上數十上百回合。這種運算等級,即便是市面上買得到頂級 i9 電競主機,顯卡封頂裝到 4090,遇到中大型機器學習模型,只是杯水車薪...
要搞中大型模型的機器學習,用的肯定不是光華商場或 PCHome 買得到的個人主機,而不是圈內人,也很難有機會見識用來跑 AI 運算的設備長什麼樣子。這篇就用門外漢的角度,試著推測想像,增廣見聞。
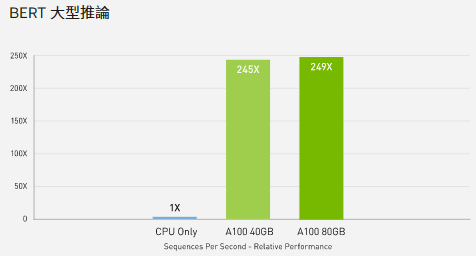
機器學習的硬體需求跟前幾年火熱的加密幣挖礦相近,因挖礦熱潮孕育發展的硬體設計,也能順勢應用在 AI 上。一般電腦玩家耳熟能詳的高端顯卡是 RTX 30X0 NVIDIA GeForce 30系列 甚至最新的 RTX 4090 (16384 CUDA Core, 2.52GHz, 24GB GDDR6X 記憶體 參考);而李宏毅老師影片提到的 A100 則是 Nvidia 針對 AI 運算的產品線,通常裝在資料中心的伺服器。A100 使用 Tensor Gore GPU,每個 GPU Clock 可完成一次 3x3 矩陣乘法或加法計算 (CUDA Core 每次 GPU Clock 只能完成一個單精度乘法或加法)。以 Google BERT 自然語言模型為例,A100 的運算能力是 CPU 的 249 倍。
補充 Bing Chat 對 CUDA Core 與 Tensor Core 差異的解釋:
- CUDA Core是NVIDIA推出的通用計算架構,適用於各種平行運算任務,每個CUDA Core可以在每個GPU時鐘週期執行一個單精度乘加運算。
- Tensor Core是NVIDIA專為深度學習和人工智慧工作負載而設計的專用處理器,每個Tensor Core可以在每個GPU時鐘週期執行一個矩陣乘加運算,這些運算是深度學習的核心計算函數。
- CUDA Core和Tensor Core的主要區別是,CUDA Core不會在精度上妥協,而Tensor Core則採用混合精度計算,以提高效能和節省記憶體。
A100 有兩種規格:

SXM 介面 圖片來源

PCIe 介面 圖片來源
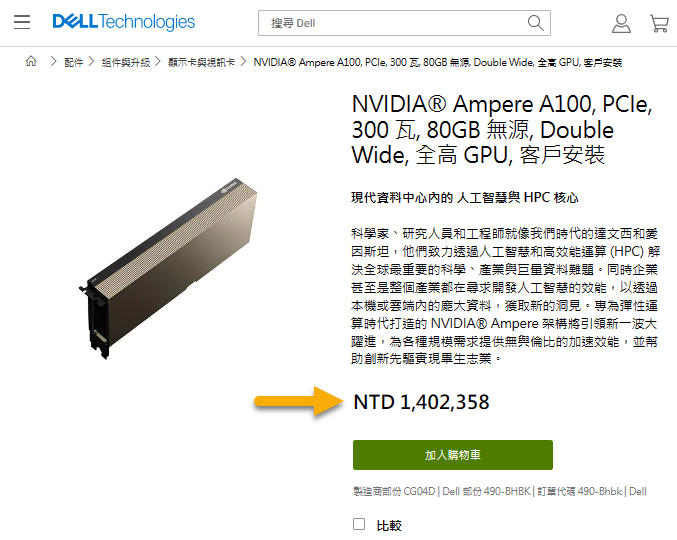
雖說是 PCIe 規格,但應該不會有人去光華商場帶一張回家插在個人電腦上,原因如下:(圖片為原廠官方定價,隨手查了實際售價,平均也在 50 萬以上)
那麼,傳說中的八卡機,一般指插滿八張 A100 的電腦主機,又長得像什麼樣子?
前陣子滑到一部有趣的開箱影片,網友拿到一台 EPYC 96 核雙 CPU、768GB DDR5 RAM、8 塊 A100 80G 的機架式主機,我們也得以近距離目睹所謂「八卡機」的真實樣貌:

八個 PCIe 5.0 插槽插滿八張 A100 80G:

機殼內全貌:

開機後會有一連串自我檢測,跑完到進入作業系統要花五分鐘,而運轉風扇噪音直逼飛機引擎:

四路電源供應器共 8000W,全力運轉相當於八台微波爐一起熱便當... 先不講電費跟會不會跳電,整台主機含零件總價約台幣 450 萬,沒人會買一台在家裡跑,看過就好,哈!
Comments
# by A網友
長見識了
# by Sysadmin
你應該看看DGX2.. 16張卡 全力運轉的耗電量是10~14KW.. 基本上跟一個商業用的 Pizza 烤箱差不多 我們都說 Datacenter 應該要放個輸送帶, 經過這些 DGX 中間 來烤 Pizza, 這樣除了可以供員工餐, 甚至還可以外賣
# by 小黑
有趣
# by Clay Cheng
爲什麽A100 80G就是傳説金卡?
# by Clay Cheng
抱歉,是黃金傳説。。。。。。太久不玩爐石戰記了