全文檢索筆記 – Lucent.Net (4) 詞庫校正
| | | 0 | |
體會過自動分詞(一元分詞、二元分詞)與詞庫分詞的特性差異,但是到目前為止有個問題一直被忽略,我測試用的詞庫直接下載自網路,內容是簡體中文,拆解精準度大有問題。
以 CWSharp 詞庫分詞為例,使用 Github 下載的 cwsharp.dawg 詞庫檔分析這句中文「競選活動已日趨白熱化,參選人莫不全力尋求廠商支援,其中以鄭少秋勝算最大。」,使用 Luke.net 查看分詞結果如下:
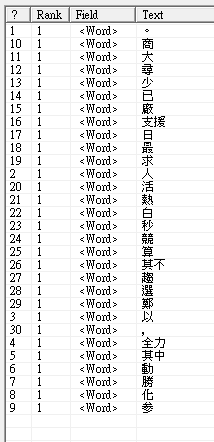
雖然還是能查到關鍵字,但分詞結果並不好,幾乎都拆成單一字元,跟一元分詞沒什麼兩樣。這意味詞庫命中率極低,其根本原因在於我們用的詞庫是簡體。將原文換成簡體 - 「竞选活动已日趋白热化,参选人莫不全力寻求厂商支持,其中以郑少秋胜算最大。」 再測一次即可看出差異。大部分的動名詞都被挑出來,連人名「鄭少秋」都能被識別成單一詞彙,這才是應有的結果:
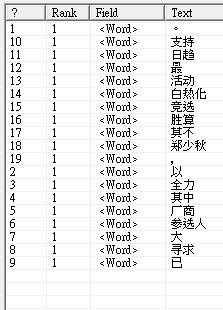
由此可知,直接用簡體字庫僅能命中簡繁體用字相同的詞彙,準確率有限,要有效解析繁體中文內容,詞庫必須轉成繁體,或更進一步改用繁體專屬詞庫。在此以 CWSharp 為例,示範如何轉換及製作詞庫。CWSharp 使用名為 DAWG(Directed Acyclic Word Graph) 的檔案格式保存詞庫(其查詢效率狂勝清單及二元樹,參考),DAWG 是由詞彙清單及字元頻率表轉換而成,Github 有簡體範例詞庫的原始檔 – cwsharp.dic, cwsharp.freq,以及轉換程式範例。
借用 NuGet 可得的微軟簡繁轉換元件 ChineseConverter 將簡體轉成繁體,就能轉換出繁體中文版詞庫檔 - cwsharp-tw.dawg。
static void BuildDawgFile()
{ var rootPath = ".\\DAWG"; var wordUtil = new WordDict(); //加载默认的词频 using (var sr = new StreamReader(rootPath + @"\cwsharp.freq", Encoding.UTF8))
{ string line = null;
while ((line = sr.ReadLine()) != null)
{ if (line == string.Empty) continue;
line = ChineseConverter.Convert(line, //簡體轉繁體 ChineseConversionDirection.SimplifiedToTraditional);
var array = line.Split(' '); wordUtil.Add(array[0], int.Parse(array[1])); }
}
//加载新的词典 using (var sr = new StreamReader(rootPath + @"\cwsharp.dic", Encoding.UTF8))
{ string line = null;
while ((line = sr.ReadLine()) != null)
{ if (line == string.Empty) continue;
line = ChineseConverter.Convert(line, //簡體轉繁體 ChineseConversionDirection.SimplifiedToTraditional);
wordUtil.Add(line);
}
}
//保存新的dawg文件 wordUtil.SaveTo(new FileStream(".\\cwsharp-tw.dawg", FileMode.Create));
}
改用 cwsharp-tw.dawg 重測,大部分詞彙就被正確識別出來了!

理論上,詞庫愈專業愈完整愈貼近檢索文章的用語習慣,建立索引及搜尋效能愈好。中研院有數萬甚至百萬筆等級的中文詞庫,堪稱最完整最權威的來源,不過它們不是開放資料,需考量授權可用性與成本。採 CC 3.0 授權的教育部國語辭典,則是另一個專業且可行的來源。需記住一點,詞庫分詞真要做到犀利精準,不可能單靠現成詞庫,看的是長期養成培育的功夫,持續補充新名詞(例如: 比特幣、聖結石),不斷學習及優化,是條不歸路。
考量飼養詞庫的成本,若全文檢索非網站的核心價值所在,文件數不多且對搜尋效能要求不高,二元分詞(索引及效率較一元分詞稍好)會是較省事的選擇。
Comments
Be the first to post a comment