【茶包射手日記】從 Oracle 改用 MSSQL 出現中文亂碼
 |  | 0 |  |
將某個老系統的資料來源由 Oracle 換成 MSSQL,遇到一個有意思的狀況。
在 Oracle 與 MSSQL 都有 Schema 完全相同的資料表,資料原本來自 Oracle NVARCHAR,改用 MSSQL 後,部分中文字元變成「?」。這個結果有點詭異,印象中 MSSQL 的 Unicode 支援比 Oracle 好,之前我處理的資料庫中文編碼問題幾乎都發生在 Oracle (有 Google 搜尋結果為憑),這回怎麼會 Oracle 編碼正常,換成 MSSQL 反而不行?
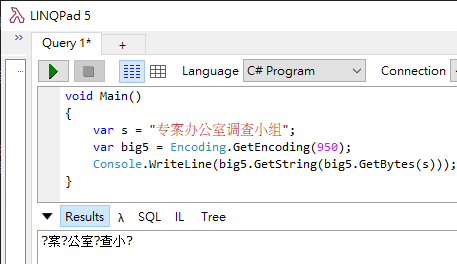
深入調查後,我才明白是怎麼一回事。原來這個老系統輸出規格仍採用 BIG5 編碼,而 NVARCHAR 資料欄位有些簡體字,例如:专案办公室调查小组,從 Unicode 硬轉 BIG5 時便會變成「?案?公室?查小?」。
那為什麼之前用 Oracle 沒這問題?答案藏在這篇茶包文 - Oracle 寫入 N'...' 簡體變繁體:
遇到 Unicode 簡體中文轉為 TRADITIONAL CHINESE_TAIWAN.ZHT16MSWIN950 編碼情境,Oracle 會試著將簡體字元對映成繁體字元,無法轉換者則不顯示。
聽起來是歪打正著呀,若內容包含 Unicode 字元,編碼應改用 UTF-8 或 Unicode 才是王道。不過,重構不是搞革命,維持介面一致是不可憾動的前題,還是乖乖想解法吧!
靈機一動,我想到 VB.NET 有個神奇的 Strings.StrConv,除了可以轉換全形半形,也能做簡繁字元轉換,而它跟 Oracle 轉換概念相同,只會處理可對映的字元,應可得到跟 Oracle 版程式相同的結果。
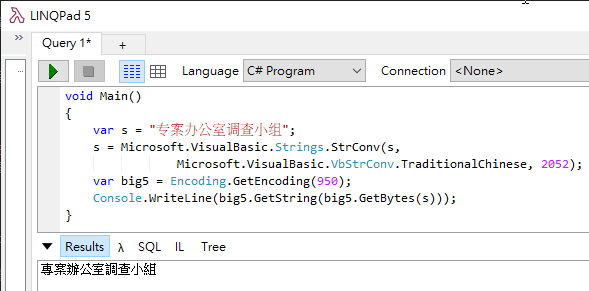
薑! 薑! 薑! 薑~~ 搞定收工。
2021-03-24 發現後遺症,「台」字會被強轉成「臺」,一個簡易 Workaround 是先用 big5.GetString(big5.GetBytes(raw)) != raw 檢測有 BIG5 不相容字元再轉換,但遇到繁體「台」字與其他簡體中文字元並存仍會有問題;第二個 Workaround 是將「臺」再換回「台」,但還有其他類似情境的字元。
A case of corrupted Chinese chars when migrating from Oracle to MSSQL.
Comments
Be the first to post a comment