Coding4Fun - BIG5 常用字真的很常用?次常用字比例有多低?PTT 八卦版常用字分析
 |  | 0 |  |
我有個自創 BIG5 快篩偵測法 - Bad Smell。
偵測編碼最快速有效的做法是檢查二進位資料是否包含無法轉換的 Byte[] 組合,但較頭痛的問題是 BIG5 繁體中文與 GB2312 簡體中文、Shift JIS 日文等泛 ANSI 類編碼,有許多字碼在三種編碼都能對映效字元。因此若只是單純用 Encoding.GetEncoding(950) 轉換 GB2312/Shift JIS 檔案,可能因大部分 byte[] 都可映對到有效繁體字碼區而誤判成 BIG5。
BIG5 有區分常用字區 A140 - C67E (5401 個)、次常用字區 C940 - F9D5 (7652 個) 參考,這些簡體中文或日文漢字很一定比例被映對成次常用字,導致次常用字出現的機率遠高於正常繁體文章的平均值。基於這個原理,我發明了 ( (無效字元*3 + 次常用字) / 總字元數 ) Bad Smell 指數實現簡易快篩。做法沒什麼學術根據,也存在誤判機率,但實務上可配合資料型態調整指數門檻,使用至今,準確率也很讓人滿意。
前陣子跟讀者討論到「以次常用字作為判斷依據」的合理性,追根究底,設定 Bad Smell 指數 < 0.1 是基於「次常用字在正常文章中必須小於總字數 10%」之類的假設,此一假設是否成真?好問題。
寫個程式來玩看看吧。
不同性質文章常出現的字不同,我打算寫支程式可以統計常用字及次常用字使用狀況、出現次數,並產生統計圖表。有了這種工具,未來只需從實際要處理的資料取樣進行分析,就知次常用字所佔比例,做為設定門檻的參考。
為了趣味起見,我找到一份有趣的繁體中文資料集 - PTT 中文語料,包含 PTT 八卦版於 2015 年至 2017 年 6 月的文章,以 QA 格式呈現,共有 77 萬筆,近 1,800 萬字。
程式範例如下,沒什麼大學問,就一些字串處理、用 Dictionary/LINQ 統計,中間使用 Parallel.ForEach() 平行處理 77 萬條 QA,最後用上前幾天介紹的 ScottPlot 畫 TOP 50 長條圖跟熱圖(Heatmap),很久沒有寫娛樂用 C# 程式,藉這次機會暖身恢復手感。
using System.Diagnostics;
using System.Text;
using System.Text.Encodings.Web;
using System.Text.Json;
using System.Text.Unicode;
using ScottPlot;
using ScottPlot.TickGenerators;
Encoding.RegisterProvider(CodePagesEncodingProvider.Instance);
Encoding big5 = Encoding.GetEncoding("big5");
var counters = new Dictionary<string, int>();
var charMap = new Dictionary<string, string>();
string charMapJsonPath = "charMap.json";
if (!File.Exists(charMapJsonPath))
{
// BIG5 字集範圍
var ranges = new[] {
(0xa140, 0xa3e0),
(0xa440, 0xc67e),
(0xc940, 0xf9d5)
};
foreach (var range in ranges)
{
for (int i = range.Item1; i <= range.Item2; i++)
{
var lo = (byte)(i & 0xff);
var hi = (byte)(i >> 8);
if (lo < 0x40 || lo >= 0x80 && lo < 0xa0 || (lo & 0xf) == 0xf) continue;
if (lo == 0x7e || lo == 0xa0 || lo == 0xfe) continue;
if (i >= 0xa3c0 && i <= 0xa3e0) continue;
var ch = big5.GetString(new byte[] { hi, lo });
if (!counters.ContainsKey(ch))
{
counters.Add(ch, i);
}
else
{
Console.WriteLine($"一字多碼 [{ch}]: {i:X4},{counters[ch]:X4}");
counters[ch] = i;
}
charMap[i.ToString("X4")] = ch;
}
}
var jsonOpt = new JsonSerializerOptions
{
WriteIndented = true,
Encoder = JavaScriptEncoder.Create(UnicodeRanges.All)
};
File.WriteAllText(charMapJsonPath, JsonSerializer.Serialize(charMap, jsonOpt));
counters.ToList().ForEach(kv => counters[kv.Key] = 0);
}
else {
charMap = JsonSerializer.Deserialize<Dictionary<string, string>>(File.ReadAllText(charMapJsonPath))!;
foreach (var kv in charMap) counters[kv.Value] = 0;
}
var sw = new Stopwatch();
sw.Start();
Parallel.ForEach(File.ReadAllLines("Gossiping-QA-Dataset-2_0.csv", Encoding.UTF8), line =>
{
for (var i = 0; i < line.Length; i++)
{
var ch = line.Substring(i, 1);
if (counters.ContainsKey(ch))
{
lock (counters)
{
counters[ch]++;
}
}
}
});
sw.Stop();
Console.WriteLine($"Elapsed: {sw.ElapsedMilliseconds}ms");
var csv = new StringBuilder();
csv.AppendLine("Catg,Code,Char,Count");
// 0xa4 ~ 0xc6 = 0x22, 0xc9 ~ 0xf9 = 0x31, 0x40 ~ 0xff = 0xc0
var heatData = new double[0x22 + 0x31 + 1, 0xc0];
Func<string, string> GetGroup = code =>
{
if (code.CompareTo("A440") >= 0 && code.CompareTo("C67E") <= 0) return "常用字";
if (code.CompareTo("C940") >= 0 && code.CompareTo("F9D5") <= 0) return "次常用字";
return string.Empty;
};
Dictionary<string, List<(string ch, int count)>> groupStats = new() {
{ "常用字", new() },
{ "次常用字", new() }
};
foreach (var code in charMap.Keys)
{
var catg = GetGroup(code);
if (string.IsNullOrEmpty(catg)) continue;
int y = catg == "常用字" ?
(int)(Convert.ToInt32(code[..2], 16) - 0xa4) :
(int)(Convert.ToInt32(code[..2], 16) - 0xc9 + 0x22 + 1);
int x = (int)(Convert.ToInt32(code[2..], 16) - 0x40);
var ch = charMap[code];
var count = counters[ch];
groupStats[catg].Add((ch, count));
heatData[y, x] = count == 0 ? 0 : Math.Log10(count); // Logarithmic Scale
csv.AppendLine($"{catg},{code},{ch},{count}");
}
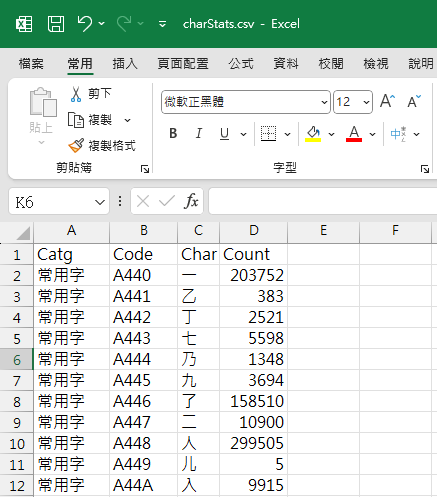
File.WriteAllText("charStats.csv", csv.ToString());
// 常用字次常用字數統計
var common = groupStats["常用字"].ToDictionary(o => o.ch, o => o.count);
var rare = groupStats["次常用字"].ToDictionary(o => o.ch, o => o.count);
Console.WriteLine($"常用字:{common.Count():n0}個 {common.Values.Sum():n0}次");
Console.WriteLine($"次常用字:{rare.Count():n0}個 {rare.Values.Sum():n0}次");
// 前 50 常用字
ScottPlot.Plot myPlot = new();
var data = common.OrderByDescending(kv => kv.Value).Take(50).ToList();
myPlot.Add.Bars(data.Select(kv => (double)kv.Value).ToArray());
int idx = 0;
var ticks = data.Select(kv => new Tick(idx++, kv.Key)).ToArray();
myPlot.Axes.Bottom.TickGenerator = new ScottPlot.TickGenerators.NumericManual(ticks);
myPlot.Axes.Bottom.TickLabelStyle.FontName = "PMingLiU";
myPlot.SavePng("common.png", 720, 250);
// 次常用字
myPlot = new();
data = rare.OrderByDescending(kv => kv.Value).Take(50).ToList();
myPlot.Add.Bars(data.Select(kv => (double)kv.Value).ToArray());
idx = 0;
ticks = data.Select(kv => new Tick(idx++, kv.Key)).ToArray();
myPlot.Axes.Bottom.TickGenerator = new ScottPlot.TickGenerators.NumericManual(ticks);
myPlot.Axes.Bottom.TickLabelStyle.FontName = "PMingLiU";
myPlot.SavePng("rare.png", 720, 250);
// 熱圖
myPlot = new();
// 分隔線
for (int x = 0x40; x <= 0xff; x++) heatData[0x22, x - 0x40] = 1;
var hm = myPlot.Add.Heatmap(heatData);
hm.Colormap = new ScottPlot.Colormaps.Turbo();
myPlot.Add.ColorBar(hm);
myPlot.Axes.Bottom.TickGenerator = new ScottPlot.TickGenerators.NumericManual(
new[] {
new Tick(0x00, "40"), new Tick(0x10, "50"), new Tick(0x20, "60"), new Tick(0x30, "70"),
new Tick(0x40, "80"), new Tick(0x50, "90"), new Tick(0x60, "A0"), new Tick(0x70, "B0"),
new Tick(0x80, "C0"), new Tick(0x90, "D0"), new Tick(0xa0, "E0"), new Tick(0xb0, "F0")
}
);
myPlot.Axes.Left.TickGenerator = new ScottPlot.TickGenerators.NumericManual(
new[] {
new Tick(0x54, "A4"), new Tick(0x32, "C6"), new Tick(0x2f, "C9"), new Tick(0x0, "F9")
}
);
myPlot.SavePng("heatmap.png", 720, 320);
用 ScottPlot 畫圖而非 Matplotlib,有印證上回所說,在查找資料及 AI 提示會吃點虧(Github Copliot 給的 ScottPlot 寫法幾乎都是錯的),所幸 ScottPlot 的官方文件挺完整,再加上靠經驗跟直覺推敲,都有找出程式的寫法。
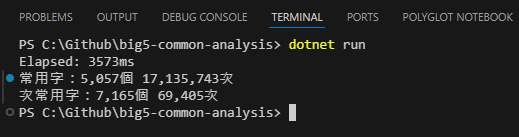
執行結果如下,60MB 77 萬筆中文 QA 只花了 3 秒處理完,整個 PTT 中文語料庫共用到 5,075 個常用中文字,出現 171 萬次,次常用字則是 7165 個,出現 6 萬 9 千多次。因此在八卦版次常用字的比例約為 69405 / (17135743 + 69405) = 0.4% 大約千分之四 (註:總字數不計入英數字符號),但跟擲硬幣一樣,樣本愈大才會愈接近這個分布。
程式會將結果存成 CSV,方便進階應用。
接下來是有趣的統計,猜猜八卦版最常用的常用字跟次常用字前 50 名是哪些?
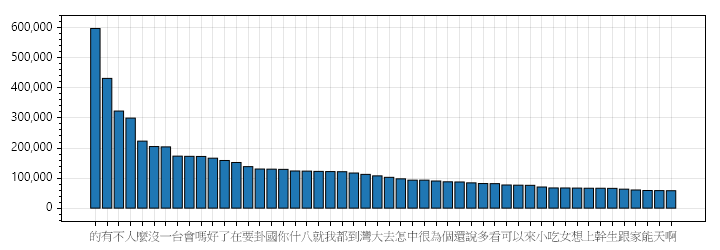
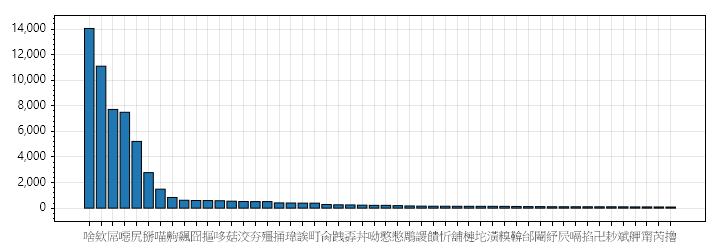
常用字組第一名由「的」稱霸(近 60 萬次)無人異議,其餘的字都是生活口語常用字,上榜不意外。
下個題目更有趣,那被狂用的次常用字又是哪些?前十名分別是 啥、欸、屌、噁、尻、掰、喵(貓派的勝利)、齁、飆、囧。
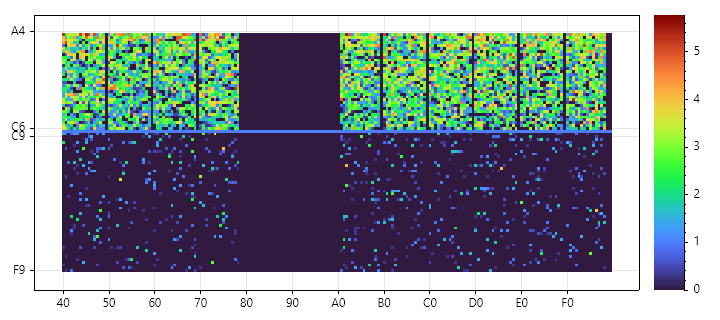
最後,雖然用想的就知道會怎麼分佈,我還是畫了人生第一張熱圖:(由於數值範圍從 60 萬到個位數,我將次數改為對數尺度 Logarithmic Scale提高圖表可讀性,1000 變成 3、10 萬轉成 5)
伸展完畢。
An efficient method for detecting BIG5 encoding by analyzing byte combinations and leveraging the characteristic frequency of less common characters in traditional Chinese text. This approach calculates a “Bad Smell” index to differentiate between BIG5 and other encodings like GB2312 or Shift JIS.
Comments
Be the first to post a comment